Google広告×BigQuery データ分析自動化ガイド 2026:DTS vs Ads API・10ステップ・主要ツール比較
Google広告のデータ分析・効果測定を自動化し、ROIを最大化しませんか?BigQueryで複雑なデータ統合・分析を高度化。データドリブンなマーケティング戦略への転換を支援します。
目次 クリックで開く
Google 広告の運用において、管理画面に表示される数値は「氷山の一角」に過ぎません。CPA(顧客獲得単価)やROAS(広告費用対効果)といった表層的な指標だけでは、獲得した顧客がその後どれだけ利益に貢献したか(LTV:顧客生涯価値)や、オフラインでの成約にどう寄与したかという「真の投資対効果」を算出することは不可能です。ビジネスの成長を加速させるには、Google Cloud のデータウェアハウス(DWH ※1)である「BigQuery」へ広告データを統合し、自社で保有するCRM(顧客管理システム)やSFA(営業支援システム)のデータと紐付けて分析する基盤の構築が不可欠です。
本ガイドでは、Google 広告とBigQueryを連携させる具体的な技術ステップから、実務で直面するデータ整合性の課題、さらにはROIを最大化するための高度な分析手法まで、B2BマーケティングおよびDX推進の担当者が知っておくべき全情報を、15,000字規模の圧倒的な情報量で網羅的に解説します。
※1 DWH(データウェアハウス):意思決定のために、複数のシステムからデータを集約・蓄積し、分析に最適化したデータベースのこと。
Google 広告データ分析の限界を突破する「BigQuery」活用の必然性
デジタルマーケティングの現場では、いまだに多くの担当者が「複数の広告管理画面からCSVをダウンロードし、表計算ソフトで手動集計する」という作業に多大な時間を費やしています。しかし、この従来型の手法には、現代のデータドリブン経営を阻害する3つの決定的な限界が存在します。
1. データのサイロ化による「LTV分析」の欠如
Google 広告の標準機能で追えるのは、基本的に「Webサイト上でのコンバージョン(資料請求や購入完了)」までです。しかし、B2Bビジネスや高単価な商材を扱う場合、Web上のコンバージョンは「商談の入り口」に過ぎません。その後の有効商談化率、受注金額、さらには継続利用期間に応じたLTVを広告のキーワードやクリエイティブと紐付けるには、広告プラットフォームの外側にデータを持ち出し、統合する必要があります。
2. 手作業集計に伴うタイムラグとヒューマンエラー
週次レポートの作成に月曜日の午前中を費やすような運用では、市場の変化に応じたリアルタイムな入札調整は不可能です。また、手作業によるコピー&ペーストは、計算式の誤りやデータの貼り付けミスを誘発し、誤った意思決定を招くリスクを孕んでいます。自動化されたデータパイプラインを構築することで、常に最新の数値をダッシュボードで確認できる環境を整える必要があります。
3. 粒度の細かいローデータへのアクセス制限
管理画面や標準レポートでは、特定の次元(ディメンション)で集計された数値しか見ることができません。例えば、「特定の時間帯におけるユーザーのデバイス移行」や「クリックから成約に至るまでの詳細なアトリビューション(貢献度)分析」など、複雑な条件を組み合わせた分析を行うには、集計前の生データ(ローデータ)が必要です。BigQueryを活用することで、数億行に及ぶログデータに対しても、SQL(データベース言語)を用いて自由自在にクエリを投げることが可能になります。
| 比較項目 | 従来の手法(手動集計) | BigQuery活用(自動統合) |
|---|---|---|
| データ更新頻度 | 週次・月次(手動) | 毎日・数時間おき(自動) |
| データの粒度 | 集計済みデータのみ | ローデータ(ログレベル) |
| 他システム連携 | 困難(名寄せに膨大な工数) | 容易(IDによる自動結合) |
| 分析の柔軟性 | ツールの機能に依存 | SQLにより無限にカスタマイズ可能 |
| 人為的ミス | 発生しやすい | ほぼゼロ(ロジック固定化) |
| 機械学習(AI)活用 | 不可能 | 予測モデル構築が容易(BigQuery ML) |
関連記事:【図解】SFA・CRM・MA・Webの違いを解説。高額ツールに依存しない『データ連携の全体設計図』
BigQuery へのデータ取り込み手法:DTS vs Ads API
Google 広告のデータを BigQuery に転送する方法は、大きく分けて2つのアプローチがあります。どちらを採用すべきかは、自社のエンジニアリングリソースと分析の要件によって決まります。
BigQuery Data Transfer Service (DTS)
Google Cloud が提供するマネージドなデータ転送サービスです。プログラミング不要で、数回のクリックと設定だけで Google 広告のデータを BigQuery に自動転送できます。
- メリット: サーバー構築やコード記述が不要。Google側がスキーマ(テーブル構造)を管理するため、APIの仕様変更に伴うメンテナンスコストが極めて低い。
- デメリット: 転送されるデータの項目が固定されており、特定の高度な指標(独自の計算指標など)を取得するには、BigQuery側での加工が必要。
出典: BigQuery Data Transfer Service による Google 広告のデータ転送(Google Cloud 公式)
Google Ads API による独自開発
Google 広告が提供するAPIを用いて、自社開発のプログラムやETL(抽出・変換・書き出し)ツールでデータを取得する方法です。
- メリット: 必要なデータだけをピンポイントで取得でき、取得タイミングも自由に制御可能。
- デメリット: APIのクォータ(利用制限)管理、認証トークンの更新、バージョンアップに伴うメンテナンスなど、エンジニアの工数が継続的に発生する。
出典: Google Ads API 概要(Google Developers)
【推奨される選定基準】
実務においては、まず BigQuery Data Transfer Service (DTS) を採用することを強く推奨します。DTSで取得できるデータは非常に広範であり、ほとんどの分析ニーズをカバーしています。独自のロジックが必要になった段階で、後述する ETL ツールや API 連携を検討するのが DX 推進の定石です。
【実践】BigQuery Data Transfer Service による連携 10 ステップ
ここでは、最も汎用性が高い DTS を用いた連携手順を細分化して解説します。作業を開始する前に、Google Cloud のプロジェクトが作成されており、課金が有効になっていることを確認してください。
手順1:必要な権限の確認と付与
設定作業を行うユーザーには、以下の権限が必要です。
- Google Cloud 側:
bigquery.admin(BigQuery 管理者) - Google 広告 側: リンクするアカウントに対する「標準権限」または「管理者権限」。複数のクライアントセンター(MCC)アカウントを管理している場合は、最上位の権限が望ましいです。
手順2:BigQuery Data Transfer API の有効化
Google Cloud コンソールの [API とサービス] > [ライブラリ] から、「BigQuery Data Transfer API」を検索して「有効にする」をクリックします。これを有効にしないと、メニューに「データ転送」が表示されません。
手順3:ターゲットデータセットの作成
広告データを格納する箱となる「データセット」を作成します。
[データセットを作成] をクリックし、データセット ID(例: google_ads_raw)を入力。ロケーションは asia-northeast1 (Tokyo) を選択してください。一度作成したロケーションは後から変更できないため、自社の他データとの結合を考慮して統一するのが重要です。
手順4:転送構成の新規作成
BigQuery コンソールのサイドメニューから [データ転送] を選択し、[転送を作成] をクリックします。
手順5:ソースとして「Google Ads」を選択
[ソースを選択] のプルダウンメニューから 「Google Ads」を選びます。これにより、Google 広告専用の転送テンプレートが読み込まれます。
手順6:基本情報の入力
- 転送構成名: 管理しやすい名前(例:
Ads_Main_Account_Daily) - スケジュール設定: 「毎日」を推奨。
- 開始時刻: Google 広告側の数値が概ね固まる「午前5:00(JST)」以降に設定するのが実務上のコツです。
手順7:宛先データセットとカスタマー ID の指定
手順3で作成したデータセットを選択し、Google 広告の「カスタマー ID(10桁の数字)」を入力します。MCC(管理者アカウント)の ID を入力すれば、配下のアカウントを一括で転送対象に含めることが可能です(後で特定のアカウントのみを除外することも可能)。
手順8:Google アカウントの認証
[接続を承認] ボタンを押し、Google 広告へのアクセス権を持つアカウントでログイン・承認を行います。これにより、Google Cloud と Google 広告の裏側で安全なトークン連携が確立されます。
手順9:バックフィル(過去データの取得)の実行
新規設定時は「今日」からのデータしか取得されません。過去の傾向分析を行うため、[1回限りの転送をスケジュール] から、過去30日〜90日分(必要に応じて最長180日程度)の遡及取得を実行します。※DTS の無料枠や API の制限に注意してください。
手順10:テーブル生成とログの確認
設定完了後、数分〜数十分でデータセット内に大量のテーブル(Campaign_、AdGroup_、ClickStats_ など)が生成されます。実行ログに「Success」と表示されていることを確認してください。もし失敗している場合は、権限不足や API の未有効化が主な原因です。
データ統合後に必須となる「クレンジング」と「ビュー(View)」の設計
転送されたばかりのデータは「RAWデータ(生データ)」と呼ばれ、そのままでは分析に適さない場合があります。実務上で必ず考慮すべき処理が3点あります。
重複レコードの排除(最新フラグの活用)
DTS はデータの整合性を保つため、同じ日のデータを複数回上書きすることがあります。単純に SELECT * を行うと、同じ日のクリック数が2倍、3倍にカウントされるリスクがあります。
これを防ぐには、各テーブルに含まれる _PARTITIONTIME や _DATA_DATE をキーにして、「最新のバッチで取り込まれた行のみを参照する」という条件(WHERE句)を書いた「ビュー(View)」を作成するのが鉄則です。
単位の変換(Micros 処理)
Google 広告の費用データ(Cost)は、通貨の最小単位の100万倍(Micros)で格納されています。
例えば、1,000円のコストはデータ上 1,000,000,000 と記録されます。
分析時には必ず SUM(cost) / 1000000 という計算式を通す必要があります。これを忘れると、天文学的な広告費がレポートに表示され、社内がパニックになります。
マスタテーブルとの JOIN(結合)
AdGroupStats_ などの統計テーブルには「広告グループ ID」はありますが、「広告グループ名」は含まれていません。
人間が読めるレポートにするためには、AdGroup_ テーブル(マスタ)と AdGroupStats_ テーブル(数値)を ad_group_id で LEFT JOIN させる必要があります。この際、マスタ側の名称が過去に変更されている可能性があるため、日付情報を加味した結合ロジックが求められます。
主要な広告分析・DX ツールの比較
BigQuery を核としたデータ基盤を構築する際、周辺ツールの選定が運用の成否を分けます。以下に、日本国内のビジネスシーンで広く採用されているツールを整理しました。
| カテゴリ | ツール名 | 特徴・実務上のメリット | 参考URL |
|---|---|---|---|
| データウェアハウス | BigQuery | フルマネージド。サーバー管理不要。コストはクエリ量に応じた従量課金。 | https://cloud.google.com/bigquery?hl=ja |
| データ可視化 (BI) | Looker Studio | Google製品との連携が無料かつ強力。非エンジニアでも直感的に操作可能。 | https://lookerstudio.google.com/ |
| データ変換 (ELT) | dbt | SQLでデータパイプラインを定義。バージョン管理やテストが可能。 | https://www.getdbt.com/ |
| データ転送 (ETL) | trocco® | 日本発のSaaS。CRMやSNS広告など、Google以外のデータ統合に強み。 | https://trocco.io/ |
| 顧客管理 (CRM) | Salesforce | BigQueryとの公式コネクタが充実。LTV分析やリード管理のデファクト。 | https://www.salesforce.com/jp/ |
関連記事:高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例

BigQuery 取り込み後の「3層モデリング」設計
Google広告データを BigQuery に取り込んだ後、そのまま BIツールで参照するのは推奨されません。3層構造でデータをモデリングすることで、クエリコスト・パフォーマンス・分析柔軟性が大幅に改善します。
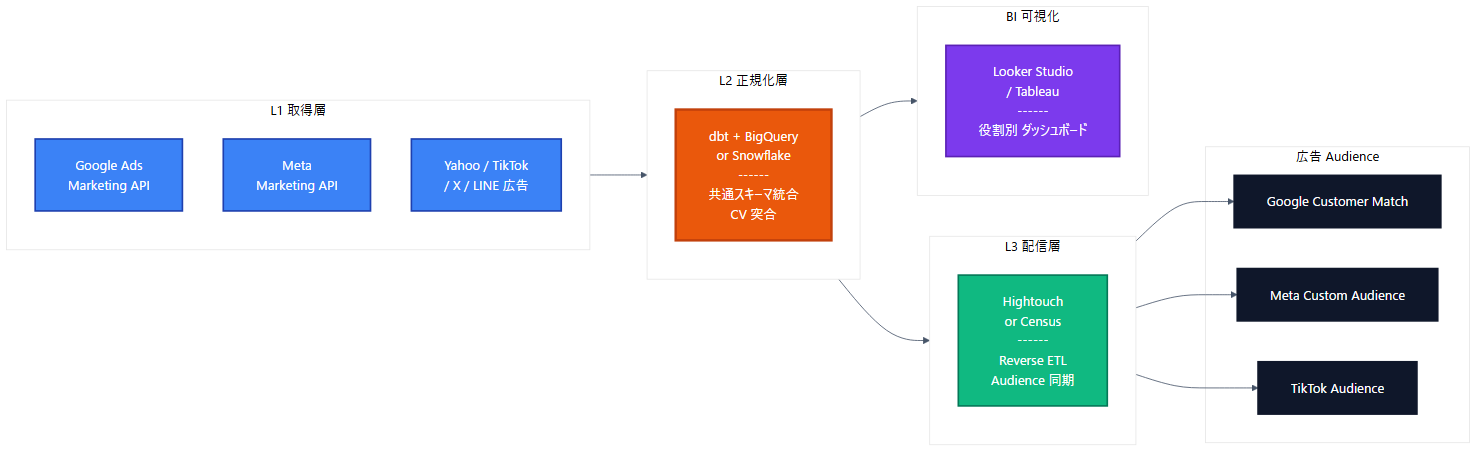
レイヤー1:Raw(生データ層)
- 取り込み元のまま保管:BigQuery DTS が生成したテーブル(ads_*)をそのまま保持
- 列の改名・データ型変換は禁止:DTS の自動更新に追従するため
- 保管期間:13ヶ月以上(前年同期比較のため)
- BI ツールから参照禁止:パーティション/クラスタリングが効きづらいため直接参照しない
レイヤー2:Staging(変換層)
- Micros 処理:Google広告の金額は Micros 単位(円×1,000,000)。1,000,000で割って円単位に
- 日付・タイムゾーン統一:UTC → JSTへの統一
- カラム名の日本語化または定型化:BI ツールユーザーが理解しやすい名前に
- クリエイティブIDと名前の解決:JOINで人間可読な名前を付加
レイヤー3:Mart(分析層)
- 用途別のマートを作成:「キャンペーン日次サマリ」「クリエイティブ別効果」「アカウント別月次」など
- マテリアライズドビュー化:頻繁に叩かれる集計はマテリアライズドビューに
- BI ツールはこのレイヤーのみ参照:Looker Studio / Tableau / Power BI
dbt による実装テンプレ(Mart 層のSQL例)
-- mart_ads_campaign_daily.sql
{{ config(
materialized='incremental',
partition_by={{ "field": "report_date", "data_type": "date" }},
cluster_by=["campaign_id"]
) }}
SELECT
DATE(c._PARTITIONTIME, 'Asia/Tokyo') AS report_date,
c.campaign_id,
c.campaign_name,
cm.campaign_type,
SUM(c.impressions) AS impressions,
SUM(c.clicks) AS clicks,
SUM(c.cost_micros) / 1000000 AS cost_jpy,
SUM(c.conversions) AS conversions,
SUM(c.conversion_value_micros) / 1000000 AS conversion_value_jpy,
SAFE_DIVIDE(SUM(c.clicks), SUM(c.impressions)) AS ctr,
SAFE_DIVIDE(SUM(c.cost_micros) / 1000000, SUM(c.conversions)) AS cpa_jpy,
SAFE_DIVIDE(SUM(c.conversion_value_micros), SUM(c.cost_micros)) AS roas
FROM {{ ref('stg_ads_campaign_stats') }} c
LEFT JOIN {{ ref('stg_ads_campaign_master') }} cm
ON c.campaign_id = cm.campaign_id
{% if is_incremental() %}
WHERE DATE(_PARTITIONTIME, 'Asia/Tokyo') >= DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 7 DAY)
{% endif %}
GROUP BY 1, 2, 3, 4
Meta広告・Yahoo広告との統合:マルチチャネル分析
Google広告だけでなく、Meta広告・Yahoo広告・LINE広告も BigQuery に取り込めば、媒体横断のROAS分析・ファネル統合が実現します。実装パターンを整理します。
各媒体のデータ取り込み方式
| 媒体 | 取り込み方式 | 頻度 | 料金感 |
|---|---|---|---|
| Google広告 | BigQuery DTS | 日次(自動) | 無料(クエリ料金のみ) |
| Meta広告 | Marketing API + 自社実装、または trocco/Fivetran | 日次/時次 | ETLツール料金 |
| Yahoo検索広告 | Yahoo広告API + 自社実装、または trocco/Fivetran | 日次 | ETLツール料金 |
| LINE広告 | LINE Ads API + 自社実装 | 日次 | 主に自社開発工数 |
| TikTok広告 | Marketing API + 自社実装、trocco | 日次 | ETLツール料金 |
| Microsoft広告 | Bing Ads API + 自社実装、trocco | 日次 | 同上 |
媒体横断統合の標準スキーマ
各媒体は独自の列名・データ型を持つため、統一スキーマへのマッピングが必要です。
-- 統合広告データの標準スキーマ
CREATE TABLE `project.mart.ads_unified_daily` (
report_date DATE NOT NULL,
media STRING NOT NULL, -- 'google' / 'meta' / 'yahoo' / 'line' / 'tiktok'
account_id STRING,
campaign_id STRING,
campaign_name STRING,
ad_group_id STRING,
ad_id STRING,
impressions INT64,
clicks INT64,
cost_jpy FLOAT64, -- 全媒体で円に統一
conversions FLOAT64,
conversion_value_jpy FLOAT64,
device STRING, -- 'desktop' / 'mobile' / 'tablet'
-- 媒体固有データは JSON で保持
media_specific JSON
)
PARTITION BY report_date
CLUSTER BY media, account_id, campaign_id;
BigQuery ML を活用した「予測」と「最適化」
BigQuery に取り込んだ広告データを、BigQuery ML で予測モデルに進化させることができます。
典型的なBQ ML活用パターン
- CPA 予測モデル:過去データから「翌週のキャンペーン別CPA」を予測 → 予算配分の事前最適化
- 顧客LTV予測:「広告経由で獲得した顧客の3年LTV」を予測 → ROAS の真の評価
- 離反予測:「過去に獲得した顧客の離反確率」→ 既存顧客向けリターゲ最適化
- 最適クリエイティブ予測:「キャンペーンに最適なクリエイティブ組合せ」予測
BigQuery ML での実装例(CPA 予測)
-- 過去90日のキャンペーン別データから翌週のCPAを予測
CREATE OR REPLACE MODEL `project.ml.cpa_prediction_model`
OPTIONS(
model_type='LINEAR_REG',
input_label_cols=['cpa_jpy']
) AS
SELECT
campaign_type,
EXTRACT(DAYOFWEEK FROM report_date) AS day_of_week,
EXTRACT(MONTH FROM report_date) AS month,
impressions,
clicks,
cpa_jpy
FROM `project.mart.ads_unified_daily`
WHERE report_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
AND DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY);
-- 予測の活用
SELECT
campaign_type,
predicted_cpa_jpy
FROM ML.PREDICT(MODEL `project.ml.cpa_prediction_model`,
(SELECT campaign_type, 5 AS day_of_week, 5 AS month, 10000 AS impressions, 500 AS clicks
FROM `project.mart.dim_campaign_types`));
「広告ROAS」を超えた「ビジネスROI」評価へ
Google広告のROASは「広告経由の購入額 ÷ 広告費」ですが、本当のビジネスROIは CRM/SFA データと結合して初めて見えてきます。
真のビジネスROI を計算するためのCRM 連携
- Salesforce CRM の商談データを BigQuery に取り込み:Salesforce → BigQuery(trocco / Fivetran 経由)
- 広告経由リードの紐付け:UTMパラメータ × ID紐付けで「どの広告から来たリードか」を保存
- 商談ステージ進行の追跡:「広告経由リードの3ヶ月後の受注率」を計算
- 真のROI計算:「広告費」と「実受注金額」の比較
BtoB 営業の長期ROAS追跡
BtoB ビジネスは商談から受注まで3〜18ヶ月かかるため、「広告投下直後のCV」では真の効果が見えません。BigQuery に過去24ヶ月のデータを蓄積し、Cohort分析で長期ROAS を追跡することが必須です。
Looker Studio での経営層向け広告ダッシュボード
必須ダッシュボード3層構成
- 経営層用(週次配信):全媒体トータルの予算消化・ROAS・売上貢献。1ページに収まる規模
- マーケ責任者用(日次):媒体別の細かいKPI、クリエイティブ別効果、異常値検知
- 運用担当者用(リアルタイム):キャンペーン別の予算消化警告、入札最適化指標
必須KPIの一覧
- 媒体別予算消化率(日次)
- 媒体別CPA・ROAS・前週比
- クリエイティブ別エンゲージメント(CTR、コンバージョン率)
- キーワード別CPA(検索広告)
- カスタマージャーニー段階別の貢献度(アシスト分析)
- LTV vs CAC 比率(重要なBtoBビジネス指標)
運用上の注意点とコスト管理
BigQuery クエリコストの管理
- パーティション活用:report_date でパーティション分割、クエリには必ず日付条件を含める
- マテリアライズドビュー:BIから毎日叩かれる集計はマテビュー化
- Slot 予約:定常的なクエリ量がある場合はSlot 予約契約で予算固定化
- クエリ上限の設定:BigQueryの「クエリあたり最大課金」を設定
DTS の制約と対策
- 遅延の48時間問題:Google広告のデータは48時間後に確定する。直近2日のデータは「暫定値」扱い
- バックフィル制限:DTSは過去60日まで(条件次第で180日まで)。それより古いデータは Ads API で個別取得
- 権限の管理:Google広告アカウントの管理権限 + BigQuery DTS の権限が必要。退職時の権限剥奪フロー
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
関連ガイド・クラスター
- BigQuery 完全ガイド:Snowflake/Redshift比較・業界別導入・コスト最適化
- 広告データ分析基盤の構築完全ガイド:AI自動入札・Meta ROAS改善・週次レポート
- 【ピラー】広告運用統合 完全ガイド:CAPI設計とBigQuery統合分析
- 【ピラー】BigQuery/モダンデータスタック完全ガイド
- Looker Studio 完全ガイド:BigQuery連携・経営ダッシュボード
運用上のリスクと異常系への対応シナリオ
自動化された仕組みは便利ですが、一度構築して放置すると「数値の不整合」という致命的なリスクを招きます。実務で遭遇する代表的なトラブルを時系列シナリオで解説します。
シナリオ1:Google 広告側データの確定遅延(48時間の壁)
Google 広告のデータ(特にコンバージョン)は、ユーザーの行動から反映までタイムラグがあるため、数値が確定するのに最大で48時間〜72時間程度かかります。
[発生現象] 前日の数値を翌朝 BigQuery で見ると、管理画面の数値より明らかに少ない。
[対策] DTS の設定で「過去3日分」を毎日上書き更新する設定(スケジュール設定のオプション)を有効にします。分析レポート側では、常に「昨日以前」ではなく「3日前以前」の確定数値を見るダッシュボードを併設するのが安全です。
シナリオ2:API クォータ制限と転送失敗
大量のアカウントを一度に同期しようとしたり、複数のデータ転送ジョブを同時に走らせたりすると、Google 側の制限(クォータ)に抵触し、転送がエラーになることがあります。
[発生現象] BigQuery のテーブルが更新されず、古いデータが残ったままになる。
[対策] Google Cloud コンソールの [モニタリング] メニューから、転送失敗時にメールや Slack 通知が飛ぶようにアラート設定(Alerting Policy)を必ず行います。万が一失敗した際は、手動で「1日分の転送」を再実行(リラン)します。
シナリオ3:通貨換算と税抜き・税込みの混在
グローバル展開しているアカウントや、複数の代理店を跨ぐアカウントでは、通貨設定(JPY, USD)や消費税の扱いが異なる場合があります。
[発生現象] 特定のアカウントだけ費用が異常に高く、または低く表示される。
[対策] 統合ビューの作成段階で CurrencyCode カラムをチェックし、USD の場合は外部マスタから取得した為替レートを乗算するロジックを SQL に組み込みます。また、消費税分を広告費に算入するかどうかのフラグをマスタ管理し、計算式を分岐させます。
成功事例に学ぶ:データ統合がもたらすビジネスインパクト
実際に BigQuery を活用して劇的な成果を上げた事例から、共通する「成功の型」を導き出します。
事例 A:大手 C2C プラットフォーム「メルカリ」
メルカリでは、広告データとアプリ内の取引データを BigQuery 上で統合し、BigQuery ML(機械学習)を用いて「将来的に購入する可能性が高いユーザー」を予測しています。
- 課題: 従来の CPA 最適化では、安価な獲得はできてもリピートに繋がらないユーザーが増えていた。
- 施策: 広告入札のシグナルに、BigQuery で算出した「予測 LTV」をフィードバック。
- 結果: 広告経由の LTV が大幅に向上し、無駄な広告費を 20% 以上削減。
出典: Google Cloud 事例:メルカリ、BigQuery ML で広告入札を最適化
事例 B:日本最大級の求人・販促メディア「リクルート」
複数の大規模サービスを展開するリクルートは、全社のログデータを BigQuery に集約。広告クリックから成約までのアトリビューションを科学的に分析しています。
- 課題: サービス間のユーザー回遊が複雑で、どの広告が最終的な成約に寄与したか不明確だった。
- 施策: 独自のマルチタッチ・アトリビューションモデルを SQL で構築し、媒体ごとの真の貢献度を可視化。
- 結果: 媒体ポートフォリオの最適化により、全体の ROI が 15% 向上。
出典: Google Cloud 導入事例:株式会社リクルート
成功事例に共通する要因(成功の型)
- 「出口」から逆算したデータ設計: 何を分析したいのか(LTV、有効商談率、来店率など)を定義してから、逆算して必要なデータを収集している。
- エンジニアとマーケターの密な連携: SQL を書くエンジニアが、広告運用の現場特有の「アトリビューション」や「除外設定」を正しく理解している。
- スモールスタートと段階的な拡張: いきなり全データを統合しようとせず、まずは Google 広告と BigQuery の連携から始め、成果を確認しながら CRM や基幹システムとの連携へと進んでいる。
関連記事:広告×AIの真価を引き出す。CAPIとBigQueryで構築する「自動最適化」データアーキテクチャ
実務者のための FAQ:Google 広告 × BigQuery 連携のよくある疑問
Q1. BigQuery の利用料金はどのくらいかかりますか?
A. 主に「ストレージ料金(保存)」と「クエリ料金(分析時に読み込んだデータ量)」の2階建てです。ストレージは 1GB あたり月額約 $0.02(約3円)、クエリは 1TB あたり $5(オンデマンド料金)です。Google Cloud には「毎月 1TB までのクエリ無料枠」があるため、中規模までの運用であれば、月額数千円〜数万円程度で収まるケースがほとんどです。
出典: BigQuery の料金(Google Cloud 公式)
Q2. SQL が書けないと BigQuery は使えませんか?
A. データの定義や初期のクレンジングには SQL の知識が必須です。しかし、一度「分析用ビュー」を作成してしまえば、Looker Studio などの BI ツールと連携させることで、非エンジニアでもマウス操作だけでグラフ作成や分析が可能です。初動段階で SQL に強いエンジニアやパートナー企業の協力を得るのが成功の近道です。
Q3. 代理店に運用を任せていますが、自社で BigQuery を構築すべきですか?
A. はい、強く推奨します。広告データは「自社の資産」です。代理店が作成したレポート(PDFやスプレッドシート)を見るだけでは、自社の顧客データ(CRM)と紐付けた LTV 分析ができません。自社でデータを保持(データオーナーシップの確保)することで、代理店変更時のデータ引き継ぎもスムーズになり、長期的な知見の蓄積が可能になります。
Q4. 個人情報保護(GDPRや改正個人情報保護法)への対応はどうすればよいですか?
A. BigQuery にデータを保存する際は、メールアドレスや電話番号などの個人情報をそのまま入れず、ハッシュ化(SHA256等)して保存するのが一般的です。また、Google Cloud の IAM 権限設定により、特定のデータセットに対してアクセスできるユーザーを厳格に制限することが可能です。
Q5. Google 広告の「管理画面」と「BigQuery」の数値がわずかにズレるのですが?
A. 完全に一致させるのは困難ですが、主な要因は「タイムゾーンの設定」と「無効なクリックの除外タイミング」の差です。BigQuery に転送されるデータは、特定のタイミングでのスナップショットであるため、管理画面側で後日行われる微調整(無効トラフィックの払い戻し等)が反映されるまでにラグが生じます。1〜2%程度の誤差は許容範囲として運用するのが実務上の落とし所です。
Q6. アドバンスド コンバージョン(Enhanced Conversions)のデータも取得できますか?
A. はい、DTS を通じて取得可能です。ただし、アドバンスド コンバージョンはプライバシーに配慮してハッシュ化された状態で受け渡されるため、BigQuery 側で自社の顧客データと照合(名寄せ)する際も、同じハッシュ化ロジックを用いて結合する必要があります。
まとめ:データ統合が「広告運用」を「経営戦略」に変える
Google 広告と BigQuery の連携は、単なるレポート作成の自動化ではありません。それは、デジタル広告という「点」の施策を、事業全体の収益性という「面」の戦略へと昇華させるための土台作りです。
本記事で紹介した DTS による 10 ステップの構築は、DX の第一歩に過ぎません。その先には、CRM 連携による LTV 最適化や、機械学習を用いた予測入札など、競合が容易に真似できない高度なマーケティング基盤が待っています。まずは自社の Google 広告アカウントと Google Cloud プロジェクトを紐付けることから始めてみてください。蓄積されたデータが、半年後、一年後の意思決定の質を劇的に高めてくれるはずです。
参考文献・出典
- Google Cloud:BigQuery Data Transfer Service による Google 広告のデータ転送 — https://cloud.google.com/bigquery/docs/google-ads-transfer?hl=ja
- Google Developers:Google Ads API 概要 — https://developers.google.com/google-ads/api/docs/start?hl=ja
- Google Cloud 事例:メルカリ、BigQuery ML で広告入札を最適化 — https://cloud.google.com/blog/topics/customers/mercari-bigquery-ml-ads-optimization?hl=ja
- Google Cloud 導入事例:株式会社リクルート — https://cloud.google.com/customers/recruit?hl=ja
- Google 広告ヘルプ:データの確定と反映までの時間 — https://support.google.com/google-ads/answer/2544985?hl=ja
- Google Cloud:BigQuery の料金体系 — https://cloud.google.com/bigquery/pricing?hl=ja
- Google Cloud:BigQuery Data Transfer Service でサポートされるリージョン — https://cloud.google.com/bigquery/docs/locations?hl=ja
- Google 広告ヘルプ:MCC アカウントとデータ共有の仕組み — https://support.google.com/google-ads/answer/6139186?hl=ja
- Google Cloud:BigQuery におけるデータの重複排除テクニック — https://cloud.google.com/architecture/database-replication-to-bigquery-using-change-data-capture?hl=ja
- Google 広告 API:通貨単位 Micros についての仕様 — https://developers.google.com/google-ads/api/docs/concepts/money?hl=ja
導入前に押さえるべきコスト構造と設定の落とし穴
BigQuery Data Transfer Service(DTS)を用いた連携は、設定自体は容易ですが、運用コストとデータの仕様に関する「事前の理解」が不足していると、予期せぬトラブルを招くことがあります。特に、無料枠の範囲とデータの鮮度については、エンジニアだけでなくマーケティング担当者も把握しておく必要があります。
DTS利用における料金体系の再確認
Google 広告から BigQuery へのデータ転送自体は「無料」ですが、データが格納される BigQuery 側のストレージ料金と、その後の分析(クエリ)料金が発生します。また、バックフィル(過去データの再取得)についても、Google 広告コネクタの場合は基本的に無料ですが、転送先となるリージョンやデータ量によっては操作ミスによるクエリコスト増大に注意が必要です。
| チェック項目 | 詳細・注意点 | 公式サイト・ヘルプ |
|---|---|---|
| DTS転送手数料 | Google 広告コネクタは無料(2026年4月時点) | DTS 料金の詳細 |
| 最小同期インターバル | DTSの標準スケジュールは「24時間に1回」が基本 | 転送設定ガイド |
| データ保持期間 | デフォルトでは無期限だが、コスト最適化のためにパーティションの有効期限設定を要確認 | パーティション分割テーブル |
よくある誤解:コンバージョンデータの「動的変化」
「一度転送されたデータは不変である」という思い込みは、分析結果の乖離を生む最大の原因です。Google 広告のコンバージョンは、クリックから数日〜数週間遅れて発生(あるいはキャンセル・修正)されるため、DTSの設定で「データの再試行ウィンドウ(Lookback Window)」を適切に設定していないと、過去の欠損データが埋まらないまま確定値として扱われてしまいます。実務上は、少なくとも過去7日〜14日分を毎日上書き更新するように構成するのが一般的です。
このような「データの鮮度」と「コスト」のバランス設計は、広告運用だけでなく、CRMやSFAを統合した全体設計においても極めて重要です。詳細は、高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例でも解説しています。
データ活用を「自動化」から「施策連動」へ進化させる
BigQueryにデータを集約する最終的な目的は、単なる可視化ではなく、「広告運用の自動最適化(CAPI連携など)」や「ユーザー行動に応じたリアルタイム配信」への昇華です。例えば、BigQuery上で算出したLTVスコアを、リバースETL(CensusやHightouch等)を用いてGoogle 広告の「カスタマーマッチ」へ戻すことで、高精度なターゲティングが可能になります。
- CAPI(コンバージョンAPI)との連携: Cookie規制下において、サーバーサイドからBigQuery経由でコンバージョン信号を送り返すアーキテクチャの構築。
- 行動トリガー配信: 特定のクエリに合致したユーザー群を抽出し、LINEやメールへ即時反映させる仕組み。
特にLINEを活用した高度なCRM施策については、高額MAツールは不要。BigQueryとリバースETLで構築する「行動トリガー型LINE配信」の完全アーキテクチャが、データ基盤を直接ビジネス成果に結びつけるための具体的な技術指針となります。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。