プレゼン品質チェックを自動化
📥 関連ガイドをダウンロード
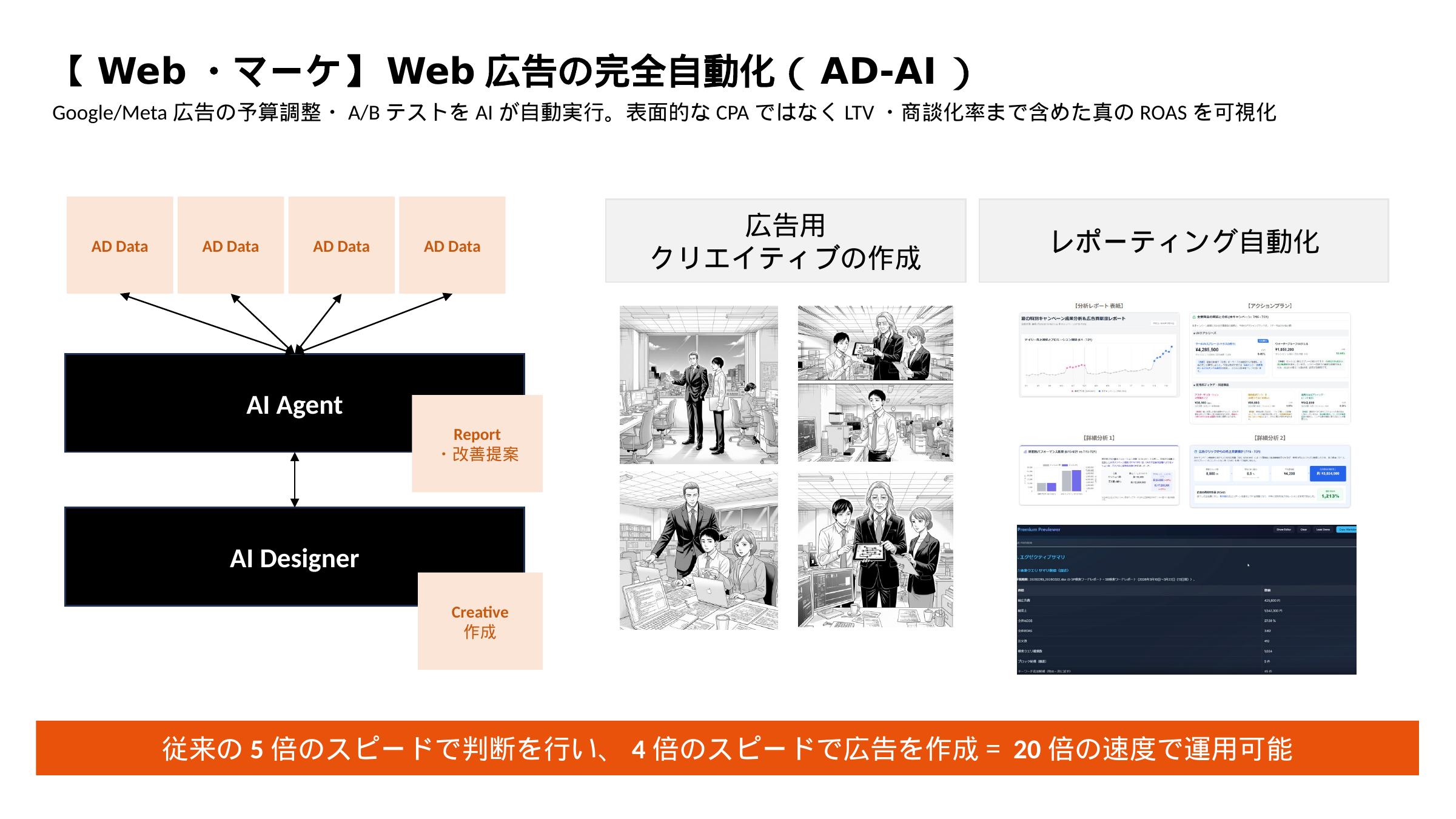
クライアントへの提案書、IR資料、社内報告書など、重要なプレゼン資料を社外・上位者に提出する前のチェック作業は時間がかかります。ブランドカラーの統一確認、テキスト量の適切さ、誤字脱字、重複スライドの有無――これらをすべて目視でチェックするには、100枚のデッキで半日以上かかることも珍しくありません。Claude Code + python-pptx を使えば、このチェック作業を30秒で完了させることができます。
このアプローチの核心は 「品質基準をコードとして定義する」 ことです。ブランドガイドラインに記載された承認カラーパレット・フォント・テキスト量のルールをPythonの条件式として実装することで、チェック基準が完全に客観化・再現可能になります。「Aさんはチェックが甘い、Bさんは厳しい」という属人的な品質ばらつきがなくなります。
- デッキのブランドガイドライン準拠確認に毎回時間がかかっている
- テキスト過多のスライドが多く、受け手に伝わらないと指摘を受けている
- 古いバージョンのスライドが混入するミスを防ぎたい
- チェック担当者によって品質基準がばらつく問題を解消したい
社内のプレゼン品質を保つためには、フォント・色・レイアウトのガイドライン準拠を確認する必要があります。Claude Code + python-pptx でこれを完全自動化します。
ステップ1:ブランドガイドライン違反を自動検出
準拠しているか自動チェックするスクリプトを作成して
from pptx import Presentation
from pptx.util import Pt
prs = Presentation("提出資料.pptx")
ALLOWED_FONTS = {"Meiryo UI", "HGPゴシックM", "Calibri", "Arial"}
violations = []
for i, slide in enumerate(prs.slides, 1):
for shape in slide.shapes:
if not shape.has_text_frame:
continue
for para in shape.text_frame.paragraphs:
for run in para.runs:
font_name = run.font.name
if font_name and font_name not in ALLOWED_FONTS:
violations.append(
f"スライド{i}: 非推奨フォント '{font_name}' "
f"(テキスト: '{run.text[:20]}')"
)
print(f"フォント違反: {len(violations)}件")
for v in violations[:10]:
print(f" {v}")20スライド中7箇所でフォント違反を検出。手動確認(30分)がスクリプト実行3秒に。
ステップ2:テキスト過多スライドを自動検出
from pptx import Presentation
prs = Presentation("提出資料.pptx")
MAX_WORDS = 150
dense_slides = []
for i, slide in enumerate(prs.slides, 1):
total_text = ""
for shape in slide.shapes:
if shape.has_text_frame:
total_text += shape.text_frame.text + " "
word_count = len(total_text.split())
if word_count > MAX_WORDS:
dense_slides.append((i, word_count))
print(f"テキスト過多スライド: {len(dense_slides)}枚")
for slide_num, count in dense_slides:
print(f" スライド{slide_num}: {count}語(上限{MAX_WORDS}語)")テキスト過多スライドを自動検出。情報詰め込み過ぎのスライドを即特定。
テキスト過多の検出は「1スライドあたりの文字数」だけでなく、「テキストボックスの数」「フォントサイズ10pt以下のテキスト比率」も合わせてチェックすることでより精度が上がります。コンサルティングファームのデッキ標準に基づくと、1スライドあたりの推奨テキスト量は「見出し1行+本文5行以内・各行20字以内」が目安とされています。このルールをスクリプトに組み込むことで、スライドの「読みやすさ」を数値化して評価できます。
ステップ3:空白スライド・重複スライドを自動検出
from pptx import Presentation
prs = Presentation("提出資料.pptx")
issues = []
slide_texts = []
for i, slide in enumerate(prs.slides, 1):
text = " ".join(
shape.text_frame.text
for shape in slide.shapes if shape.has_text_frame
).strip()
if not text:
issues.append(f"スライド{i}: 空白スライド")
if text in slide_texts:
issues.append(f"スライド{i}: 重複スライド(テキストが同一)")
slide_texts.append(text)
print(f"構成問題: {len(issues)}件")
for issue in issues:
print(f" {issue}")空白・重複スライドを自動検出。提出前の最終チェックが完全自動化。
重複スライドの検出では、各スライドのテキスト内容をハッシュ化して比較することで、完全一致の重複を高速に検出できます。「ほぼ同一」の類似スライド検出には、difflib.SequenceMatcher を使った類似度計算(0〜1のスコア)を活用します。類似度0.9以上のスライドが複数ある場合は「重複の可能性あり」として警告を出すことで、誤って古いバージョンのスライドが混入するミスを防止できます。
ステップ4:品質レポートをExcelで自動出力
import openpyxl
from pptx import Presentation
from openpyxl.styles import PatternFill, Font
RED = PatternFill("solid", fgColor="FFE0E0")
GREEN = PatternFill("solid", fgColor="E0FFE8")
wb = openpyxl.Workbook()
ws = wb.active
ws.append(["スライド番号","テキスト量","フォント違反数","問題あり"])
prs = Presentation("提出資料.pptx")
for i, slide in enumerate(prs.slides, 1):
text_len = sum(
len(s.text_frame.text)
for s in slide.shapes if s.has_text_frame
)
font_violations = sum(
1 for s in slide.shapes if s.has_text_frame
for p in s.text_frame.paragraphs
for r in p.runs
if r.font.name and r.font.name not in {"Meiryo UI","HGPゴシックM","Calibri"}
)
has_issue = text_len > 500 or font_violations > 0
row = ws.append([i, text_len, font_violations, "要修正" if has_issue else "OK"])
if has_issue:
for cell in ws[ws.max_row]:
cell.fill = RED
else:
ws.cell(ws.max_row, 4).fill = GREEN
wb.save("品質チェックレポート.xlsx")
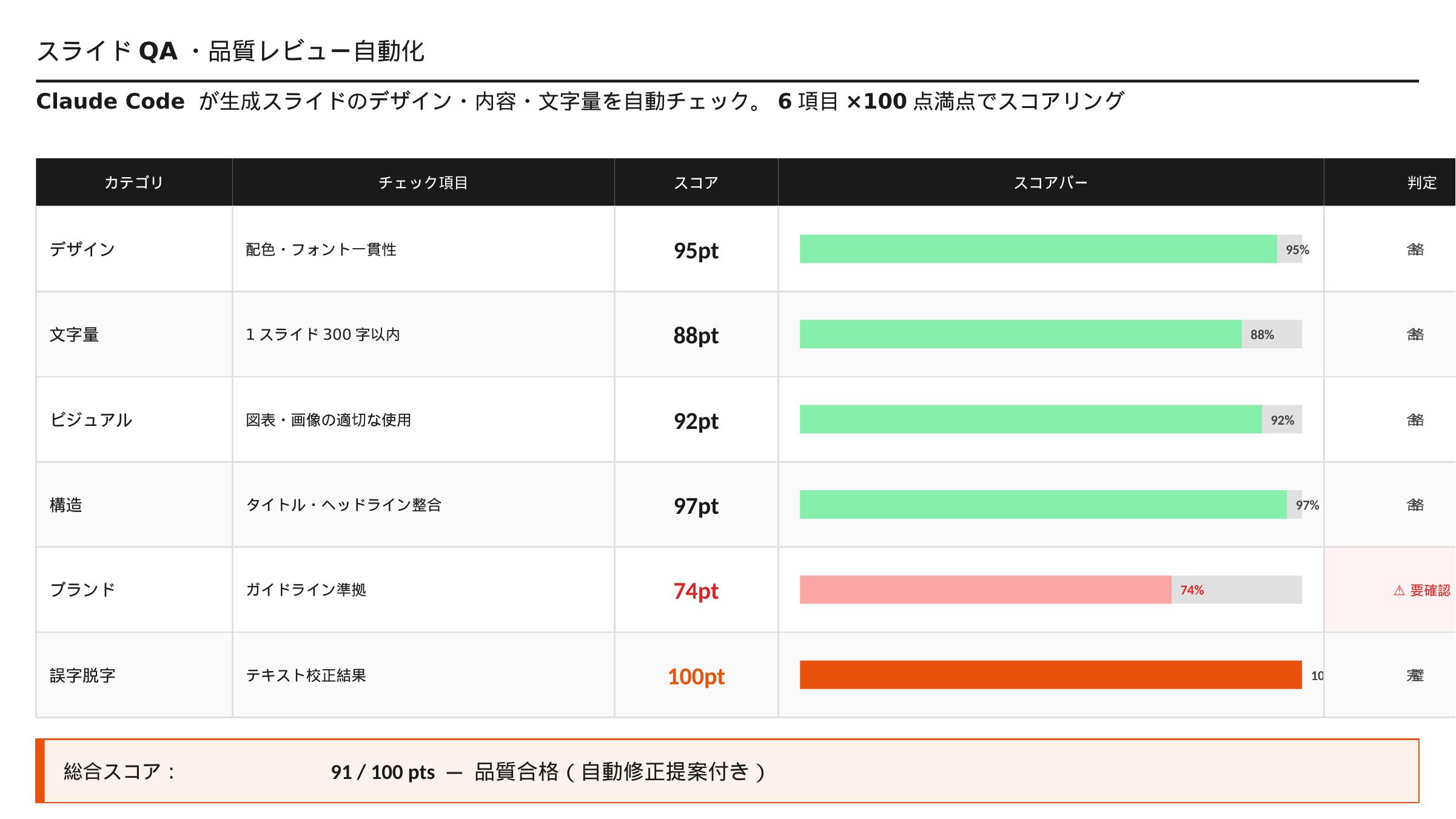
print("品質チェックレポート生成完了")スライドごとの品質スコアをExcelレポートで自動出力。問題箇所が赤ハイライトで一目瞭然。
Excelの品質レポートは、openpyxl の条件付き書式を使ってNG項目のセルを赤くハイライトすることで、視認性を高められます。さらにスライドのサムネイル画像をExcelに埋め込む(openpyxl.drawing.image.Image)ことで、問題のあるスライドを見ながら修正作業を進めることが可能になります。レポートはPDFとして出力してレビュー担当者にメール送信まで自動化することで、完全なレビューパイプラインが完成します。
実務での活用シナリオ
このスクリプトを実際の業務にどう活用するか、具体的なシーンをご紹介します。
- コーポレートデッキ審査:IR・採用・営業デッキのブランドガイドライン準拠を自動チェック。デザイナー不在でも品質担保。
- 社内資料標準化:各部門から集まった提案書・報告書のフォント・色・レイアウトを自動統一。
- コンサルティングファーム:クライアント提出前のデッキ品質チェックを自動化。テキスト過多スライドを即検出。
- 教育機関:学生・教員が提出するスライドの基準適合チェックを自動化。採点の客観性向上。
- 出版・印刷:入稿前のスライドデータの品質検査を自動化。色空間・解像度・フォント埋め込みを確認。
導入前後の効果比較
プレゼン提出前にデザイン担当者や上長が目視チェック。100枚超のデッキのチェックに半日以上かかる上、見落としも発生。担当者によってチェック基準がばらつく問題もあった。
スクリプト実行でブランドカラー違反・テキスト過多・空白スライドを秒速で検出。Excelに品質レポートが自動出力され、修正箇所が一目でわかる。チェック作業が10分→30秒に。
導入のポイントと注意事項
- ブランドカラーの許容範囲は±10程度のRGB誤差を設定することで、モニターキャリブレーション差異による誤検知を防ぐ
- テキスト過多の閾値(例:1スライド200字超)はプレゼンの用途に合わせて調整する
- 初回実行時は既存スライドでテストして、誤検知率を確認してから本番運用へ移行する
- 品質レポートにはスライド番号だけでなく、サムネイル画像も添付すると修正作業が効率的になる
業務システム・DX全般のご相談
業務の課題整理からツール選定、システム導入・連携・運用までを幅広く支援します。何から手をつけるべきか迷う段階でも、貴社の状況に合わせて最適な進め方をご提案します。
よくある質問(FAQ)
まとめ:プレゼン品質チェック自動化で得られる効果
✅ ブランドカラー・フォント違反を 自動検出(デザイン品質を客観的に担保)
✅ テキスト過多スライドを 即座に特定(改善箇所の見落としゼロ)
✅ 空白・重複スライドを 自動排除(誤って古いバージョンが混入するリスクを防止)
✅ 品質レポートを Excel自動出力(チェック結果の共有が容易)
プレゼンのレビュー工数を「1デッキあたり半日」から「30秒」に短縮します。デザイナー不在のチームでも一定の品質水準を自動で担保できるため、「ブランドイメージを崩すスライドが社外に出てしまう」リスクを大幅に低減できます。
さらに発展させて、「スライドのデザイン自動修正」(ブランドカラー・フォントを自動置換)や「AIによるコンテンツ品質評価」(メッセージの明確さ・論理構成のチェック)と組み合わせることで、完全な「プレゼン品質管理パイプライン」を構築できます。
関連記事