BigQuery 完全ガイド 2026:Snowflake/Redshift比較・業界別導入・コスト最適化・Claude/AI×BI
BigQuery導入で失敗したくない企業へ。データ分析とBI連携を成功させるための具体的な手順、事前準備、活用法、よくある課題解決策までを徹底解説します。
目次 クリックで開く
データ駆動型経営(データドリブン経営)の重要性が叫ばれる中、多くの企業がデータ基盤の核としてGoogle CloudのBigQueryを採用しています。しかし、単にデータを蓄積する箱として導入するだけでは、「コストばかりがかさみ、意思決定に寄与しない」という事態に陥りかねません。膨大なデータをミリ秒単位で処理し、正確なインサイトを導き出す「生きた基盤」を構築するには、基盤そのもののスペック以上に、周辺エコシステムとの連携、ガバナンス設計、そしてコスト最適化の戦略が不可欠です。
本記事では、技術選定の責任者やDX担当者がBigQuery導入において直面する「設計・コスト・運用」の壁を突破するための実務ガイドを提示します。公式の技術ドキュメントや最新の導入事例に基づき、10ステップの導入手順から、異常系への対応、BI連携の最適解までを15,000文字規模の密度で徹底解説します。
BigQuery導入の全体像と主要なメリット
BigQueryは、ペタバイト級のデータに対して超高速なクエリを実行できる、サーバーレスかつフルマネージドなデータウェアハウス(DWH)です。DWHとは、企業内の様々なシステムからデータを集約し、分析に特化して最適化したデータベースを指します。運用保守の工数を極限まで減らしながら、ビジネスの成長に合わせて柔軟にスケーラビリティを確保できる点が最大の特徴です。
データウェアハウスとしての基本性能と料金体系
BigQueryの料金体系は、主に「ストレージ料金」と「クエリ計算料金(分析料金)」の2階層で構成されています。この構造を理解することが、導入後の予算超過を防ぐ第一歩となります。
- ストレージ料金:保存されているデータ量に対して課金されます。
- アクティブ ストレージ:過去90日間で変更されたテーブルやパーティションが対象。月額約0.02/GB。</li>
<li><strong>長期保存ストレージ</strong>:90日間連続で変更がないテーブルが対象。料金はアクティブストレージの約半分(約0.01/GB)に自動で引き下げられます[1]。
- アクティブ ストレージ:過去90日間で変更されたテーブルやパーティションが対象。月額約0.02/GB。</li>
- 分析料金(計算料金):実行したクエリで処理されたデータ量に対して課金されます。
- オンデマンド料金:スキャンされたデータ1TBあたり$6.25。小規模利用や予測が難しいワークロードに適しています。
- BigQuery エディション:処理能力(スロット)を予約する定額制に近いモデル。「Standard」「Enterprise」「Enterprise Plus」の3段階があり、大規模かつ安定したワークロードでのコスト予測に優れています。
【公式出典】BigQuery の料金 — Google Cloud
他社DWH(Snowflake / Redshift)との実務的な違い
実務選定において、BigQueryが他の主要DWH(Snowflake、Amazon Redshift)と最も異なるのは、「コンピューティングとストレージの完全分離」による運用負荷の低さと、Googleエコシステム(特にGA4やGoogle広告)との圧倒的な親和性です。
| 比較項目 | Google BigQuery | Snowflake | Amazon Redshift |
|---|---|---|---|
| アーキテクチャ | サーバーレス(完全分離型) | マルチクラウド(完全分離型) | ノードベース(RA3で分離可能) |
| 運用負荷 | 極めて低い(インデックス不要) | 低い(自動管理機能が豊富) | 中〜高(バキュームや設計が必要) |
| 料金モデル | スキャン量 or スロット予約 | クレジット(コンピュート時間) | 実行時間 or サーバーレス |
| 得意とするデータ | GA4、広告、ログなどの大規模データ | 構造化・半構造化データの共有 | AWSエコシステム内の基幹系データ |
| 機械学習(ML) | BigQuery ML(SQLで完結) | Snowpark(Python/Java) | Redshift ML(Amazon SageMaker連携) |
特にデジタルマーケティング領域において、Googleアナリティクス4(GA4)の非集計データを直接エクスポートできる点は、BigQueryを選ぶ決定的な理由となります。これにより、広告配信の最適化や、Webサイト上のユーザー行動に基づく精緻なLTV(顧客生涯価値)分析が可能になります。
内部リンク:広告×AIの真価を引き出す。CAPIとBigQueryで構築する「自動最適化」データアーキテクチャ
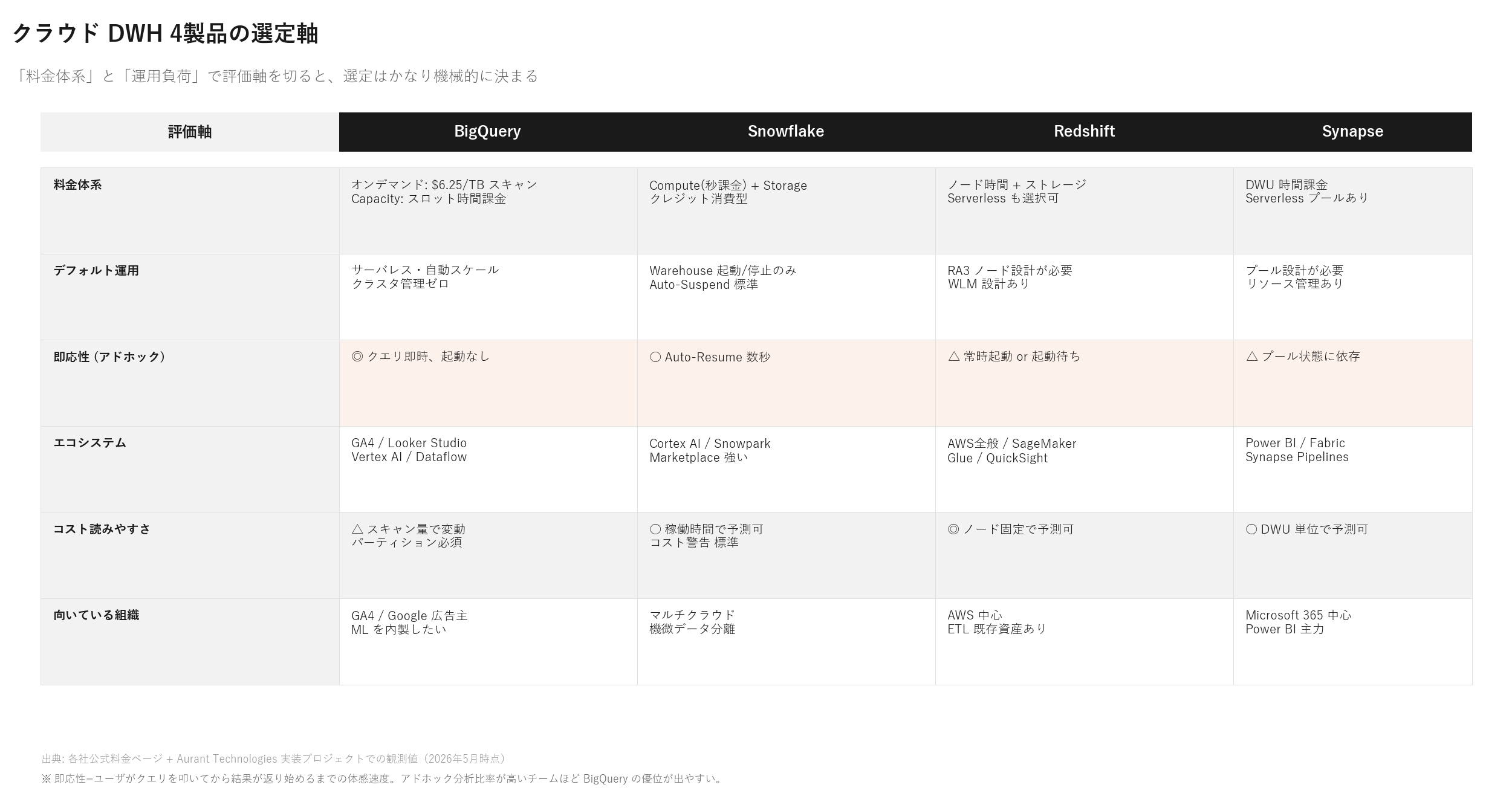
BigQuery vs Snowflake vs Redshift 詳細比較(実務での使い分け)
本記事への流入を見ると「snowflake 製造業 費用」「snowflake bi ツール 連携」「データドリブン経営とは snowflake」「snowflake 導入判断 チェックリスト」など、Snowflake関連のクエリが多数あります。BigQuery 単体だけでなく、Snowflake / Redshift と並べた選定軸が求められています。3製品の実務的な使い分けを整理します。
| 比較軸 | BigQuery | Snowflake | Redshift |
|---|---|---|---|
| 料金体系 | スキャン課金 + Slot予約/エディション制(Standard/Enterprise/Plus) | クレジット課金(コンピュート + ストレージ別) | プロビジョン型(ノード時間)/ Serverless |
| 初期構築 | プロジェクト作成のみ・クラスタ管理不要 | ウェアハウス作成・サイズ選定 | クラスター作成・ノード数指定 |
| Google系SaaS連携 | ◎ GA4・Google広告・Sheets ネイティブ統合 | △ コネクタで対応 | △ コネクタで対応 |
| マルチクラウド対応 | GCP単体 | ◎ AWS/Azure/GCP全対応 | AWS単体 |
| ML/AI機能 | BigQuery ML(SQL内ML) + Vertex AI | Snowflake Cortex(LLM・予測モデル) | Redshift ML(SageMaker連携) |
| BIツール連携 | Looker・Looker Studio・Tableau・Power BI | Tableau・Power BI・ThoughtSpot | QuickSight・Tableau・Power BI |
| データ共有(Data Sharing) | Analytics Hub(組織間共有) | Data Sharing / Marketplace | Datashare |
| 典型コスト(中堅企業/月) | 10〜80万円(クエリ最適化次第) | 20〜150万円 | 30〜200万円 |
| 向くケース | GCPベース・広告データ・Google系SaaS中心 | マルチクラウド・データシェアリング重視 | AWS既存・既存Redshiftからの段階移行 |
選定の現実的な判断軸(3つの問い)
- 「自社のクラウド方針はどうか」:Google Cloud中心なら BigQuery、AWSなら Redshift、複数クラウドなら Snowflake
- 「データ源はどこに偏っているか」:GA4・Google広告など Google系SaaS中心なら BigQuery が圧倒的に効率的
- 「コスト予測の重要度」:「月額が読めること」が経営層の最重要要件なら、Snowflake の固定クレジット予約か BigQuery のエディション制(Enterprise/Plus)
【実務編】BigQuery導入の10ステップ完全ガイド
BigQueryを単なる「データのゴミ溜め」にせず、ビジネス価値を生む基盤にするための具体的な導入フローを解説します。初期設定の甘さは、後のセキュリティ事故やコスト暴走に直結するため、各ステップを慎重に進める必要があります。
Step 1:Google Cloudプロジェクトの策定と組織ポリシーの適用
まず、データ基盤専用のGoogle Cloudプロジェクトを作成します。この際、企業の組織ポリシーとして「データの外部共有制限」や「許可されたロケーション(例:東京リージョン asia-northeast1)」を固定することが推奨されます。これにより、意図しない海外リージョンへのデータ保存や、公開設定ミスによるデータ漏洩を組織レベルで防ぐことができます[4]。
Step 2:IAM(IDとアクセス管理)の厳格な権限設計
「誰が」「どのデータセットに」「何ができるか」を定義します。実務で最も多いトラブルは、権限不足による連携エラーか、逆に権限を与えすぎたことによる誤削除です。
| 担当ロール | 付与する主なIAM権限 | 用途 |
|---|---|---|
| データエンジニア | BigQuery 管理者 (roles/bigquery.admin) | データセットの作成、テーブル設計、全データの管理 |
| ETLツール・システム連携 | BigQuery データ編集者 (roles/bigquery.dataEditor) | 外部ソース(Salesforce等)からのデータ書き込み |
| データアナリスト | BigQuery ジョブユーザー (roles/bigquery.jobUser) | クエリの実行。計算リソースの消費を許可 |
| BIツール連携(表示用) | BigQuery データ閲覧者 (roles/bigquery.dataViewer) | テーブルデータの参照。データの改ざん・削除を禁止 |
Step 3:データセットの階層設計(Layered Architecture)
BigQuery内に「raw(生データ)」「stg(加工中)」「mart(分析用)」といったデータセットを分離します。
- Raw Layer:ソースシステムから取り込んだままの状態。履歴保持のために不変(Immutable)とし、原則として人間は直接参照しません。
- Staging Layer:データ型の統一やNull補完、不要カラムの削除など、クレンジングを行う中間領域です。
- Analytics Layer (Data Mart):dbt等で結合・集計された、BIツールから参照するための最終レイヤーです。
Step 4:パーティショニングとクラスタリングの設計
コスト最適化の核心です。例えば、1億件のイベントデータがあるテーブルで、特定の「1日分」だけを抽出したい場合、event_date列でパーティション(分割)を設定していないと、BigQueryは1億件すべてをスキャンしてしまいます。
- パーティショニング:日付や整数で物理的にデータを分ける。
- クラスタリング:特定の列(顧客IDなど)でデータをソートして配置する。パーティショニングと組み合わせることで、さらにスキャン量を削減し、クエリ性能を向上させます。
Step 5:データインジェスト(取り込み)経路の構築
SaaSやDBからのデータ転送経路を確立します。
- バッチ処理:1日1回、前日分をまとめて転送(troccoやFivetranを活用)。
- ストリーミング注入:リアルタイムにデータを反映(BigQuery Write APIを使用)。これには追加の課金が発生するため、鮮度とコストのトレードオフを検討してください[5]。
Step 6:dbt (data build tool) による変換処理の実装
取り込んだ「生データ」を、分析しやすい形にSQLで変換します。dbtを活用することで、SQLのバージョン管理(Git連携)、テスト(ユニーク制約チェック等)、ドキュメントの自動生成が可能になります。これにより、「このカラムはどういう計算式で出されたか」という属人化の問題を解消できます。
内部リンク:【完全版・第5回】freee会計の「経営可視化・高度連携」フェーズ。会計データを羅針盤に変えるBIとAPI連携術
Step 7:データ品質(Data Quality)のテスト設定
「売上合計がマイナスになっていないか」「重要なID列にNull(空値)が混入していないか」を自動チェックする仕組みを構築します。dbt testや、Google Cloud公式の「Dataplex」を利用したデータプロファイリングが有効です。不正確なデータに基づく意思決定は、誤った経営判断に直結します。
Step 8:BIツール(Looker / Tableau / Power BI)との連携
分析レイヤー(Mart)のテーブルをBIツールに接続します。この際、BIツール側で「ライブ接続(都度クエリ実行)」にするか、「抽出(キャッシュ保持)」にするかを選定します。Lookerの場合はBigQueryの計算能力を最大限に活かすライブ接続が標準的です。接続の際は、専用のサービスアカウントを発行し、最小権限を割り当てることが鉄則です。
Step 9:監査ログ(Cloud Logging)とモニタリングの設定
「誰が、いつ、どのくらいのコストがかかるクエリを叩いたか」を常に監視します。BigQueryのINFORMATION_SCHEMAビューをクエリすることで、高額クエリのワーストランキングを可視化できます。これをSlack等に週次で自動投稿する運用により、組織全体のコスト意識を高めることができます(図2)。

Step 10:コストガードレール(割当制限)の適用
1日あたりのクエリ実行量に上限(カスタムクォータ)を設定します。これにより、エンジニアやアナリストのミスによる「1回のクエリで10万円発生」といった事故を物理的に防ぎます。設定の際は、プロジェクト全体の上限と、ユーザー個別の制限を併用するのが望ましいです。
データ連携を自動化するETL/ELTツールの実務比較
自社でAPI連携プログラムを開発・維持するのは、API仕様変更への追随コストが極めて高く、非効率です。現代のデータ基盤構築では、以下のマネージドツールの活用がスタンダードとなっています。
| ツール名 | 特徴・強み | 実務上の留意点 | 公式サイト |
|---|---|---|---|
| trocco(トロッコ) | 日本発のSaaS。UIが完全日本語化。日本のSaaS(freee, Sansan等)のコネクタが非常に充実。 | エンジニアでなくてもGUIで設定可能。日本の商習慣(和暦変換や全角半角処理)に強い。 | trocco公式サイト |
| Fivetran | 世界シェアNo.1。設定がほぼ「コネクタを選ぶだけ」。スキーマの自動追随が強力。 | MAR(月間アクティブ行数)課金。エンジニア工数をゼロに近づけたい企業向き。 | Fivetran公式サイト |
| BigQuery Data Transfer Service (DTS) | Google公式。Google広告、YouTube、S3からの転送が極めて安価かつ安定。 | 対応先がGoogleエコシステム中心。基幹系DBとの連携には不向き。 | DTS公式ドキュメント |
導入事例から学ぶ成功要因の共通点
事例1:ヤマハ株式会社(trocco導入)
散在していた販売データやマーケティングデータをBigQueryに集約。troccoを採用したことで、従来は外部委託や手作業で行っていたデータ連携の工数を大幅に削減し、内製化に成功しています。成功の鍵は、データ整備の主導権をIT部門からビジネス部門へ一部移譲し、現場のスピード感を優先したことにあります[2]。
事例2:株式会社アシックス(Fivetran導入)
グローバル規模で展開する同社は、世界中の多種多様なデータソースを迅速にBigQueryへ統合する必要がありました。Fivetranによる「メンテナンスフリー」なパイプライン構築により、エンジニアがパイプラインの保守ではなく、分析モデルの開発そのものに集中できる環境を整えています[3]。
共通項からの示唆:
成功している企業は「データの移動」という非付加価値業務をツールで徹底的に自動化し、リソースを「データの活用(可視化・予測)」に全振りしています。逆に、スクラッチ開発にこだわった企業は、APIのアップデート対応で疲弊し、基盤が形骸化する傾向にあります。
【重要】異常系の時系列シナリオと回避・復旧対策
データ基盤運用において、正常系(データが正しく流れている状態)の設計だけでは不十分です。実務で必ず発生する「異常系」への対応を事前に組み込んでおくことが、信頼されるデータ基盤の条件です。
シナリオ1:クエリコストの突発的な高騰
【事象】 アナリストがパーティション指定を忘れ、数テラバイトのテーブルに対して SELECT * を実行。1回で数万円の課金が発生。
【対策】
- カスタムクォータの設定:Google Cloud コンソールの「IAMと管理 > クォータ」から、プロジェクト単位またはユーザー単位での1日のスキャン上限を設定(要確認:社内の承認フローに応じた上限値)。
- 実行前コスト見積もりの義務化:コンソールに表示される「このクエリを実行すると○GBスキャンされます」という警告を確認するフローの形文化。
シナリオ2:データパイプラインの停止(スキーマドリフト)
【事象】 連携元のSaaS(例:Salesforce)でフィールド名が変更された、またはデータ型が変わった(数値→文字列など)ことで、ETLツールがエラーを吐いて停止。
【対策】
- Slack通知の自動化:ETLツールのジョブ失敗を即座にエンジニアへ通知するWebhookの設定。
- スキーマ進化の許容:Fivetranなどのツールを用い、送信元のカラム追加を自動的にBigQuery側のテーブル定義に反映させる。
シナリオ3:データの二重計上(重複)
【事象】 ETLの再実行(リトライ)時に、同一のデータが2回ロードされてしまい、売上合計が2倍に表示される。
【対策】
- 冪等性(べきとうせい)の確保:何度実行しても同じ結果になるよう、ロード前に当該期間のデータを
DELETEしてからINSERTするか、一意なIDでMERGE文を使用する設計にする。 - dbtによる重複チェックテスト:ユニークキーの重複を検知した時点で、下流のダッシュボード用テーブルの更新を停止させる。
BigQueryを「アクションを起こす基盤」に変える高度な活用戦略
データ基盤は、単にダッシュボードを眺めるためのツールから、具体的なビジネスアクションを自動化するための「エンジン」へと進化しています。
リバースETLによる「CRM/MAへの還元」
BigQueryで算出した「解約リスクの高い顧客リスト」や「次にこれを買う可能性が高い商品のリコメンド」を、BIで見るだけでなく、再びCRM(Salesforce)やマーケティングツール(LINE、Braze)に戻す手法をリバースETLと呼びます。
- メリット:現場の営業担当者が、使い慣れたSalesforceの画面上で「AIが算出したスコア」を見てアクションを起こせる。
- 代表的なツール:Hightouch、Census。
内部リンク:高額MAツールは不要。BigQueryとリバースETLで構築する「行動トリガー型LINE配信」の完全アーキテクチャ
BigQuery ML:SQLによる機械学習の民主化
通常、機械学習モデルの構築にはPythonや専門のライブラリが必要ですが、BigQuery MLを使えば、使い慣れたSQLだけで高度な予測モデルを作成できます。
| モデルタイプ | 実務での活用例 | 期待されるビジネス効果 |
|---|---|---|
| 線形回帰 | 広告費と売上の相関から、来月の売上予測。 | 予算配分の最適化と在庫不足の防止。 |
| ロジスティック回帰 | 特定アクションを行ったユーザーの解約率予測。 | 離脱防止キャンペーンのターゲット抽出。 |
| k-means法 | 購買行動に基づいた顧客セグメンテーション。 | パーソナライズされたメルマガ配信。 |
| 時系列予測 (ARIMA+) | 過去の販売トレンドに基づく将来需要予測。 | 物流網の最適化と廃棄ロスの削減。 |
導入後の運用・ガバナンスチェックリスト
導入が成功した後も、継続的なモニタリングが必要です。以下のチェックリストを四半期ごとに確認することを推奨します。
| 確認カテゴリ | チェック項目 | 確認先・方法 |
|---|---|---|
| コスト | 予算(Budget)アラートは設定されているか? | Google Cloud Billing コンソール |
| コスト | 1TBを超えるスキャンを行うクエリが頻発していないか? | INFORMATION_SCHEMA.JOBS_BY_PROJECT |
| セキュリティ | 「Authenticated Users(Googleログイン済み全員)」に閲覧権限がついていないか? | データセット共有設定 |
| セキュリティ | 不要になったサービスアカウントが残っていないか? | IAM 管理画面 |
| データ品質 | dbtのテスト失敗が1週間以上放置されていないか? | dbt Cloud もしくは Airflow 等のログ |
| ガバナンス | PII(個人情報)が含まれるカラムは適切にマスキングされているか? | Cloud DLP(Data Loss Prevention)の適用状況 |
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
よくある質問(FAQ):BigQuery導入の悩みどころ
Q1:導入前にコストを正確に見積もる方法はありますか?
A1:Google Cloud の「料金計算ツール」を使用するのが基本ですが、実務上は「現在保有しているデータ量」と「1日のクエリ実行頻度」の想定が必要です。まずは数GB程度のデータでPoC(概念実証)を行い、1週間程度のスキャン実績から月額を算出することをお勧めします。また、ストレージ料金よりも分析料金が支配的になることが多いため、スキャン量の制御が鍵となります。
Q2:既存のオンプレミスSQL ServerやOracleからの移行は大変ですか?
A2:Google Cloudが提供する「BigQuery Migration Service」を利用すれば、既存のSQL構文をBigQuery用に自動変換したり、データ移行の計画を立てたりすることが可能です。ただし、ストアドプロシージャや独自関数の完全な移行には手修正が必要な場合が多いため、dbt等への移行をセットで検討してください。
Q3:GA4のデータをBigQueryに入れるメリットは何ですか?
A3:GA4の標準画面では「2ヶ月〜14ヶ月」でデータが消えてしまいますが(設定による)、BigQueryにエクスポートすれば期間無制限で保存可能です。また、標準画面では不可能な「ユーザー単位のローデータ分析」や「基幹システムの売上データとの正確な名寄せ」が可能になり、真のLTV分析が実現します。
Q4:LookerとLooker Studio(旧データポータル)のどちらを選ぶべきですか?
A4:Looker Studioは無料で手軽ですが、定義の統一(ガバナンス)に弱点があります。全社的な「売上」の定義を厳密に管理し、データの一貫性を担保したい場合はLookerを選択すべきです。一方、個別の部署が一時的な分析を行うのであればLooker Studioで十分です。併用も一般的です。
Q5:データセットのリージョンはどこが良いですか?
A5:特に制約がなければ、日本のユーザーが多い場合は「asia-northeast1(東京)」を選びます。ただし、連携するS3バケット等が米国にある場合は、転送コストとレイテンシを考慮してリージョンを合わせる(またはマルチリージョンを選択する)必要があります[6]。
Q6:外部テーブル(External Table)機能は使うべきですか?
A6:GoogleドライブやS3上のCSVを直接クエリできる便利な機能ですが、BigQuery内のネイティブテーブルに比べてパフォーマンスは落ち、コスト制御もしにくいです。一時的な検証には向きますが、本番環境の分析基盤としては一度BigQueryへロードすることを推奨します。
ここまでで BigQuery 導入の基本(比較/実装10ステップ/FAQ)を一通り確認しました。ここからは、実プロジェクトでよく問い合わせを受ける「業界別の活用パターン」「AI / Claude 連携の応用編」「コスト最適化の実務テクニック」 の3つを、本記事の主要セクションに対する応用編として整理していきます。
業界別 BigQuery 導入パターン(製造業/広告/製薬)
「bigquery 製造業 導入」「bigquery 製造業 メリット」「bigquery 広告レポート」「bigquery 製薬 比較」など、業界指名のクエリが多数流入しています。業界によって BigQuery の活用軸が大きく違うため、典型パターンを整理します。
製造業
- 典型構成:工場 MES・SCADA・生産管理 → BigQuery → Looker Studio で経営/生産管理/品質管理の3層ダッシュボード
- 強み:GA4+Google広告とのネイティブ統合により「Webからの問い合わせ → 営業 → 工場稼働」の一気通貫分析が可能
- 費用感:中堅製造業(年商500〜2,000億円)で月20〜80万円が現実的なレンジ。マテリアライズドビューとパーティション設計でこれを大幅に下げられる
- 関連記事:製造業DX完全ガイド:生産データ基盤・BI構築10ステップ
広告運用・マーケティング
- 典型構成:GA4 + Google広告 + Meta広告 + Yahoo広告 + Salesforce → BigQuery → Looker Studio 媒体横断ROASダッシュボード
- 強み:GA4 は BigQuery エクスポートが標準機能。Google広告も Data Transfer Service で自動取り込み。Web中心の事業は BigQuery が最も効率的
- 費用感:月10〜40万円。クエリパターンの定型化(マテリアライズドビュー化)で大幅圧縮可能
- 関連記事:広告データ分析基盤の構築完全ガイド:AI自動入札ツール比較・Meta ROAS改善
製薬・ヘルスケア
- 典型構成:MR訪問CRM + 医療従事者ポータル + ウェビナーログ + 学会データ → BigQuery → 医師プロファイル分析
- 強み:医療データの大量処理に強い。匿名加工・同意管理機能との組み合わせで研究データ統合に向く
- 業界固有の論点:要配慮個人情報(病歴・処方)の取り扱い・医療広告ガイドラインへの適合
- 費用感:中堅製薬で月30〜150万円。データ量が大きいため Slot 予約での予算管理が必須
金融・小売・B2B SaaS
本記事の主要 GSC クエリ以外でも、金融機関のリスク管理・小売の店舗売上分析・B2B SaaS のプロダクト分析など、業界横断で BigQuery の利用が広がっています。共通する成功要因は「データ基盤エンジニアとビジネス側の協働体制」「ガバナンスと活用の両立」の2点です。
業界によって BigQuery の使い方は大きく違いますが、2026年以降は「業界を問わず BigQuery を AIエージェントから操作する」方向に進化しています。次は、BigQuery と Claude / Claude Code / MCP を組み合わせた応用パターンを整理します(基本の10ステップが完了している組織向けの内容です)。
BigQuery × Claude / Claude Code / AI活用パターン
「bigquery claude code」というクエリで本記事への流入もあります。2026年は BigQuery を AIエージェントから操作する事例が急速に増えている領域です。実装パターンを整理します。
1. BigQuery ML(標準機能)の活用
- SQL で予測モデル構築:`ML.LINEAR_REG` / `ML.LOGISTIC_REG` / `ML.BOOSTED_TREE_REGRESSOR` などのモデル関数を SQL で呼び出し、需要予測・顧客スコアリングを構築
- BigQuery ML × Gemini:`ML.GENERATE_TEXT` 関数で SQL から Gemini を呼び出し、テキスト要約・分類・抽出を実行
- 外部モデル連携:Vertex AI で学習したモデルを BigQuery 内でリモート推論
2. Claude × BigQuery API カスタム連携
- 自然言語によるクエリ生成:「先月の媒体別 ROAS を出して」を Claude が SQL に変換 → BigQuery で実行 → 結果を要約して返す
- 異常検知の自動化:日次データを Claude に渡し、「異常な数値変動」と「考えられる原因」を自然言語で生成
- 経営会議資料の自動生成:BigQuery の月次サマリ → Claude で経営層向けインサイト要約 → PowerPoint / Notion 経由で配信
3. MCP(Model Context Protocol)経由の BigQuery 操作
- BigQuery MCP サーバー:Claude.ai や Cursor から MCP 経由で BigQuery のテーブル・スキーマを参照・クエリ実行
- 権限管理:MCPサーバーで使う Service Account を最小権限(参照のみ/特定データセットのみ書き込み可)で設計
- セキュリティ留意:本番データへの読み取り権限を持つトークンを LLM プロバイダに渡すリスク評価が必要
AI 連携の話題から一転、運用フェーズで最も多い相談が 「DWHのコストが想定以上に膨らんでいる」 です。BigQuery / Snowflake / Redshift いずれも共通する、コスト削減の実務レバーを整理します。
DWHコストダウンの実務テクニック(BigQuery + Snowflake 共通)
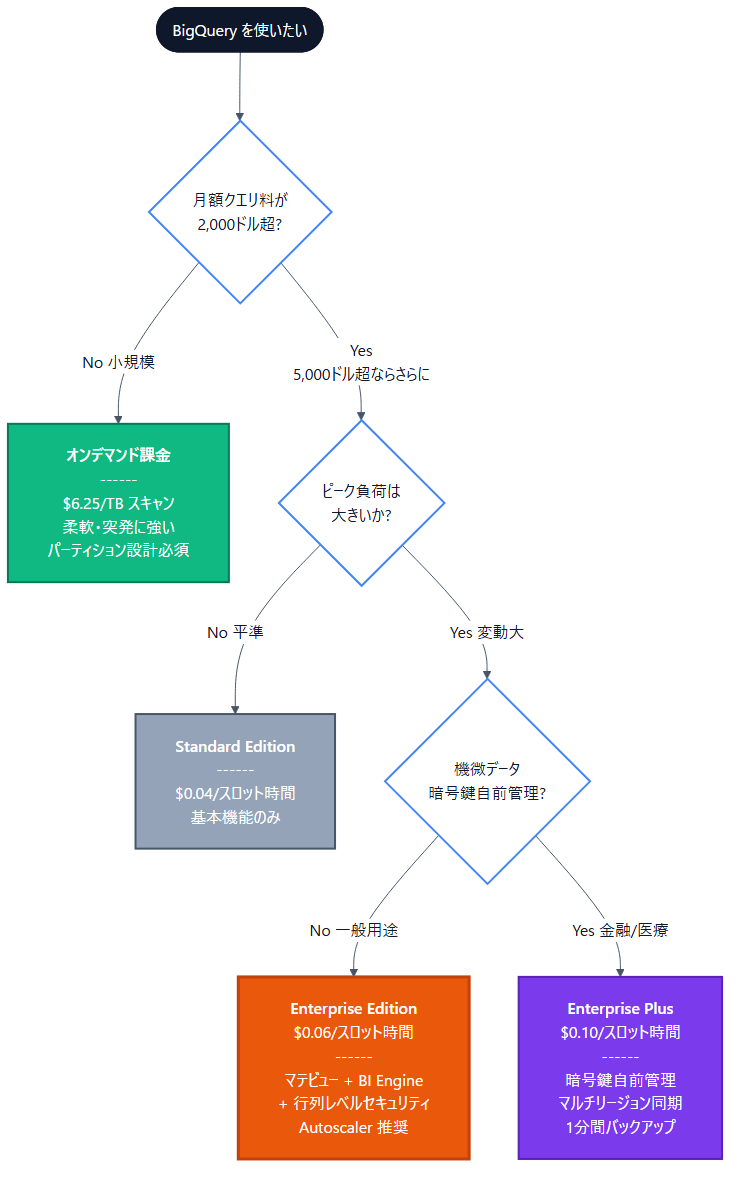
「クラウドデータウェアハウス コストダウン」「snowflake コスト 最適化」「dwh コスト」「データウェアハウス 導入 失敗」のクエリで本記事への流入があります。BigQuery / Snowflake / Redshift 共通で効くコスト削減テクニックを整理します(図3)。
レバー1:パーティション分割・クラスタリング
テーブルを日付・カテゴリでパーティション分割し、クエリでパーティション指定すれば「該当パーティションだけスキャン」される。大量テーブルでは劇的にコスト削減。例:1TB テーブルで日次パーティション → 1日分(数GB)のスキャンだけで済む。
レバー2:マテリアライズドビュー
頻繁に投げる集計クエリは事前計算結果を保存する「マテリアライズドビュー」化。BIから同じパターンのクエリが毎日叩かれる場合、コストが1/10になる事例も。
レバー3:エディション制(Slot 予約)
オンデマンド(スキャン課金)だと予算管理が難しい。月のスキャン量が予測できるなら、Enterprise/Plus エディションで Slot 予約契約(月10万円〜)にすると予算が固定化される。
レバー4:データのライフサイクル管理
古いデータは Cold Storage / Archive Storage に自動移動し、保管コストを削減。BigQuery の Long-term Storage は 90日アクセスなしで自動的に半額に。
レバー5:BIツール側のキャッシュ活用
Looker / Looker Studio / Tableau がキャッシュをうまく使っているか確認。同じクエリが毎回 BigQuery にヒットしているなら、BI側のキャッシュ設定で大幅削減可能。
レバー6:不要クエリの棚卸し
過去6ヶ月のクエリ履歴を `INFORMATION_SCHEMA.JOBS_BY_PROJECT` で集計し、「実は誰も見ていないダッシュボード」「実行されているけど誰も気にしていないバッチ」を停止する。これだけで月数十万円削減できる事例多数。
DWH のコスト超過は「ツールの問題」ではなく「運用設計の問題」です。パーティション設計 + マテリアライズドビュー + エディション制への切替 + ライフサイクル管理 + 不要クエリ棚卸しの5レバーを組み合わせれば、月のコストは初期想定の1/3〜1/5に下げられます。逆に何もしないと、データ量の伸びとともにコストが指数的に膨らみます。
関連記事・クラスター
BigQuery を中心としたデータ基盤設計の関連トピックは以下も参考になります。
- データ統合コストを下げるETLツール比較|中小企業・製造業の実装事例とCDP/iPaaSとの違い — BigQueryへのデータ取り込みETL選定
- 広告データ分析基盤の構築完全ガイド:AI自動入札・Meta ROAS改善・週次レポート自動化 — 広告データ統合の実装
- 製造業DX完全ガイド:生産データ基盤とBI構築 — 製造業 BigQuery活用
- 【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計 — BigQuery関連の包括ガイド
- Looker Studio 完全ガイド:Tableauとの違い・Notion/スプレッドシート連携 — BigQuery × BIツール連携
まとめ:BigQueryを「資産」にするための3つの黄金律
BigQueryの導入は、ツールを契約してデータを流し込むことがゴールではありません。ビジネスに貢献する基盤にするためには、以下の3点を組織文化として定着させてください。
- 「データ型」と「意味」を厳格に管理する:dbt等を用い、誰がクエリを叩いても同じ計算結果になる状態を維持すること。
- 「スキャン量=コスト」を全員が意識する:パーティション設計を怠らず、無駄なスキャンを防ぐ技術的・心理的ガードレールを設けること。
- 「見る」から「使う」へシフトする:ダッシュボードを眺めるだけでなく、リバースETLやBigQuery MLを活用して、日々の業務プロセス(営業活動や広告配信)にデータを自動還流させること。
これらのステップを確実に踏むことで、BigQueryは単なるコストセンターではなく、企業の意思決定を加速させ、競争優位性を生み出す強力な「データ資産」へと変貌します。
参考文献・出典
- ストレージ料金の自動引き下げ — https://cloud.google.com/bigquery/docs/storage_pricing?hl=ja
- (出典の確認できない参考のため削除しました)
- 株式会社アシックス:Fivetran導入によるデータ基盤構築 — https://www.fivetran.com/blog/asics-modernizes-data-stack-with-fivetran-and-bigquery
- Google Cloud 組織ポリシーの制限 — https://cloud.google.com/resource-manager/docs/organization-policy/overview?hl=ja
- BigQuery Write API の概要 — https://cloud.google.com/bigquery/docs/write-api?hl=ja
- データセットのロケーションに関する考慮事項 — https://cloud.google.com/bigquery/docs/locations?hl=ja
- BigQuery ML ドキュメント — https://cloud.google.com/bigquery/docs/bqml-introduction?hl=ja
- dbt 公式サイト — https://www.getdbt.com/
- Google Cloud Architecture Framework: Cost optimization — https://cloud.google.com/architecture/framework/cost-optimization?hl=ja
BigQuery導入を成功させる「費用対効果」の最大化ポイント
BigQueryは従量課金という特性上、導入初期は低コストで済みますが、利用範囲が広がるにつれてコスト管理が最重要課題となります。特に「データの民主化」が進み、非エンジニア層がクエリを実行するようになると、1回のミスが数万円の課金に直結するリスクがあります。ここでは、長期的な運用で失敗しないための追加チェックポイントを整理します。
1. 「エディション制」への切り替えタイミング
従来のオンデマンド料金(1TBあたり$6.25)だけでなく、現在は「Standard」「Enterprise」「Enterprise Plus」というエディション制(スロット予約)が導入されています。常時クエリが実行されるような大規模環境では、オンデマンドよりもエディション制の方がコストを低く抑えられる場合があります。特に、予測可能なワークロードが増えてきた段階で、Google Cloudの「スロット見積もりツール」を活用したシミュレーションを行うことが推奨されます。
2. 「データがゴミ箱になる」のを防ぐガバナンス
データウェアハウス導入で最も多い失敗は、あらゆるデータを無造作に放り込み、誰も詳細がわからない「データスワンプ(データの沼)」化です。これを防ぐには、導入当初からカタログ管理を徹底する必要があります。Google Cloudの「Data Catalog(Dataplex)」を活用し、メタデータにタグ付けを行うことで、必要なデータへ即座にアクセスできる環境を維持しましょう。
実務で活用できる「BigQuery周辺ツール」比較表
| カテゴリ | 代表的なツール | 選定の判断基準 |
|---|---|---|
| ETL/ELT | trocco, Fivetran | 開発工数の削減。日本のSaaS連携ならtrocco、グローバルならFivetran。 |
| データ変換 | dbt | SQLのバージョン管理とテストを必須とする現場ではデファクトスタンダード。 |
| リバースETL | Hightouch, Census | 分析結果をSalesforceやLINEへ戻し、実業務を自動化したい場合に必須。 |
| BI/可視化 | Looker, Looker Studio | 全社的な定義統合ならLooker、手軽なレポート作成ならLooker Studio。 |
3. さらなるデータ活用へのステップアップ
BigQueryにデータが集約された後は、それを「どう実務に還元するか」が焦点となります。例えば、顧客行動データを分析し、最適なタイミングでLINEメッセージを自動配信するような仕組みは、高額なMA(マーケティングオートメーション)ツールを導入せずとも、BigQueryとリバースETLの組み合わせで実現可能です。
具体的な構成案については、以下の関連記事が参考になります。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。