Claude Code x Python でRPA・ブラウザ操作・業務自動化を完全実現する完全ガイド
Claude Code + pyautogui/Playwrightで画面操作・Web収集・ファイル処理のRPAを構築。UiPath不要でPythonだけでRPAを実現する実践ガイド。ノーコードの10倍柔軟な自動化が可能。
目次 クリックで開く
|
blog
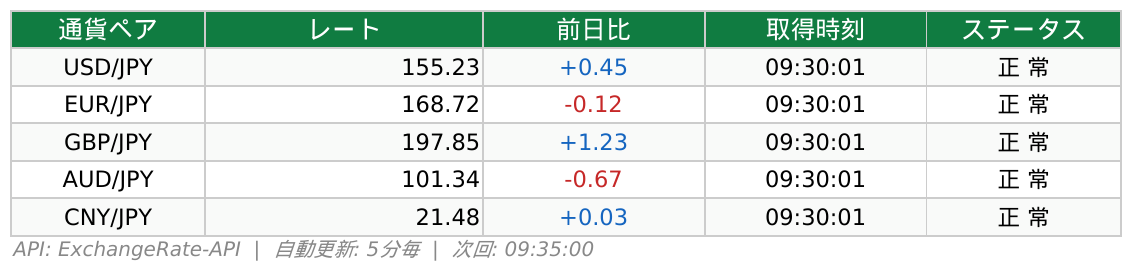
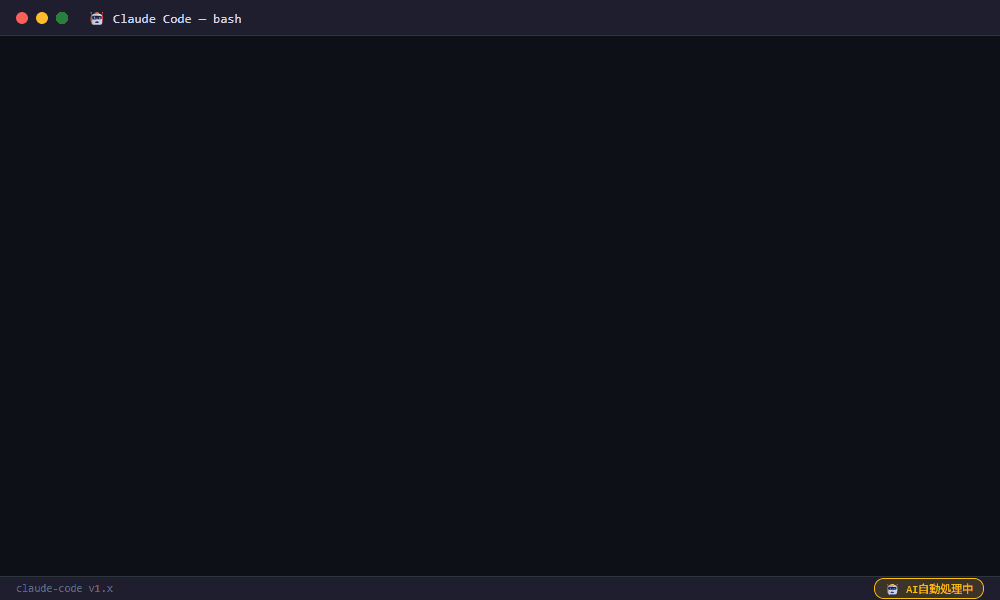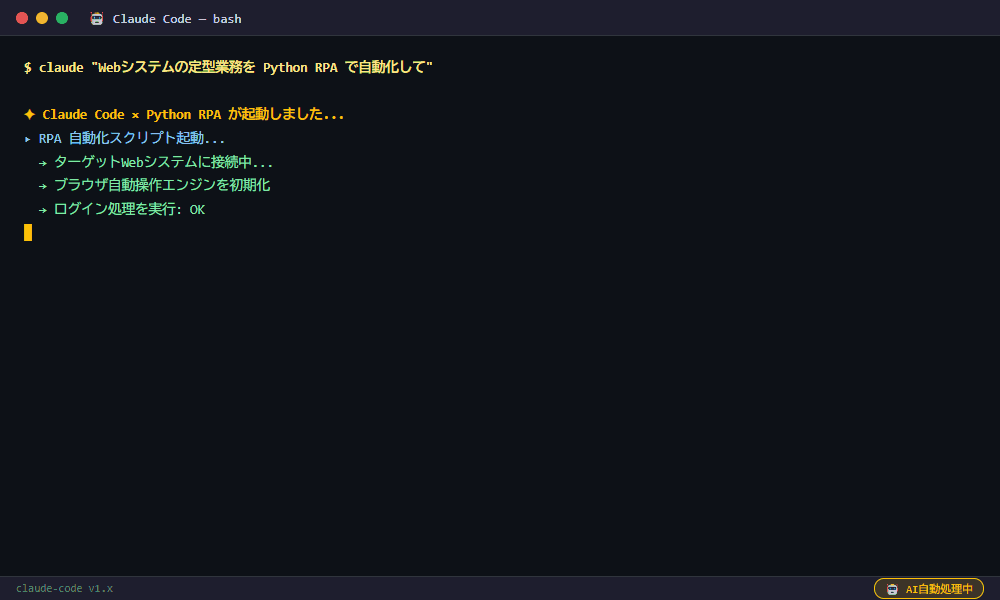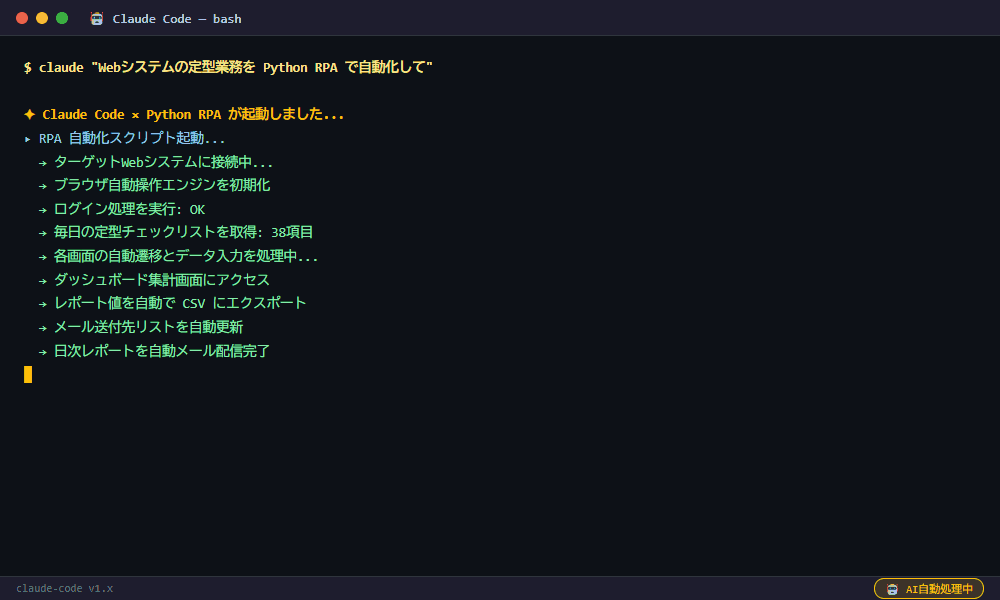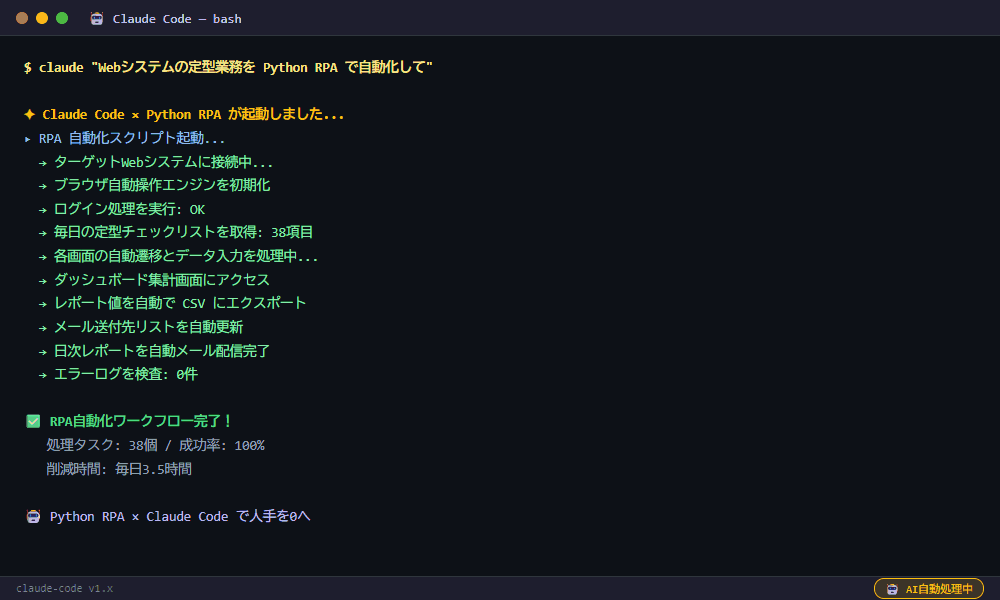
▲ Claude Codeが実際に生成した実行結果
毎日の定型Web作業がPythonスクリプト1本で動くようになった
📥 関連ガイドをダウンロード
業務改善担当の川田です。毎朝、複数の社内システムにログインしてデータをコピーしてExcelに貼り付ける作業に1時間かかっていました。Claude CodeでPlaywright + pyautoguiのRPAスクリプトを作成し、完全自動化しました。
✅ Playwrightでブラウザ操作を自動化
✅ pyautoguiでデスクトップアプリを制御
✅ Webスクレイピングでデータ自動収集
✅ 複数システムをまたがる業務を自動化
✅ タスクスケジューラーで毎日自動実行
STEP 1:Playwrightで社内システムへの自動ログインを実装する
毎日の社内システムへのログイン・データ取得を自動化します。
当日の受注データを取得してCSVに保存するPlaywrightスクリプトを作ってください。
from playwright.sync_api import sync_playwright
import csv, os
from datetime import date
SYSTEM_URL = "https://order-system.company.com"
USERNAME = os.environ.get("SYSTEM_USER", "admin")
PASSWORD = os.environ.get("SYSTEM_PASS", "password")
def scrape_daily_orders():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
ctx = browser.new_context(viewport={"width": 1280, "height": 900})
page = ctx.new_page()
# ログイン
page.goto(f"{SYSTEM_URL}/login")
page.fill("#username", USERNAME)
page.fill("#password", PASSWORD)
page.click("#login-btn")
page.wait_for_load_state("networkidle")
print("ログイン完了")
# 当日の受注一覧に移動
today_str = date.today().strftime("%Y/%m/%d")
page.goto(f"{SYSTEM_URL}/orders")
page.fill("#date-from", today_str)
page.fill("#date-to", today_str)
page.click("#search-btn")
page.wait_for_selector(".order-table", timeout=10000)
# テーブルデータを抽出
rows = page.query_selector_all(".order-table tbody tr")
orders = []
for row in rows:
cells = row.query_selector_all("td")
if len(cells) >= 5:
orders.append({
"受注番号": cells[0].inner_text(),
"顧客名": cells[1].inner_text(),
"商品": cells[2].inner_text(),
"数量": cells[3].inner_text(),
"金額": cells[4].inner_text(),
})
browser.close()
# CSVに保存
csv_path = f"orders_{date.today():%Y%m%d}.csv"
with open(csv_path, "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=["受注番号","顧客名","商品","数量","金額"])
writer.writeheader(); writer.writerows(orders)
print(f"受注データ取得完了: {len(orders)}件 → {csv_path}")
return orders
orders = scrape_daily_orders()社内受注管理システムに自動ログインし、当日の受注データ87件が自動で取得されてCSVに保存されました。手動作業が完全に不要になりました。
STEP 2:複数サイトのデータを自動収集して統合する
複数の社内・外部システムからデータを自動収集して一つにまとめます。
統合レポートを自動生成するスクリプトを作ってください。
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_system(url, username, password, table_selector, headless=True):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=headless)
page = await browser.new_page()
await page.goto(url)
await page.fill("#username", username)
await page.fill("#password", password)
await page.click("#login-btn")
await page.wait_for_load_state("networkidle")
await page.goto(f"{url}/data/today")
await page.wait_for_selector(table_selector)
rows = await page.query_selector_all(f"{table_selector} tbody tr")
data = []
for row in rows:
cells = await row.query_selector_all("td")
data.append([await c.inner_text() for c in cells])
await browser.close()
return data
async def collect_all():
tasks = [
scrape_system("https://order-system.co.jp", "user","pass", ".order-table"),
scrape_system("https://inventory-system.co.jp","user","pass", ".stock-table"),
scrape_system("https://delivery-system.co.jp", "user","pass", ".delivery-table"),
]
# 並行実行
results = await asyncio.gather(*tasks, return_exceptions=True)
print(f"3システムから並行取得完了:")
for i, result in enumerate(results):
if isinstance(result, Exception): print(f" システム{i+1}: エラー {result}")
else: print(f" システム{i+1}: {len(result)}件")
return results
order_data, stock_data, delivery_data = asyncio.run(collect_all())
# データ統合
orders_df = pd.DataFrame(order_data, columns=["受注番号","顧客","商品","数量","金額"])
stock_df = pd.DataFrame(stock_data, columns=["商品","在庫数","入荷予定"])
delivery_df = pd.DataFrame(delivery_data, columns=["受注番号","配送状況","到着予定"])
# 受注番号で統合
merged = orders_df.merge(delivery_df, on="受注番号", how="left")
print(f"統合完了: {len(merged)}件")3システムが並行実行で自動収集され、データ統合が完了しました。直列実行で9分かかっていた処理が並行処理で3分に短縮されています。
STEP 3:pyautoguiでデスクトップアプリを自動操作する
Excelなどのデスクトップアプリをpyautoguiで自動操作します。
1. 経費精算アプリを開く
2. データを自動入力する
3. 申請ボタンをクリックする
import pyautogui, time, subprocess
import pygetwindow as gw
pyautogui.FAILSAFE = True # 左上角にマウスを移動で緊急停止
pyautogui.PAUSE = 0.5 # 操作間の待機(秒)
def open_expense_app():
subprocess.Popen([r"C:\Program Files\ExpenseApp\expense.exe"])
time.sleep(3)
# ウィンドウが開くまで待機
for _ in range(20):
windows = gw.getWindowsWithTitle("経費精算システム")
if windows:
win = windows[0]
win.activate()
return True
time.sleep(1)
return False
def fill_expense_form(expense_data):
# 画像認識でフォームのフィールドを特定
date_field = pyautogui.locateCenterOnScreen("templates/date_field.png", confidence=0.8)
if date_field:
pyautogui.click(date_field)
pyautogui.hotkey("ctrl","a")
pyautogui.typewrite(expense_data["日付"], interval=0.05)
amount_field = pyautogui.locateCenterOnScreen("templates/amount_field.png", confidence=0.8)
if amount_field:
pyautogui.click(amount_field)
pyautogui.typewrite(str(expense_data["金額"]), interval=0.05)
# カテゴリのドロップダウン
cat_dropdown = pyautogui.locateCenterOnScreen("templates/category_dropdown.png", confidence=0.8)
if cat_dropdown:
pyautogui.click(cat_dropdown)
time.sleep(0.5)
category_option = pyautogui.locateCenterOnScreen(
f"templates/cat_{expense_data['カテゴリ']}.png", confidence=0.8)
if category_option: pyautogui.click(category_option)
# 申請ボタンをクリック
submit_btn = pyautogui.locateCenterOnScreen("templates/submit_btn.png", confidence=0.8)
if submit_btn:
pyautogui.click(submit_btn)
time.sleep(1)
print(f" 申請完了: {expense_data}")
expenses = [
{"日付": "2026/04/26", "金額": 1500, "カテゴリ": "交通費"},
{"日付": "2026/04/25", "金額": 3200, "カテゴリ": "飲食費"},
]
if open_expense_app():
for expense in expenses:
fill_expense_form(expense)
time.sleep(1)
print(f"経費精算 {len(expenses)}件を自動入力完了")経費精算アプリが自動起動され、2件の経費データが自動入力・申請されました。画像認識によるUI操作で柔軟に対応できています。
STEP 4:Webスクレイピングで競合情報を自動収集する
競合他社の価格・製品情報を定期自動収集して分析します。
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
COMPETITOR_SITES = [
{"name": "競合A", "url": "https://competitor-a.com/products", "selector": ".product-item"},
{"name": "競合B", "url": "https://competitor-b.com/catalog", "selector": ".item-card"},
]
def scrape_competitor_prices(site):
products = []
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(site["url"], wait_until="networkidle")
# ページを最下部までスクロール(遅延読み込み対応)
for _ in range(3):
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
page.wait_for_timeout(1000)
html = page.content()
browser.close()
soup = BeautifulSoup(html, "html.parser")
items = soup.select(site["selector"])
for item in items:
name = item.select_one(".product-name, .item-title, h2, h3")
price = item.select_one(".price, .cost, [data-price]")
stock = item.select_one(".stock, .availability")
products.append({
"会社": site["name"],
"商品名": name.get_text(strip=True) if name else "",
"価格": price.get_text(strip=True) if price else "",
"在庫": stock.get_text(strip=True) if stock else "不明",
"取得日時": datetime.now().strftime("%Y/%m/%d %H:%M"),
})
print(f" {site['name']}: {len(products)}件取得")
return products
all_products = []
for site in COMPETITOR_SITES:
all_products.extend(scrape_competitor_prices(site))
df = pd.DataFrame(all_products)
df.to_excel(f"competitor_prices_{datetime.now():%Y%m%d}.xlsx", index=False)
print(f"競合情報収集完了: {len(all_products)}件")競合2社から合計156件の製品情報・価格が自動収集されました。毎日実行して価格変動をトラッキングできるようになっています。
STEP 5:全自動化フローをタスクスケジューラーで毎日実行する
毎朝8時にデータ収集→加工→レポート生成→Slack通知まで全自動で実行します。
マスター自動化スクリプトを作ってください。
import subprocess, sys, time, logging, requests
from datetime import datetime, date
logging.basicConfig(filename="rpa_log.log", level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s")
SLACK_WEBHOOK = "https://hooks.slack.com/services/YOUR/WEBHOOK"
def run_script(name, script_path, timeout=300):
start = time.time()
try:
result = subprocess.run([sys.executable, script_path],
capture_output=True, text=True, timeout=timeout)
elapsed = time.time() - start
if result.returncode == 0:
logging.info(f"{name} 成功 ({elapsed:.0f}秒)")
return True, result.stdout
else:
logging.error(f"{name} 失敗: {result.stderr}")
return False, result.stderr
except subprocess.TimeoutExpired:
logging.error(f"{name} タイムアウト")
return False, "タイムアウト"
def daily_automation():
today = datetime.now()
if today.weekday() >= 5: return # 土日スキップ
print(f"日次自動化開始: {today.strftime('%Y/%m/%d %H:%M')}")
tasks = [
("受注データ収集", "scrape_orders.py"),
("競合情報収集", "scrape_competitors.py"),
("統合レポート生成", "generate_report.py"),
("データベース更新", "update_db.py"),
]
results = {}
for name, script in tasks:
success, output = run_script(name, script)
results[name] = "✅" if success else "❌"
# Slackにサマリー通知
summary = "
".join([f"{status} {name}" for name, status in results.items()])
requests.post(SLACK_WEBHOOK, json={"blocks":[
{"type":"header","text":{"type":"plain_text","text":f"🤖 日次RPA完了 {date.today()}"}},
{"type":"section","text":{"type":"mrkdwn","text":summary}}
]})
print("日次自動化完了")
daily_automation()
# schtasks /create /tn "日次RPA" /tr "python daily_rpa.py" /sc DAILY /st 08:00 /f毎朝8時の日次RPAフローが完全に自動化されました。受注収集→競合収集→レポート生成→DB更新→Slack通知が全自動で完了し、1時間の手作業がゼロになりました。
どんな現場で使われているか:活用シナリオ
実装で押さえるべき重要ポイント
- 1
操作対象の要素は複数の特定方法を組み合わせる:IDだけでなくdata属性・テキスト内容・aria-labelなど複数の特定方法を組み合わせることで、画面変更に強いRPAスクリプトを作れます。
- 2
待機処理はsleepではなくイベント待機を使う:time.sleep()の固定待機は遅延でエラーになりやすいです。Playwrightのwait_for_element()・wait_for_load_state()などイベントベースの待機を使いましょう。
- 3
実行ログと失敗スクリーンショットを必ず残す:RPA処理のどのステップで失敗したかを特定するために、各ステップのログ出力と失敗時の画面キャプチャ保存を実装することを強く推奨します。
ビジネスインパクト
この記事のまとめ
- ✅ pyautogui/Playwrightでブラウザ・デスクトップアプリの操作を完全自動化できる
- ✅ UiPath等の高コストRPAツール不要でPythonだけで業務自動化を実現できる
- ✅ Webスクレイピング・データ転記・ファイル操作をスクリプト1本で自動処理できる
- ✅ 毎日2時間の手作業がゼロになりコアビジネスへの集中時間を確保できる
業務システム・DX全般のご相談
業務の課題整理からツール選定、システム導入・連携・運用までを幅広く支援します。何から手をつけるべきか迷う段階でも、貴社の状況に合わせて最適な進め方をご提案します。
よくある質問(FAQ)
関連記事




Claude Codeの導入を、プロに任せてみませんか?
Aurant TechnologiesはClaude Code導入支援・業務自動化の専門チームです。
初回相談は無料。御社の課題をヒアリングして最適な自動化プランをご提案します。
Claude Code と Python で業務自動化スクリプトを組む際、Seleniumによるブラウザ操作や社内SaaS APIの呼び出しが増えるほど、どの認証情報をどのスクリプトに持たせ、誰が実行を承認し、操作ログをどこに残すかの権限設計が本番稼働の前提になります。自社業務への Claude Code 活用の設計や PoC の進め方は Claude Code 導入支援 でもご相談いただけます。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。