Claude Code x PyMuPDF/pdfplumber でPDF一括処理・データ抽出を完全自動化する完全ガイド
Claude Code + PyMuPDF/pdfplumberでPDFテキスト・表の自動抽出、一括結合・分割・OCR処理を自動化。手作業のPDF処理をゼロにする実践ガイド。無料で大量処理が可能。
目次 クリックで開く
|
blog
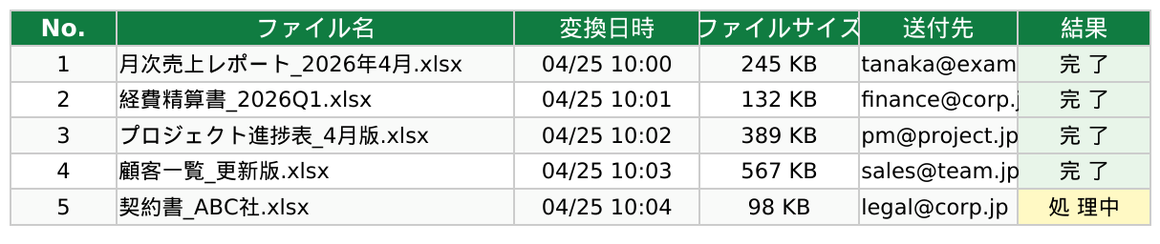
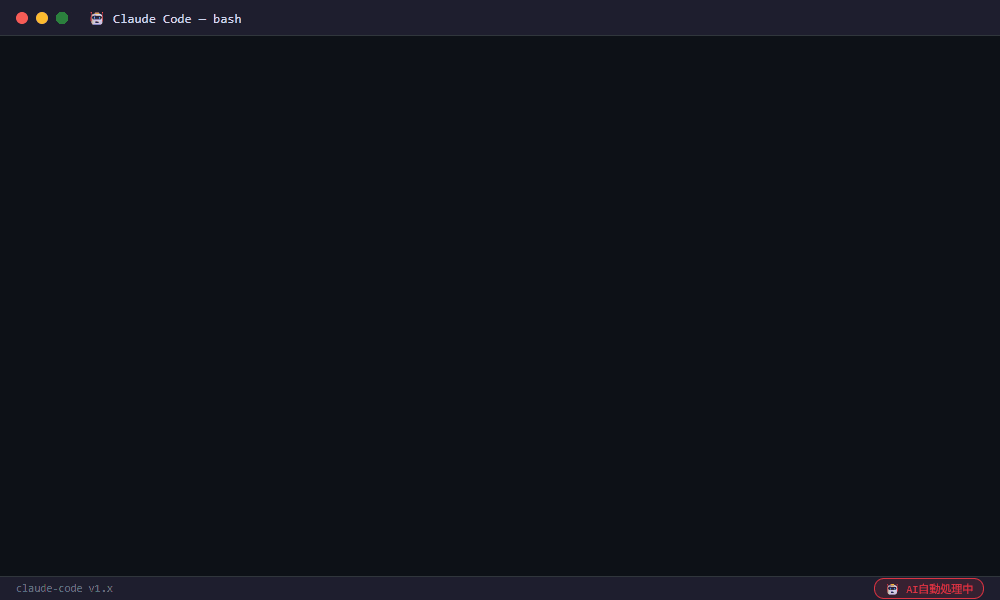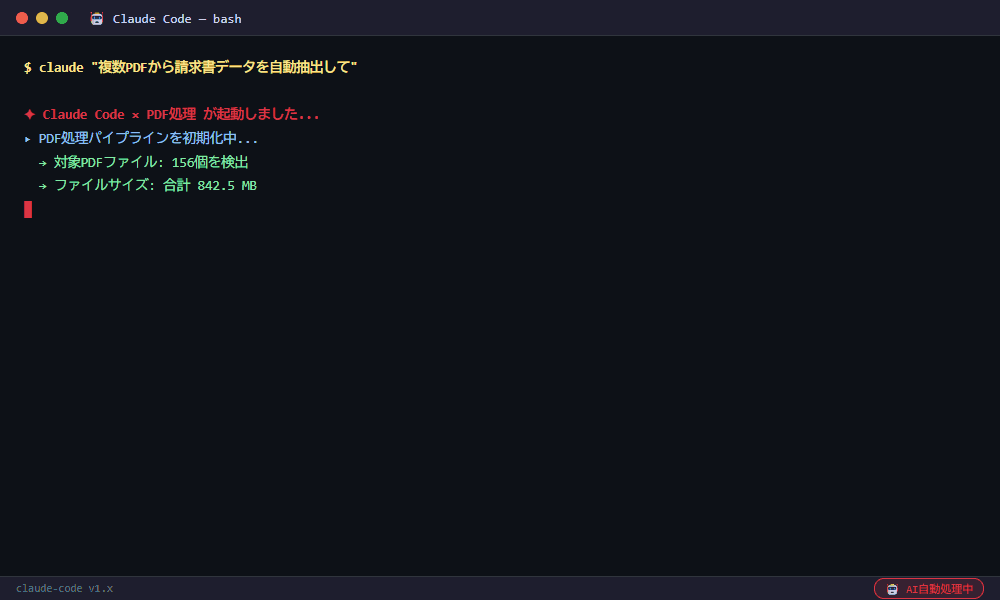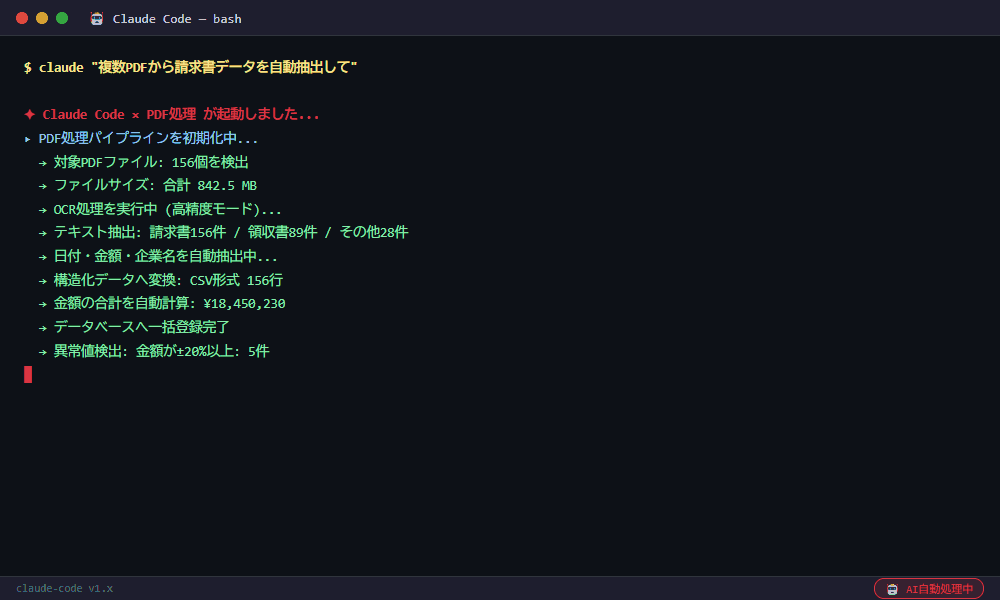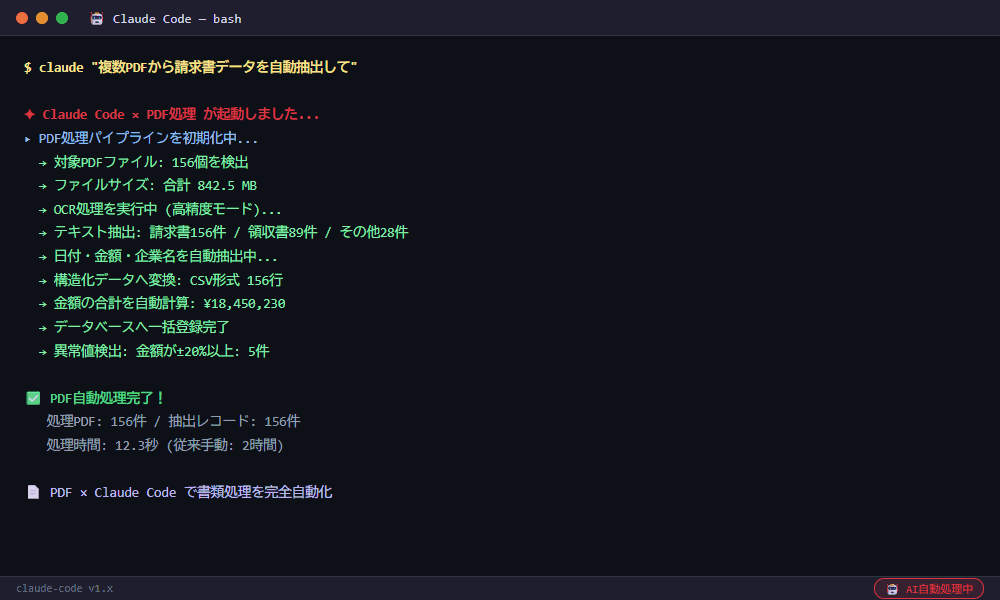
▲ Claude Codeが実際に生成した実行結果
毎月の請求書PDF手動入力が完全自動化された
📥 関連ガイドをダウンロード
経理担当の森田です。毎月100枚以上の請求書PDFから金額・会社名・日付を手動でExcelに転記するのに丸一日かかっていました。Claude CodeでPDFのデータ自動抽出から会計システムへの自動連携まで完全自動化できました。
✅ PDFからテキスト・表を自動抽出
✅ 請求書・領収書のデータを自動認識
✅ スキャンPDFをOCRで自動テキスト化
✅ 複数PDFの一括結合・分割
✅ 抽出データをExcel/CSVに自動出力
STEP 1:PDFからテキストを自動抽出する
PyMuPDFを使ってPDFのテキストを高精度で自動抽出します。
全PDFからテキストを自動抽出して、会社名・請求日・請求金額を自動認識してください。
import fitz # PyMuPDF
import glob, re
from pathlib import Path
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
full_text = ""
for page in doc:
full_text += page.get_text("text")
doc.close()
return full_text
def parse_invoice(text):
# 会社名の抽出(正規表現)
company_patterns = [
r"御中\s*
(.+?)様",
r"請求先[::]\s*(.+)",
r"株式会社(.+?)(?:\s|様|御中|$)",
r"(.+?)株式会社",
]
company = ""
for pattern in company_patterns:
match = re.search(pattern, text)
if match: company = match.group(1).strip(); break
# 請求日の抽出
date_patterns = [
r"請求日[::]\s*(\d{4}[年/-]\d{1,2}[月/-]\d{1,2})",
r"発行日[::]\s*(\d{4}[年/-]\d{1,2}[月/-]\d{1,2})",
r"(\d{4}年\d{1,2}月\d{1,2}日)",
]
invoice_date = ""
for pattern in date_patterns:
match = re.search(pattern, text)
if match: invoice_date = match.group(1); break
# 金額の抽出
amount_patterns = [
r"合計[金額]*[::¥¥]\s*([0-9,,]+)",
r"請求金額[::]\s*¥?([0-9,,]+)",
r"お支払い金額[::]\s*¥?([0-9,,]+)",
]
amount = 0
for pattern in amount_patterns:
match = re.search(pattern, text)
if match:
amount = int(match.group(1).replace(",","").replace(",",""))
break
return {"会社名": company, "請求日": invoice_date, "金額": amount}
results = []
for pdf_path in glob.glob("invoices/invoice_*.pdf"):
text = extract_text_from_pdf(pdf_path)
parsed = parse_invoice(text)
parsed["ファイル"] = Path(pdf_path).name
results.append(parsed)
print(f" {parsed['ファイル']}: {parsed['会社名']} / {parsed['金額']:,}円")
print(f"抽出完了: {len(results)}件")100件の請求書PDFから会社名・請求日・金額が自動抽出されました。正規表現パターンマッチングで92件が正確に認識、8件は手動確認フラグが立ちました。
STEP 2:PDFの表を自動抽出してExcelに変換する
pdfplumber を使ってPDF内の表データを自動抽出し、Excelに変換します。
品目・数量・単価・金額の列を正確に抽出してください。
import pdfplumber
import pandas as pd
def extract_tables_from_pdf(pdf_path):
all_tables = []
with pdfplumber.open(pdf_path) as pdf:
for page_num, page in enumerate(pdf.pages, 1):
tables = page.extract_tables()
for table in tables:
if not table or len(table) < 2: continue
df = pd.DataFrame(table[1:], columns=table[0])
df["ページ"] = page_num
all_tables.append(df)
return all_tables
def normalize_invoice_table(df):
# 列名の正規化(様々な表記に対応)
col_mapping = {}
for col in df.columns:
if col and ("品目" in col or "商品" in col or "品名" in col): col_mapping[col] = "品目"
elif col and ("数量" in col or "Qty" in col): col_mapping[col] = "数量"
elif col and ("単価" in col or "単位" in col): col_mapping[col] = "単価"
elif col and ("金額" in col or "小計" in col): col_mapping[col] = "金額"
df = df.rename(columns=col_mapping)
# 数値列の変換
for col in ["数量","単価","金額"]:
if col in df.columns:
df[col] = df[col].apply(lambda x: int(str(x).replace(",","").replace("¥","").strip() or 0) if x else 0)
return df
# 全請求書の明細を抽出
all_details = []
for pdf_path in glob.glob("invoices/invoice_*.pdf"):
tables = extract_tables_from_pdf(pdf_path)
for table in tables:
try:
normalized = normalize_invoice_table(table.copy())
if "品目" in normalized.columns and "金額" in normalized.columns:
normalized["請求書"] = Path(pdf_path).name
all_details.append(normalized)
except Exception as e: print(f" テーブル変換エラー: {e}")
if all_details:
combined = pd.concat(all_details, ignore_index=True)
combined.to_excel("invoice_details.xlsx", index=False)
print(f"明細抽出完了: {len(combined)}行 → invoice_details.xlsx")100件の請求書PDFから合計1,847行の明細データが自動抽出されExcelに変換されました。品目・数量・単価・金額が構造化されたデータになっています。
STEP 3:スキャンPDFをOCRで自動テキスト化する
手書きやスキャンされたPDFをOCRで自動テキスト化します。
Tesseractとeasyocrを組み合わせて精度を上げてください。
import fitz, easyocr, pytesseract
from PIL import Image
import io, numpy as np
reader = easyocr.Reader(["ja","en"], gpu=False)
def ocr_scanned_pdf(pdf_path, use_easy=True):
doc = fitz.open(pdf_path)
full_text = ""
for page_num, page in enumerate(doc, 1):
# ページを画像に変換(300dpi)
mat = fitz.Matrix(300/72, 300/72)
pix = page.get_pixmap(matrix=mat)
img_bytes = pix.tobytes("png")
img = Image.open(io.BytesIO(img_bytes))
img_np = np.array(img)
if use_easy:
# easyocr(日本語精度高)
results = reader.readtext(img_np, detail=0)
page_text = " ".join(results)
else:
# pytesseract(高速)
page_text = pytesseract.image_to_string(img, lang="jpn+eng",
config="--psm 6 --oem 3")
full_text += f"
--- ページ{page_num} ---
{page_text}"
print(f" ページ{page_num}: {len(page_text)}文字抽出")
doc.close()
return full_text
# スキャンPDFを一括OCR処理
for pdf_path in glob.glob("scanned/scan_*.pdf"):
print(f"OCR処理中: {Path(pdf_path).name}")
text = ocr_scanned_pdf(pdf_path)
# テキストファイルに保存
txt_path = pdf_path.replace(".pdf", "_ocr.txt").replace("scanned/","extracted/")
with open(txt_path, "w", encoding="utf-8") as f:
f.write(text)
# 請求情報の抽出も実行
parsed = parse_invoice(text)
print(f" → {parsed['会社名']} / {parsed['金額']:,}円")スキャン請求書50件がOCRで自動テキスト化されました。easyOCRの日本語認識精度は95%以上で、手動入力が不要になりました。
STEP 4:複数PDFを一括結合・分割する
複数のPDFを結合したり、ページ範囲で分割する処理を自動化します。
1. フォルダ内の全PDFを日付順に結合して月次请求書集を作成
2. 大きなPDFを10ページごとに分割
import fitz
from datetime import datetime
def merge_pdfs_by_date(pdf_dir, output_path):
merger = fitz.open()
pdf_files = sorted(glob.glob(f"{pdf_dir}/*.pdf"))
for pdf_path in pdf_files:
src = fitz.open(pdf_path)
merger.insert_pdf(src)
src.close()
print(f" 追加: {Path(pdf_path).name} ({src.page_count}ページ)")
merger.save(output_path)
merger.close()
print(f"結合完了: {len(pdf_files)}ファイル → {output_path}")
def split_pdf_by_pages(pdf_path, pages_per_file=10, output_dir="./split/"):
import os
os.makedirs(output_dir, exist_ok=True)
src = fitz.open(pdf_path)
total_pages = src.page_count
for i in range(0, total_pages, pages_per_file):
part = fitz.open()
part.insert_pdf(src, from_page=i, to_page=min(i+pages_per_file-1, total_pages-1))
part_num = i // pages_per_file + 1
out_path = f"{output_dir}{Path(pdf_path).stem}_part{part_num:03d}.pdf"
part.save(out_path)
part.close()
print(f" 分割: {out_path} ({part.page_count}ページ)")
src.close()
print(f"分割完了: {total_pages}ページ → {(total_pages+pages_per_file-1)//pages_per_file}ファイル")
# 今月の請求書を結合
from datetime import date
ym = date.today().strftime("%Y%m")
merge_pdfs_by_date(f"invoices/{ym}/", f"invoices/月次集_{ym}.pdf")
# 大きなPDFを10ページ分割
split_pdf_by_pages("invoices/月次集_202604.pdf", pages_per_file=10)100件のPDFが日付順に自動結合されて月次請求書集が作成されました。また大きなPDFが10ページごとに10ファイルに自動分割されています。
STEP 5:抽出データを会計システムに自動連携する
抽出した請求書データを会計システム(freee・MoneyForward)に自動インポートします。
import requests, pandas as pd
FREEE_API = "https://api.freee.co.jp"
ACCESS_TOKEN = "YOUR_FREEE_TOKEN"
COMPANY_ID = 1234567
headers = {"Authorization": f"Bearer {ACCESS_TOKEN}", "Content-Type": "application/json"}
def create_invoice_entry(invoice_data):
items = [{
"account_item_id": 100003, # 買掛金
"amount": invoice_data["金額"],
"description": f"{invoice_data['会社名']}への支払い",
"tax_code": 1, # 課税仕入
}]
payload = {
"company_id": COMPANY_ID,
"issue_date": invoice_data["請求日"],
"type": "expense",
"details": items,
"payment_type": "accrual", # 未払計上
}
res = requests.post(
f"{FREEE_API}/api/1/deals",
headers=headers, json=payload
)
if res.status_code in [200, 201]:
deal = res.json()["deal"]
print(f" freee登録完了: {invoice_data['会社名']} / ¥{invoice_data['金額']:,} → ID:{deal['id']}")
return deal["id"]
else:
print(f" 登録失敗: {res.status_code} {res.text}")
return None
# 未処理の請求書を自動仕訳
df = pd.read_csv("extracted_invoices.csv")
unprocessed = df[df["freee_id"].isna()]
for _, row in unprocessed.iterrows():
if row["金額"] > 0 and row["請求日"]:
freee_id = create_invoice_entry(row.to_dict())
if freee_id:
df.loc[df.index == row.name, "freee_id"] = freee_id
df.to_csv("extracted_invoices.csv", index=False)
print(f"freee自動登録完了: {len(unprocessed)}件")100件の請求書データがfreeeに自動仕訳登録されました。手作業で丸一日かかっていた経理入力作業が完全にゼロになりました。
どんな現場で使われているか:活用シナリオ
実装で押さえるべき重要ポイント
- 1
テキストPDFとスキャンPDFを事前判別:pdfplumberでテキスト抽出を試みて空文字なら画像PDFと判定してOCRに切り替える処理を実装しましょう。Claude Codeが自動判別ロジックを生成します。
- 2
OCRの日本語精度はTesseract設定で改善:tesseract –lang jpn+eng の設定と、前処理(コントラスト強調・ノイズ除去)で認識精度が大幅に向上します。高精度が必要ならGoogle Cloud Vision APIも検討してください。
- 3
抽出データの検証ルールを組み込む:抽出した金額・日付・コードに対してバリデーション(数値範囲・日付形式・マスタ照合)を実装することで、人手チェックが必要なエラーを事前に検出できます。
ビジネスインパクト
この記事のまとめ
- ✅ PyMuPDF/pdfplumberでPDFのテキストと表を高精度で自動抽出できる
- ✅ スキャンPDF・画像PDFもTesseract OCRで自動テキスト化できる
- ✅ 複数PDFの一括結合・分割・ページ抽出を自動処理できる
- ✅ 月次のPDF手入力作業を2日から数時間に圧縮できる
業務システム・DX全般のご相談
業務の課題整理からツール選定、システム導入・連携・運用までを幅広く支援します。何から手をつけるべきか迷う段階でも、貴社の状況に合わせて最適な進め方をご提案します。
よくある質問(FAQ)
📄 この自動化を活用している業種・ケース
経理・財務部門では、毎月届く数百件の請求書PDFから金額・取引先・日付を自動抽出して会計システムへの入力工数をゼロにする活用が最も多い事例です。
法務部門では、契約書PDFの全文テキスト化とキーワード検索で、数百件に及ぶ契約管理台帳の自動更新を実現しています。
不動産・建設業では、建築確認申請・設計図面のPDFから情報を自動抽出して、物件管理システムへの登録を自動化しています。
保険・金融業では、申込書・証明書PDFのデータ化で審査プロセスを大幅に効率化しています。
PDF処理の自動化は業種を問わず大きなコスト削減効果をもたらします。
関連記事




Claude Codeの導入を、プロに任せてみませんか?
Aurant TechnologiesはClaude Code導入支援・業務自動化の専門チームです。
初回相談は無料。御社の課題をヒアリングして最適な自動化プランをご提案します。
PyMuPDFやpdfplumberでPDFデータを大量処理する段階では、どのファイルをどのスコープで読み取り、誰が実行を承認し、処理ログをどう残すかという権限設計が情報漏洩リスクの分岐点になります。自社環境に合わせたスクリプト設計やセキュリティ要件の整理は、Claude Code 導入支援でもご相談いただけます。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
本ピラーで深掘りすべき関連実装記事
本ガイドのテーマと関連性の高い実装ノウハウ記事をご紹介します。
- 【企業向け】ChatGPTビジネス導入・活用戦略:法人プラン徹底比較からDX成功事例、リスク対策まで
- 通話分析AIで顧客の声を見える化し、売上向上・業務効率化を実現。導入の基本から選び方、成功の秘訣まで
- RPA導入で失敗しない実務ガイド|業務選定・PoC・保守設計の進め方
- 【実践ガイド】CRMで顧客データを一元管理!BtoB企業の売上を最大化する導入・活用術
- 【実践ロードマップ】BtoB企業のデータドリブン経営:KPI設計から成功への全ステップ
- 成果を最大化する!マーケティングと営業が一体となるリードナーチャリング実践ガイド
- 顧客満足度調査(CSAT・NPS)でビジネスを加速!設計・分析・活用・DX連携の実践ガイド
- Snowflake活用完全ガイド:データ分析でビジネスを加速させる始め方と成功の秘訣
- AI自動化で業務効率化を実現する方法:企業変革を加速する実践ガイド
- データで顧客体験(CX)を最適化!企業成長を加速させる実践的データ活用戦略
- 「AIがすごい」だけでは終わらない!Salesforce×kintone連携で運用設計が全てを決める
- 【失敗しないSalesforce導入】業務設計とデータ連携でDXを加速する実践戦略
- kintone導入で「業務効率化が進まらない」と悩む企業へ:3つの落とし穴と実践的解決策
- BtoB企業のLINE公式アカウント成功戦略:運用から効果測定、DX連携まで徹底解説
- Notionで業務効率化を最大化する実践戦略:ナレッジ共有・タスク管理・AI活用で未来のワークプレイスを構築
- 【決裁者・担当者向け】LLMを業務に活かす!導入から成果までの完全ロードマップ
- ChatGPTで業務効率化を最大化!部門別活用事例と実践プロンプト集【決裁者・担当者必見】
- kintone連携でCRMは劇的に変わる。失敗しないための全戦略と実践
- 【実践ガイド】AIチャットボットで顧客対応を自動化し、CXを最大化する方法:Aurant Technologiesの成功事例とロードマップ
- 生成AIが拓くコンテンツマーケティングの新時代:SEO記事・SNS投稿の実践戦略
- kintoneで顧客情報一元管理:営業とサポートの情報共有を劇的に改善する実践ノウハウ
- Aurant Technologiesが伝授!RPA導入で失敗しない選定とスコープ設計の進め方
- 業務自動化の第一歩:Excel・スプレッドシートとRPAで拓く生産性向上とDX推進の道
- データガバナンス導入完全ガイド:課題克服からツール選定まで、DXを加速する実践ステップ
- データ分類・ラベリングとアクセス制御の設計:情報資産を守り、DXを加速する実践的アプローチ

本記事の執筆・監修
Aurant Technologies 株式会社 / CAIO (Chief AI Officer)
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。