【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
目次 クリックで開く
「BigQuery を導入したが、月額クエリ料が想定の3倍に膨らんだ」「Snowflake と BigQuery の選定で迷っている」「dbt + BigQuery の構成で、Reverse ETL までどう組むべきか」 — このような声を、Aurant ではデータエンジニア・データアナリスト・CDO 配下のデータプラットフォーム責任者からよくいただきます。
2026年の DWH 比較分析では、Snowflake / BigQuery / Redshift の Total Cost of Stack は概ね月額 $5,000〜$25,000の範囲とされています。一方、Snowflake のような従量課金は「想定の200〜300% を超える請求」が発生することが業界の通説になっており、BigQuery の Capacity Editions など、コストコントロール機能の重要性が再認識されています。
本記事では、BigQuery とは何か、Snowflake / Redshift との比較、課金モデル選定、dbt + Hightouch との統合、Reverse ETL、生成 AI 連携、運用体制 / コスト管理 / 3年 TCO の差別化視点まで、論理ステップで整理していきます。
1. BigQuery とは — サーバレス DWH の代表格
BigQuery は、Google Cloud が提供するサーバレス型のクラウド DWH(Data Warehouse)です。Snowflake / Amazon Redshift / Azure Synapse と並ぶ、4大クラウド DWH の1つで、特に「サーバレスの起動コストゼロ」が技術的特徴です。
1-1. BigQuery の本質的な強み
BigQuery 最大の強みは、性能でもコストでもなく起動コストがゼロという運用特性です。Snowflake は Warehouse を起動・停止する概念があり、Redshift と Synapse はクラスタ/プールの設計が必要になります。一方 BigQuery は SELECT を投げた瞬間にスロットが割り当たって走り出します。アドホック分析が業務の半分以上を占めるチームでは、この「待ち時間ゼロ」の体験差がそのまま BI 利用率の差になって現れます。
1-2. BigQuery を選ばない方が良いケース
逆に言えば、定常的なバッチ処理だけが用途で、ダッシュボードを毎朝更新するだけならこの強みは効きにくくなります。Redshift の固定ノード課金の方が月額が読みやすく、結果として安いケースは現場でいくらでもあります。
2. クラウド DWH 4製品の比較 — 選定軸は「料金体系」と「運用負荷」
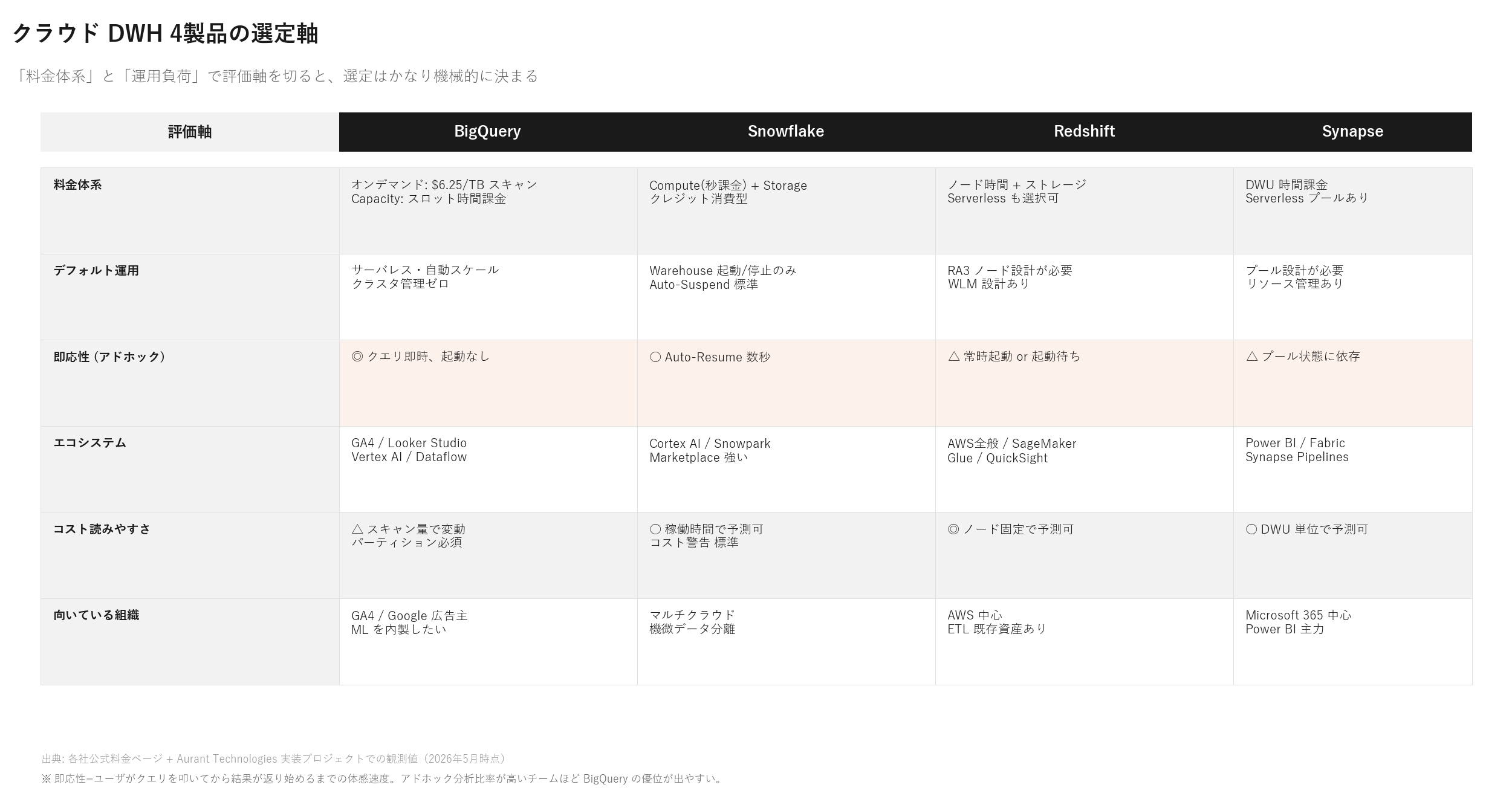
2-1. 4製品の本質的な違い
Reintech の2026年比較でも整理されている通り、Snowflake はストレージとコンピュートの分離をパイオニアした製品で、複数の Virtual Warehouse が同じデータにアクセスできます。BigQuery は完全サーバレスで Google が自動的にリソースを割り当てます。Redshift Serverless は2022年に登場し、2026年までに大幅に成熟しました。
2-2. エコシステムと人材で選ぶ
2026年現在、これら3ツールの機能差は急速に縮まっています。決定要因は「自社のクラウドエコシステム」と「採用可能な人材」の2点に集約されつつあります。
- BigQuery: GA4 / Google Ads / Vertex AI 中心、サーバレスを好むチーム
- Redshift: AWS 中心スタック、S3 / Glue / Kinesis との統合
- Snowflake: マルチクラウド、社外データ共有、Marketplace 強い
- Synapse: Microsoft 365 中心、Power BI 統合
3. 課金モデル — 「スキャン量で払う」か「スロット時間で払う」かの2択
BigQuery 課金の構造は実はシンプルで、クエリ実行料がオンデマンド($6.25/TB スキャン)か Capacity Editions(スロット時間)かを選ぶだけです。ストレージ料はアクティブ $0.020/GB、長期 $0.010/GB(90日未編集で自動切替)で、テーブルが多くても料金全体に占める割合は通常 10〜20% に収まります。

3-1. Capacity Editions 移行のタイミング
具体的な切り替えタイミングの目安は、月のクエリ実行料が概ね 2,000ドル(約30万円)を超え始めた頃です。これより小規模ならオンデマンドの従量で十分柔軟、これを超え始めるとスロット予約で上限を切った方が予算を読みやすくなります。Aurant が見てきた範囲で言うと、毎月 5,000〜8,000ドルを払っているプロジェクトは、Capacity 移行で30〜50% 下がる余地が残っていることが多くあります。
3-2. Capacity Editions の3階層
Capacity Editions はStandard / Enterprise / Enterprise Plusの3階層です。多くの現場で適切なのは Enterprise($0.06/スロット時間)で、マテリアライズドビュー / BI Engine / 行列レベルセキュリティが使えます。Standard は機能的に物足りず、Plus は機微データ業界(金融・医療)以外では過剰になります。
4. パーティションとクラスタリングは「義務」、マテビューは「最後の手段」
オンデマンド課金で BigQuery を使う限り、パーティション設計(典型は日付)とクラスタリング(典型はユーザID や商品ID)はほぼ義務です。これを設計しないと、SELECT がフルスキャンを起こしてあっという間に月10万円・100万円の世界に届きます。
4-1. パーティション設計の基本
パーティションは、テーブルを日付単位で分割するのが基本です。created_at や event_date といった日付カラムでパーティション化することで、特定期間のクエリでスキャン量を限定できます。1年分(365日)のデータがあるテーブルでも、直近7日間のクエリならスキャン量は 1/52 になります。
4-2. クラスタリング設計
クラスタリングは、WHERE 句で頻繁に絞り込むカラムに対して設定します。ユーザID、商品ID、地域コードなどが典型です。最大4カラムまで指定可能で、絞り込み頻度が高い順に並べます。
4-3. マテビューと BI Engine の位置付け
マテリアライズドビューや BI Engine は、パーティションとクラスタリングをやり切った後で初めて検討するレイヤーです。先に入れると「自動更新で結局スキャンが走る」「BI Engine のキャッシュが乗らない」といった理由で、期待した削減が出ません。
5. dbt との分業 — 変換ロジックだけを dbt に運ぶ
BigQuery + dbt の組み合わせは、モダンデータスタックの事実上の標準になりました。Definite の比較記事でも、dbt を使うとアダプタを切り替えるだけで Snowflake / BigQuery / Redshift 間の移行が容易になることが整理されています。
5-1. dbt にすべてを背負わせない
dbt が得意なのは「ELT の T」、つまり DWH に入った後の SQL ベースの変換とテストの部分です。データ取り込み(EL)には Fivetran / Airbyte / trocco / Datastream のような転送基盤を使い、dbt で変換、Looker / Looker Studio で可視化、Hightouch / Census で業務システムへ戻す、という分担が現場で安定します。
5-2. データテスト自動化の価値
dbt 導入で最も価値が出るのは、変換ロジックの可視化(Lineage)よりもデータテストの自動化の方です。not_null や unique といった単純なテストを CI に組み込むだけで、本番ダッシュボードに「数字が合わない」事故が劇的に減ります。
6. モダンデータスタック全体像 — 5〜7ツールの組み合わせ
Definite によると、Snowflake / BigQuery スタックは典型的に5〜7ツールの組み合わせで構成されます。
| レイヤー | 主な選択肢 | 役割 |
|---|---|---|
| Ingestion (EL) | Fivetran / Airbyte | SaaS / DB → DWH 転送 |
| Warehouse | BigQuery / Snowflake / Redshift | データ蓄積・クエリ |
| Transformation | dbt | SQL ベースの変換 |
| BI | Looker / Tableau / Power BI | 可視化 |
| Reverse ETL | Census / Hightouch | DWH → SaaS 書き戻し |
| Observability | Monte Carlo | データ品質監視 |
| Orchestration | Airflow / Dagster | パイプライン実行 |
6-1. 月額コストの目安
これら5〜7ツールの月額コストは、合計で$5,000〜$25,000のレンジになります。中堅企業(年商50〜500億)の標準的な構成で、年額 $60,000〜$300,000(700万〜3,500万円)の TCO が見込まれます。
7. Reverse ETL — Hightouch / Census で業務システムに戻す
BigQuery でデータを集約・集計したら、それを業務システム(Salesforce / Marketo / HubSpot / 広告プラットフォーム)に戻す Reverse ETL のレイヤーが、2024〜2025年で標準化しました。
7-1. 主要ツールの比較
| ツール | 位置付け | 料金 |
|---|---|---|
| Hightouch | 業界 No.1 シェア | 月額 $450〜 |
| Census | エンタープライズ向け | 月額 $300〜 |
| Polytomic | 軽量・コスト効率 | 月額 $250〜 |
| RudderStack | OSS + クラウド | OSS 無料 / クラウド版有料 |
7-2. 典型ユースケース
Reverse ETL の典型ユースケースは、マーケティングオートメーション連動(DWH の顧客スコアを Salesforce に書き戻し)、広告 Audience 配信(LTV 上位顧客を Meta / Google の Customer Match に同期)、カスタマーサポート連携(DWH のリスクスコアを Zendesk に同期)の3つです。
8. BigQuery ML と Vertex AI — 「SQL で機械学習」が刺さる場面
BigQuery ML(SQL でモデルを書ける)は便利な機能ですが、本番で深く使えるシーンは意外と限定的です。線形回帰・ロジスティック回帰・XGBoost あたりまでは現場で十分ですが、特徴量設計や評価のループを回し始めると、結局 Vertex AI Workbench に Python ノートブックを置いて回す方が早くなります。
8-1. BigQuery ML が刺さるケース
BigQuery ML が刺さるのは「データチームが Python を書かない」「BI の延長で予測カラムを足したい」といったケースで、その範囲なら強い武器になります。SQL 知識のあるアナリストが、機械学習の入門として使うのに適しています。
8-2. Gemini 連携の活用
2024〜2025年で増えたのは、BigQuery 内で Gemini を呼び出して構造化抽出する用途です。問い合わせメールから問い合わせカテゴリを抜く、PDF から注文情報を抜く、といった処理を SQL で書けます。データウェアハウスの中で生成 AI を呼ぶことの最大のメリットは「データを外に出さなくて済む」ことで、機微データを扱う業界では選定の決め手になる場面が増えています。
9. セキュリティ・ガバナンス — IAM とポリシータグで詰める
BigQuery のセキュリティ設計で最初に詰めるべきは、データセット単位の IAM とカラム単位のポリシータグの二点です。プロジェクト全体に BigQuery Data Viewer を撒いてしまうと、機微データのテーブルがそのまま BI 経由で見られる事故が起きます。
9-1. IAM 設計の基本
BigQuery の IAM は、プロジェクトレベル / データセットレベル / テーブルレベル / 行列レベルの4階層で設計できます。標準的な設計は、データセットレベルでロールを付与し、機微データのテーブルだけ行列レベルセキュリティで追加制限する構成です。
9-2. ポリシータグの活用
個人情報を含むカラムは、ポリシータグを当てて Data Catalog 側で「PII」「Confidential」と分類します。Dataplex や Atlan / DataHub と組み合わせれば全社のデータカタログとして機能しますが、小規模ならまず BigQuery 単体のポリシータグだけで十分実用になります。
10. 導入の順序 — 半年で全部やろうとすると必ず失敗する
「半年で BigQuery + dbt + Looker Studio + Reverse ETL を全部入れる」と書かれた提案書を時々見ますが、このスケジュールはほぼ確実に破綻します。
10-1. 段階導入の標準スケジュール
| Phase | 期間 | 主な作業 |
|---|---|---|
| 1. Ingestion 構築 | 1〜2ヶ月 | Fivetran / Airbyte でのデータ転送 |
| 2. dbt + テスト整備 | 2〜3ヶ月 | 変換ロジック開発、データテスト自動化 |
| 3. BI 構築 | 1〜2ヶ月 | Looker Studio / Tableau ダッシュボード |
| 4. Reverse ETL | 1〜2ヶ月 | Hightouch / Census で SaaS 書き戻し |
| 5. ML / AI 拡張 | 3〜6ヶ月 | BigQuery ML / Vertex AI / Gemini 連携 |
11. 運用体制の現実 — データチーム編成と内製化
ここから3つの差別化セクションに入ります。BigQuery を中心としたモダンデータスタックは、運用体制が整わないと宝の持ち腐れになります。
11-1. データチームの典型構成
中堅企業のデータチーム標準構成は、「データエンジニア 2〜3名 + データアナリスト 2〜3名 + アナリティクスエンジニア 1〜2名 + データプロダクトマネージャ 1名」の合計 6〜10名規模です。これより少ないと、データ基盤運用 / 分析 / 品質管理のいずれかが手薄になります。
11-2. アナリティクスエンジニアの位置付け
2024〜2026年で重要性が高まっているのがアナリティクスエンジニアです。データエンジニアと データアナリストの中間に位置し、dbt モデル開発・データ品質管理・ビジネス側との要件すり合わせを担います。dbt + BigQuery 構成では、このロールが事実上の中核になります。
11-3. 内製化と外注のバランス
BigQuery / モダンデータスタックの運用は、「内製化を前提」で考えるのが正解です。SI に丸投げすると、データの理解が外部に閉じ、長期的な改善が止まります。最初の 6〜12ヶ月だけ SI に伴走してもらい、その後は内製で運用、というパスが現実的です。
12. コスト管理 — 想定の3倍請求を防ぐ
クラウド DWH のコスト管理は、運用上最も重要なテーマです。Snowflake のような従量課金は、想定の200〜300% を超える請求が発生することが業界の通説です。
12-1. クエリ料の予算アラート
BigQuery では、「クエリあたりのスキャン量上限」「ユーザあたりの月額上限」「プロジェクトあたりの月額上限」を設定できます。本番環境では必ず上限を設定し、想定外のクエリで請求が膨らむのを防ぎます。
12-2. クエリ最適化の文化
データチームに「SELECT * を書かない」「日付パーティションで絞る」「不要な GROUP BY を避ける」といったクエリ最適化の文化を根付かせることが、コスト管理の本質です。BigQuery のクエリ実行前に「このクエリは X TB スキャン、Y ドルかかります」と表示される機能を活用します。
12-3. ストレージ料の長期管理
BigQuery のストレージ料は、長期テーブル(90日未編集)で自動的に半額になります。しかし、「使われなくなったテーブルの削除」を定期的に行うことで、さらにコストを下げられます。dbt の archive テスト機能で、未使用テーブルを自動検出する運用が標準化しています。
13. 3年 TCO 内訳 — DWH + ETL + BI + 人件費
BigQuery を中心とするモダンデータスタックの 3年 TCO は、ライセンス費だけでなく、人件費・教育まで含めて試算します。
13-1. 中堅企業(年商100億円)の TCO 試算例
| 費目 | 初年度 | 2年目 | 3年目 | 3年合計 |
|---|---|---|---|---|
| BigQuery(Capacity Editions) | 500万 | 500万 | 500万 | 1,500万 |
| Fivetran / Airbyte | 300万 | 300万 | 300万 | 900万 |
| dbt Cloud | 120万 | 120万 | 120万 | 360万 |
| Looker / Tableau | 500万 | 500万 | 500万 | 1,500万 |
| Hightouch / Census | 200万 | 200万 | 200万 | 600万 |
| データチーム人件費(6名) | 7,200万 | 7,200万 | 7,200万 | 2.16億 |
| 初期構築費 | 1,500万 | 200万 | 200万 | 1,900万 |
| 合計 | 1.03億 | 9,020万 | 9,020万 | 2.83億 |
13-2. ライセンス費は氷山の一角
表で分かる通り、ライセンス費は 3年 TCO の 18%程度に過ぎません。データチーム人件費が大半を占めます。ベンダー営業の見積で「年額500万円」と聞いても、それは TCO の一部だと理解した上で予算を組む必要があります。
14. BigQuery を選ばない方がいい3つのケース
最後に、現場で見る「BigQuery を選ばない方が良いケース」を整理します。
14-1. AWS 中心のスタック
データソースの大半が AWS にある場合、Redshift か Snowflake on AWSの方が転送コストもデータ整合も素直で、わざわざ BigQuery に持ってくる理由が弱くなります。BigQuery Omni で AWS S3 を直接クエリすることは可能ですが、本番運用で全面採用している事例は限定的です。
14-2. 機微データを物理的に分離したい
機微データを物理的に分離したい場合、Snowflake のアカウント分離・データ共有モデルの方が要件にマッチします。金融・医療業界の規制対応では、Snowflake が選ばれるケースが多くあります。
14-3. 常時稼働の重いバッチ中心
常時稼働の重いバッチ中心で、アドホック比率が低い組織では、Redshift の固定ノードか、Snowflake の Warehouse 常時起動の方がコスト面で有利になることが多くあります。BigQuery が常に最良の選択というわけではなく、組織のクラウド資産と分析スタイルで素直に決めるのが結局は安い選択です。
15. 失敗パターン
BigQuery を中心としたモダンデータスタック導入の典型的な失敗パターンを整理します。
15-1. 「パーティション設計を忘れて月100万請求」
パーティション設計を忘れた巨大テーブルでフルスキャンが発生し、月10万円が月100万円に膨らむケース。打開策は、テーブル作成時に必ずパーティション設計を必須化することです。
15-2. 「dbt にすべてを背負わせる」
EL と T を全部 dbt で組もうとして複雑化するケース。打開策は EL は Fivetran / Airbyte に任せ、dbt は変換とテストに集中することです。
15-3. 「Reverse ETL 不在で BI で終わる」
BigQuery + Looker でダッシュボード作成までで止まり、業務システムへの還流ができていないケース。打開策は、Reverse ETL(Hightouch / Census)を Phase 4 で必ず組み込み、データを業務側に届けることです。
16. まとめ — 自社状況別の判断軸
| 自社の状況 | 推奨 DWH | 3年 TCO 目安 |
|---|---|---|
| GA4 / Google Ads 中心・サーバレス志向 | BigQuery | 2億〜3.5億 |
| AWS 中心・既存 S3 / Glue 連携 | Redshift | 1.5億〜3億 |
| マルチクラウド・データ共有重視 | Snowflake | 2.5億〜5億 |
| Microsoft 365 中心 | Synapse | 1.5億〜3億 |
| 機微データ分離が必須 | Snowflake | 3億〜6億 |
判断のコツは、「アドホック分析比率が高いなら BigQuery」「課金は2,000ドル超で Capacity Editions」「ETL → 変換 → 可視化 → Reverse ETL の順で段階導入」「データチーム人件費を TCO に必ず織り込む」の4点です。
BigQuery を中心としたモダンデータスタックは、技術より「データチーム編成」「クエリ最適化文化」「内製化への移行」といった組織設計が成否を分けます。Aurant Technologies では、BigQuery を中心としたモダンデータスタックの設計から運用までのご支援を、データチーム伴走から内製化支援まで一貫してご提供しています。お気軽にご相談ください。
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。

執筆・監修
Aurant Technologies CAIO(Chief AI Officer)
CDP / データ基盤 / 生成AI 領域の実装責任者。本記事は実プロジェクトの観測値と各社公開情報・公式ドキュメントをもとに執筆しています。
データ分析・BI
Looker Studio・Tableau・BigQueryを活用したBIダッシュボード構築から、データ基盤整備・KPI設計まで対応。経営判断をデータで支援します。