BigQuery と Snowflake と Redshift|DWH初導入の比較(コスト・スキル・既存クラウド別)
目次 クリックで開く
データドリブンな経営が叫ばれる中、企業のデータ基盤の中核を担うデータウェアハウス(DWH)の選定は、その後の開発工数とランニングコスト、そしてビジネスの意思決定スピードを左右する極めて重要なプロセスです。現在、市場を牽引しているのはGoogle BigQuery、Snowflake、Amazon Redshiftの3基盤ですが、これらは単なる「データの貯蔵庫」としての機能を超え、それぞれ全く異なる思想で設計されています。
本記事では、IT実務担当者や情報システム部門の選定者向けに、これら3大DWHの仕様、コスト構造、既存環境との親和性を徹底的に比較し、自社にとって最適な選択を行うための判断基準を提示します。
3大DWHの基本コンセプトと特徴
比較に入る前に、各プラットフォームがどのような設計思想に基づいているかを整理します。この「出自」の違いが、運用の手間に直結します。
Google BigQuery
Google Cloud(GCP)が提供する、完全サーバーレス型のDWHです。最大の特徴は「インフラ管理が一切不要」であることです。ユーザーはサーバーのプロビジョニングやストレージのサイジングを考える必要がなく、SQLを投げるだけで背後の膨大な計算リソースが動的に割り当てられます。Google検索で培われた圧倒的なスケーラビリティが強みです。
Snowflake
特定のクラウドベンダーに依存しない、クラウドネイティブなデータプラットフォームです。AWS、Azure、GCPのいずれの上でも稼働します。「ストレージとコンピューティング(計算リソース)の完全分離」をいち早く実現し、データ共有の容易さや、必要に応じて計算リソースを瞬時にスケールアップ・ダウン、あるいは停止させることができる柔軟性が高く評価されています。
Amazon Redshift
AWS(Amazon Web Services)が提供する、PostgreSQLベースのDWHです。AWSエコシステムとの親和性が極めて高く、S3やDynamoDB、Glueといったサービスと密接に連携します。かつてはインスタンスの管理が必要な「プロビジョニング型」が主流でしたが、現在は「Redshift Serverless」も登場し、管理負荷の軽減が進んでいます。
モダンなデータ基盤を構築する際、DWH選定と同時に重要となるのが、分析結果をビジネス現場へ戻す仕組みです。
高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
【比較表】主要スペック・課金体系・運用負荷
導入時に検討すべき主要な比較項目を一覧表にまとめました。
| 比較項目 | BigQuery | Snowflake | Amazon Redshift |
|---|---|---|---|
| 提供形態 | 完全サーバーレス(PaaS) | SaaS(マルチクラウド) | サーバーレス / インスタンス型 |
| 課金モデル | クエリのスキャン量 / 予約容量 | 計算時間(クレジット) + ストレージ | 時間単価(インスタンス / RPU) |
| 管理工数 | 極めて低い | 低い(自動メンテナンス) | 中程度(チューニングが必要な場合あり) |
| 得意な用途 | 大規模スキャン、アドホック分析 | エンタープライズ、マルチクラウド | AWS中心、定常的なバッチ処理 |
| SQL互換性 | GoogleSQL(標準SQL) | ANSI SQL(高い互換性) | PostgreSQLベース |
コスト構造の詳細:安く抑えるためのポイント
DWHの運用で最も「失敗」が起きやすいのがコストです。各社、公式サイトで料金シミュレーションを提供していますが、実務上の消費モデルを理解しておく必要があります。
BigQueryのコスト:スキャン量という「罠」
BigQueryのオンデマンド料金(1TBあたり約$6.25 ※2024年時点の東京リージョン参考値)は非常に明快です。しかし、SELECT * などのクエリで不必要に全ての列を読み込むと、一度のクエリで数千円〜数万円が飛ぶリスクがあります。これを防ぐには「パーティショニング(日付別分割)」と「クラスタリング」の適切な設定が不可欠です。また、定常的な利用が増えた場合は、Edition(Standard, Enterprise, Enterprise Plus)による予約容量課金への切り替えを検討します。
Snowflakeのコスト:クレジット消費と自動停止
Snowflakeは「ウェアハウス(計算リソース)」が稼働している時間に対してクレジットを消費します。最小サイズ(XS)で1時間1クレジット程度です。ここで重要なのは「オートサスペンド(自動停止)」機能です。クエリが終わった後にリソースを即座に停止させる設定にすれば、無駄な課金は発生しません。逆に、頻繁に少量のデータが入ってくる環境でウェアハウスを動かし続けると、コストが膨らみます。
Snowflake Pricing Options 公式ページ
Amazon Redshiftのコスト:予約インスタンスの活用
Redshift Serverless(RPU-時間単位)は、スパイクのある負荷に対して柔軟ですが、24時間365日一定の負荷がある場合は、プロビジョニング型で「リザーブドインスタンス(予約購入)」を利用する方が圧倒的に安くなります(最大75%程度の割引)。AWS GlueなどのETLサービスとの統合コストも合算して考える必要があります。
会計データや販売データなど、基幹システムからDWHへデータを集約する際、コスト削減の鍵は「増分更新(Incremental Load)」の設計にあります。
【完全版・第5回】freee会計の「経営可視化・高度連携」フェーズ。会計データを羅針盤に変えるBIとAPI連携術
導入・運用のためのスキルセット
ツールを選定する際、自社チームのスキルセットとの相性も無視できません。
- BigQuery: 独自のインフラ管理スキルはほぼ不要ですが、IAM(権限管理)の設計や、JSONなどのネストされたデータの扱いに慣れる必要があります。
- Snowflake: SQLの知識があれば即戦力として使えます。また、Pythonが書ければ「Snowpark」を利用してDWH内で機械学習モデルを動かすことも可能です。
- Redshift: PostgreSQLの運用経験があるエンジニアには馴染みやすいですが、VACUUM(不要領域の再利用)やディストリビューションキー(データの分散配置)といった、パフォーマンスチューニングのための専門知識を一定程度求められます。
既存クラウド環境別の最適解
「どれが良いか」は、現在利用しているクラウドプラットフォームに大きく依存します。
AWSをメインで利用している場合
第一候補はRedshiftです。VPC内でのセキュアな接続、S3からの高速ロード(COPYコマンド)など、インフラ構築のスピードが最も速くなります。ただし、部門横断で柔軟にデータ共有を行いたい、あるいはインフラ管理から完全に解放されたい場合は、AWS上でSnowflakeを稼働させる選択肢が非常に有力です。
GCPをメインで利用している場合
迷わずBigQueryを選択すべきです。Googleアナリティクス4(GA4)やSearch Consoleのデータ転送が標準でサポートされており、マーケティングデータの分析基盤としては他を圧倒する利便性があります。
マルチクラウド・SaaS中心の場合
特定のクラウドにロックインされたくない場合や、Salesforce、HubSpotなどのSaaSデータを統合したい場合は、Snowflakeが最適です。主要なETLツール(Fivetran, Trocco等)との親和性も非常に高く、コネクタが豊富に用意されています。
BigQueryは広告運用の自動化にも最適です。CAPI(コンバージョンAPI)との連携により、リアルタイムな広告最適化を実現できます。
広告×AIの真価を引き出す。CAPIとBigQueryで構築する「自動最適化」データアーキテクチャ
【実務手順】DWH導入の5ステップ
選定が終わった後の、導入から運用開始までのステップを解説します。
1. データソースの整理とETLツールの選定
基幹DB、SaaS、ログファイルなど、どこからデータを集めるかを整理します。自前でスクリプト(Python等)を書くか、マネージドETLサービス(Trocco, Fivetran, Dataflow等)を利用するかを決定します。初動を早めるならマネージドサービスを推奨します。
2. 権限設計とセキュリティポリシーの策定
「誰がどのデータを見られるか」を設計します。
- BigQuery: IAMロールとDatasetレベルの権限。
- Snowflake: ロールベースのアクセス制御(RBAC)。
- Redshift: 標準的なSQL権限管理(GRANT/REVOKE)。
3. データのモデリング(dbtの活用)
生データ(Raw Data)を直接分析するのは非効率です。dbt(data build tool)を活用し、SQLベースで変換処理(Transform)を行い、クリーンな「マート」を作成します。これにより、分析の再現性とコード管理が可能になります。
4. BIツール・リバースETLとの連携
Tableau、Looker、Looker Studio、Power BIなどのBIツールと接続します。また、分析結果をSalesforceやLINE、広告媒体に戻す「リバースETL」を導入することで、データが直接ビジネスアクションに繋がるようになります。
5. コスト監視アラートの設定
運用開始初日に必ず設定すべきなのが、予算アラートです。
- BigQuery: プロジェクトごとの1日のスキャン量制限。
- Snowflake: クレジット消費のクォータ設定と通知。
- Redshift Serverless: 最大RPU使用量の制限。
よくある失敗例とトラブルシューティング
「クエリ一発で数万円」の事故
BigQueryで、10TBあるログテーブルに対し SELECT * を実行してしまうケースです。
【対処法】: 必ず WHERE 句でパーティション列(日付等)を指定することを社内ルール化します。また、プレビュー機能を利用してスキャン量を確認する習慣を徹底させます。
データが更新されない(パイプラインの目詰まり)
ETLツールの接続エラーや、ソース側のスキーマ変更(列の追加・削除)により、DWHへのロードが止まるケースです。
【対処法】: Slack等へのエラー通知設定はもちろん、スキーマ変更に強い「スキーマドリフト」対応のETLツールを選定しておくか、dbtの source freshness チェックを導入します。
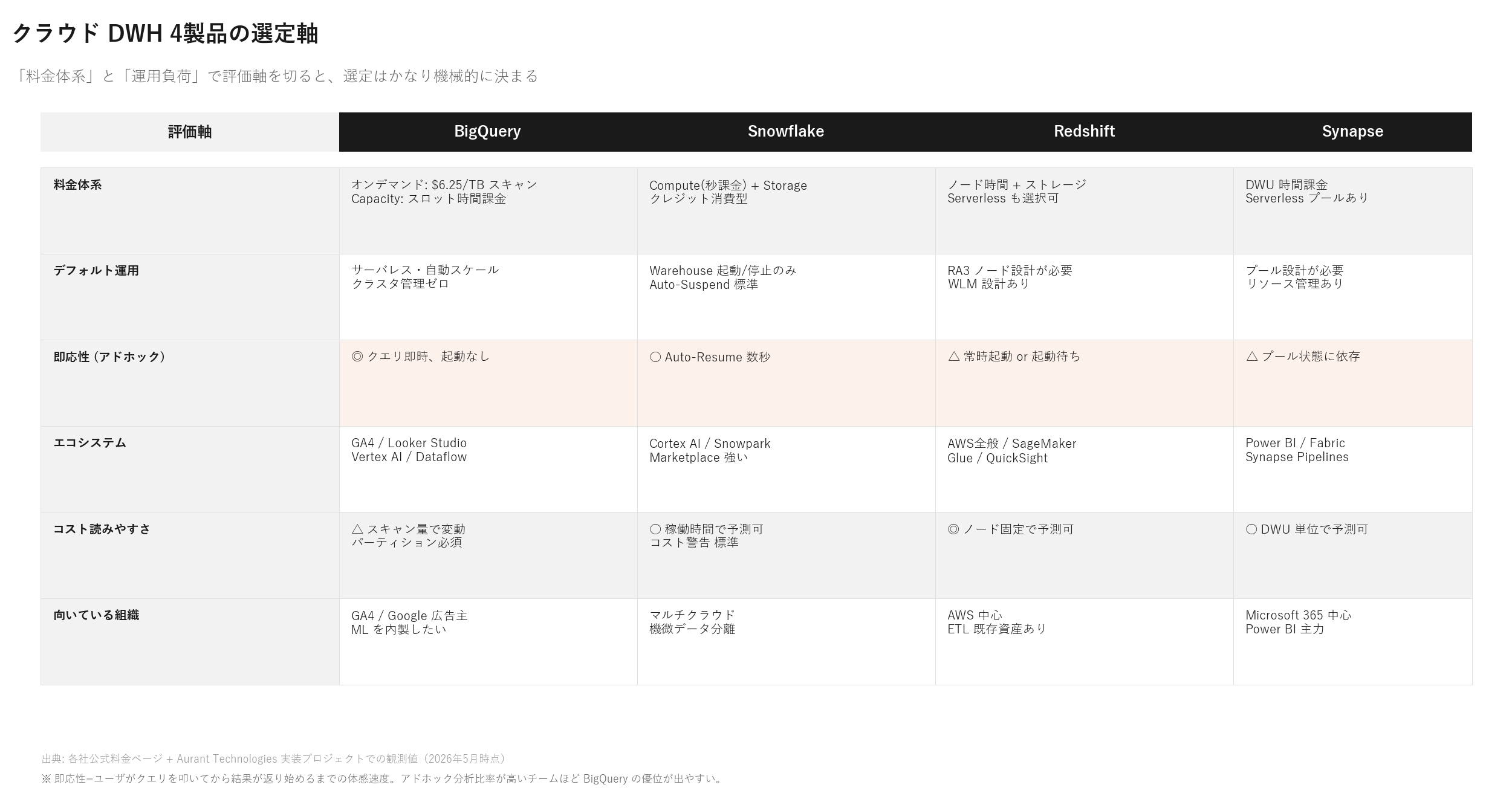
DWH 初導入で本当に重要な「7つの判断軸」
3製品の比較表だけでは決まらない、実プロジェクトで本当に効く判断軸を整理します。「機能」より「組織と運用の現実」が選定を分けます。
判断軸1:データ部門のスキルセット
- SQLのみ:BigQuery / Snowflake どちらでも対応可能
- Python + ETL の経験:Snowflake / Databricks も視野
- クラスター管理の経験:Redshift も選択肢に入る
- 0からの育成:BigQuery が学習コスト最小
判断軸2:データ量の成長予測
- 〜100GB(年):どれでも問題なし、コスト最優先で BigQuery
- 100GB〜1TB:BigQuery のオンデマンド課金が読みづらくなる、Snowflake / Slot 予約を検討
- 1TB〜100TB:Snowflake が予算管理しやすい
- 100TB超:Snowflake / Databricks のレイクハウス構成
判断軸3:BIツールの既存利用
- Looker Studio / Looker:BigQuery がネイティブ親和性
- Tableau:どのDWHでも対応可能
- Power BI:Snowflake / Synapse / Redshift が組み合わせやすい
- 独自BI構築:API・カスタマイズ性で Snowflake
判断軸4:データソースの偏り
- GA4・Google広告中心:BigQuery(標準連携あり、Data Transfer Service 無料)
- Salesforce 中心:Snowflake または BigQuery(Salesforce Data Cloud との Zero Copy 連携対応)
- Microsoft 365・Dynamics 365:Synapse / Fabric / Snowflake
- AWS のサービス中心:Redshift
判断軸5:データ共有・コラボレーション要件
- 他社とのデータ共有が頻繁:Snowflake Data Sharing が最強
- 組織内のみ共有:BigQuery Analytics Hub / Redshift Datashare
- 外部企業に分析機能を提供(SaaS):Snowflake Marketplace 経由
判断軸6:コンプライアンス・データレジデンシー要件
- 金融機関(FISC安全対策基準):3製品とも対応、国内データセンター選択必須
- 医療(3省2ガイドライン):Snowflake / Azure Synapse の対応実績多
- 個人情報の海外移転制限:データセンター選択を契約時に決める
判断軸7:マルチクラウド戦略
- シングルクラウド方針:そのクラウドのネイティブDWH(BigQuery / Redshift / Synapse)
- マルチクラウド方針:Snowflake / Databricks(クラウド非依存)
- パブリック→プライベートクラウド移行:Snowflake / Databricks のクラウド間移行容易性
「最初の1ヶ月」で何を実装すべきか(DWH スタートガイド)
DWHを契約しても、最初の1ヶ月で「何をやればいいか分からない」企業が多くいます。実プロジェクトで成功する最初の1ヶ月のロードマップを共有します。
Week 1:基盤設定とアクセス整備
- プロジェクト・ワークスペース作成
- 初期データセット・スキーマ作成(raw / staging / mart の3層を最初から)
- サービスアカウント・権限ロール設計(Reader / Writer / Admin)
- BIツールからの接続設定
Week 2:データソース1〜2本の取り込み
- 最重要データソース1本を取り込み(例:Salesforce Account / 商談データ)
- ETLツール(trocco / Fivetran)の設定
- 初期データ取り込み完了 + 増分転送スケジュール設定
- 取り込みデータの精度検証(行数・カラム数突合)
Week 3:データモデリング(dbt導入)
- dbt プロジェクトのセットアップ(GitHub または Bitbucket でバージョン管理)
- staging モデル(生データのクリーンアップ)を1〜2モデル作成
- mart モデル(分析用集計)を1モデル作成
- dbt run の日次スケジュール設定
Week 4:BIダッシュボード公開
- Looker Studio / Tableau での「経営層向け1枚ダッシュボード」作成
- 関連部門への共有設定(権限管理)
- 定期更新スケジュール(毎朝6時など)
- 運用ドキュメント作成
3製品それぞれの「実は知られていない落とし穴」
BigQuery の落とし穴
- SELECT * の罠:BigQueryは列指向のため、必要な列のみSELECTすることでコストが90%以上削減できる。`SELECT *` は禁止
- パーティション指定なしクエリの暴走:パーティションテーブルでもクエリ条件に日付指定がないと全件スキャン
- Storage 料金の見落とし:「クエリしてないから無料」と思っていると、データ量が増えるとストレージ料金がじわじわ増える
- Standard SQL vs Legacy SQL:古い記事の例文が Legacy SQL のことがあり、互換性問題に詰まる
Snowflake の落とし穴
- ウェアハウス停止忘れによる課金累積:自動停止設定を忘れると週末に走り続けて高額請求
- クエリ最適化のミス:Snowflakeは「データクラスタリング」がBigQueryと違う仕組み。初期設計が重要
- マイクロパーティション:自動管理だが、誤ったクラスタキー指定でパフォーマンス劣化
- Time Travel のストレージ追加:データ復元機能でストレージ容量が想定の倍に
Redshift の落とし穴
- VACUUM・ANALYZE の運用:定期的なメンテナンス処理が必要、忘れるとパフォーマンス劣化
- ノードサイズの読み違い:将来のデータ成長を見誤るとノード再構築コストが膨大
- Concurrency Scaling の課金:自動スケール機能を使うと意図せぬ追加課金
- Spectrum の料金:S3 のデータをクエリすると別途課金
業界特化型DWHの選択肢(補足)
3大DWH以外にも、特定用途に強い選択肢があります。
Databricks Lakehouse
- 機械学習・AI ワークロードと統合分析が必要なら最強
- Delta Lake で柔軟なスキーマ進化
- Notebook ベースのデータエンジニアリング
Microsoft Fabric / Azure Synapse
- Microsoft 365 / Power Platform との統合
- OneLake によるデータ統合
- Power BI とのネイティブ親和性
ClickHouse
- 高速ログ分析・ユーザー行動分析特化
- オンプレ / クラウドどちらでも
- ECやSaaS事業者で採用増
StarRocks / Apache Doris
- オープンソースDWH、コスト最優先の場合
- 自社運用前提・エンジニアリソース必要
関連ガイド・クラスター
- BigQuery 完全ガイド:Snowflake/Redshift比較・業界別導入・コスト最適化
- データ統合コストを下げるETLツール比較
- Google広告×BigQueryでデータ分析を自動化・高度化
- 【ピラー】BigQuery/モダンデータスタック完全ガイド
- Looker Studio 完全ガイド:Tableau/Notion連携
- kintone × BigQuery 連携完全ガイド
まとめ:自社にとっての「正解」の選び方
最後に、失敗しないための最終チェックリストを提示します。
- インフラ管理者を置けない:BigQuery 一択
- 分析者が多い、マルチクラウド環境である:Snowflake
- すでにAWSを使い倒しており、インフラ担当者がいる:Redshift
- Googleのマーケティングツールを多用している:BigQuery
- SQL以外の複雑な処理(Python等)もガシガシ行いたい:Snowflake(Snowpark利用)
DWHは一度導入すると移行のハードルが非常に高いため、初期の比較検討に十分な時間を割く価値があります。各ツールとも無料トライアルや無料枠が用意されていますので、まずはスモールスタートで実際の操作感と、自社のデータ量でのコスト感を計測することをお勧めします。
導入判断を左右する「ガバナンス」と「非エンジニアの活用」
DWHの選定において、スペックやクエリ単価と同じくらい重要なのが、導入後の運用フェーズにおける「データの統制(ガバナンス)」と「誰がデータを触れるか」というアクセシビリティです。技術的な優位性だけでなく、組織の文化に合わせた視点が必要です。
1. 権限管理とセキュリティの粒度
BigQueryはGoogleアカウント(Google Workspace)と統合されているため、社内ユーザーへの権限付与が非常にスムーズです。一方で、Snowflakeは「Role Based Access Control (RBAC)」が極めて強力で、複雑な組織構造を持つエンタープライズ企業において、特定の行や列だけを特定の部署に見せる、といった高度なセキュリティ制御をGUIベースで直感的に設定できる利点があります。
2. データの「鮮度」と「民主化」
分析者がSQLをバリバリ書く組織ならどのツールも強力ですが、マーケターや営業企画など非エンジニアが直接データを活用する場合、Snowflakeの「データ共有(Data Sharing)」機能は、データのコピーを作らずに外部パートナーと安全に連携できるため、ビジネスのスピードアップに寄与します。対してBigQueryはLooker Studioとの親和性が極めて高く、低コストで全社的なダッシュボードを構築するのに向いています。
高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
【運用比較】エンジニア確保と周辺エコシステム
ツールの料金以外に発生する「学習コスト」と「エンジニアの採用難易度」についても考慮すべきです。
| 補足項目 | BigQuery | Snowflake | Amazon Redshift |
|---|---|---|---|
| 学習のしやすさ | 高い(SQLのみで完結) | 標準的(機能が豊富) | 中程度(設定項目が多い) |
| エコシステムの広さ | GCP、Google広告、GA4 | 主要全クラウド、各種SaaS | AWS、BIツール全般 |
| 主な懸念点 | 複雑なストアドプロシージャ | 多機能ゆえの初期設計の迷い | ノード管理のオーバーヘッド |
より深い理解のためのリソース
各社の最新アップデートや実務上のベストプラクティスは、公式ドキュメントおよび技術コミュニティで随時更新されています。特に、クラウドを跨いだデータ連携や基幹システムとの接続を検討されている方は、以下の公式ページをご参照ください。
また、データ基盤を構築した後の具体的なアプリケーション展開(LINE連携や広告最適化など)については、以下の関連記事が参考になります。
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
データ分析・BI
Looker Studio・Tableau・BigQueryを活用したBIダッシュボード構築から、データ基盤整備・KPI設計まで対応。経営判断をデータで支援します。