高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
目次 クリックで開く
モダンデータスタックCDP 実装クイックリファレンス(SQL / API / Reverse ETL)
本記事の解説に入る前に、CDP実装で頻出する3つのコードパターンを掲載しています。公式ドキュメントには載っていない実務上のハマりどころも含めています。
① Identity Graph 名寄せ(BigQuery SQL)
-- BigQuery: Identity Graph 名寄せ(メール + LINE userId + ハッシュ電話番号)
WITH unified_id AS (
SELECT
COALESCE(s.user_id, b.external_id, k.line_user_id) AS canonical_id,
s.email_sha256,
b.line_user_id,
k.cookie_id,
GREATEST(s.last_seen, b.updated_at, k.event_time) AS last_seen
FROM `prj.cdp.segment_users` s
FULL OUTER JOIN `prj.cdp.braze_users` b
ON SHA256(LOWER(s.email)) = b.email_sha256
FULL OUTER JOIN `prj.cdp.karte_users` k
ON s.user_id = k.user_id
)
SELECT canonical_id, MAX(last_seen) AS last_seen,
COUNTIF(line_user_id IS NOT NULL) > 0 AS has_line,
COUNTIF(cookie_id IS NOT NULL) > 0 AS has_web
FROM unified_id
GROUP BY canonical_id;② サーバーサイドイベント送信(Track API)
# Twilio Segment: Track API(Server-Side Event)
curl -X POST https://api.segment.io/v1/track \
-u "YOUR_WRITE_KEY:" \
-H "Content-Type: application/json" \
-d '{
"userId": "user_42",
"event": "Order Completed",
"properties": {"order_id": "ORD-1023", "revenue": 12800, "currency": "JPY"},
"context": {"ip": "203.0.113.42", "userAgent": "Mozilla/5.0"}
}'③ Reverse ETL(Hightouch → Salesforce)
# Hightouch (Reverse ETL): Salesforce Account へ毎時同期
type: salesforce
source:
warehouse: snowflake
query: |
SELECT account_id, mrr, health_score, churn_risk_30d
FROM marts.account_health
WHERE updated_at > DATEADD('hour', -1, CURRENT_TIMESTAMP)
mappings:
- column: account_id # → Account.External_Id__c (Upsert key)
field: External_Id__c
- column: mrr # → Account.MRR__c
field: MRR__c
- column: health_score # → Account.Health_Score__c
field: Health_Score__c
- column: churn_risk_30d # → Account.Churn_Risk__c
field: Churn_Risk__c
schedule: { cron: "5 * * * *" }※ サンプルコードはAurant Technologiesの実案件をベースに簡略化しています。本番投入前にスキーマ・認証設定をご自身の環境に合わせて検証してください。
高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
最終更新日:2026年4月7日 ※本記事は、WebトラッキングデータをSalesforce(CRM)等に同期させるデータ基盤を、高額なパッケージ製品に依存せず、安価かつスケーラブルに構築するためのアーキテクチャの裏側を網羅的に解説しています。
こんにちは。Aurant Technologiesの近藤義仁です。
前回の記事では、Webトラッキングと「CookieとCRM IDの紐付け(名寄せ)」のシステムの裏側を解説しました。これを実装しようとした時、多くの企業がTreasure DataやSalesforce Data Cloud、KARTE Datahubといった「オールインワンのCDP(カスタマーデータプラットフォーム)」の導入をベンダーから提案されます。
確かに多機能ですが、初期費用や月額数百万円のランニングコストがかかり、自社のデータ量や運用体制と見合わない(ROIが合わない)ケースが後を絶ちません。
本日は、巨大なパッケージ製品にシステムを丸投げするのではなく、GCPやAWSを中心とした専門ツール群をAPIで繋ぎ合わせ、自社専用のデータ統合基盤を安価に構築する「コンポーザブルCDP(モダンデータスタック)」の設計思想と、実務的なツール選定の基準を解説します。
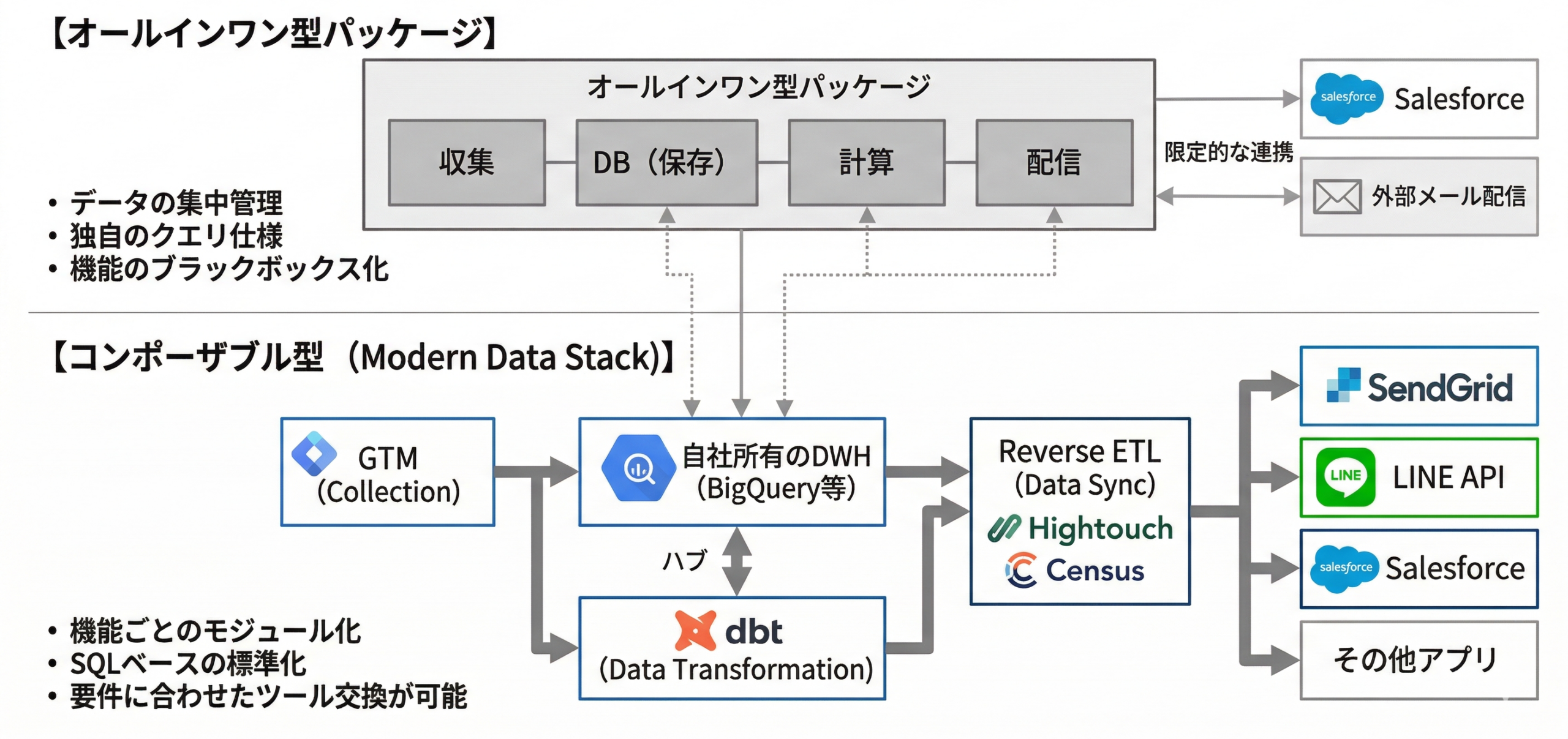
1. 徹底比較:「オールインワン」vs「コンポーザブル(MDS)」
データを収集し、名寄せを行い、SalesforceやMAツールへ同期する。このパイプラインを構築するアプローチは、現在大きく2つの陣営に分かれています。
オールインワンCDP陣営の構造的課題
代表的なツール:Treasure Data、Tealium、Salesforce Data Cloud など
これらは「すべての機能が一つの箱に入っている」製品です。大規模なグローバル企業等には向いていますが、「高額なランニングコスト」「ベンダーロックイン」「独自のクエリ仕様による学習コスト」といった課題を抱えています。
最大のデメリットは「データグラビティ(データの重力)」です。一度CDP内にデータを貯め込み、独自のモデリングを構築してしまうと、他のシステムへの移行が極めて困難になります。また、既に社内でGCP等を利用している場合、CDP側にも同じデータをコピーすることになり、二重管理(二重課金)が発生します。
コンポーザブルCDP(モダンデータスタック:MDS)の優位性
現代のデータエンジニアリングの世界的標準です。自社のクラウド(BigQuery等)をハブとし、そこに「収集」「変換」「同期」に特化したSaaSをブロックのように組み合わせて構築します。
| 比較項目 | オールインワンCDP | コンポーザブルCDP(MDS)※推奨 |
|---|---|---|
| データの保存場所 | SaaSベンダー側のサーバー(ロックインされる) | 自社のクラウド環境(完全なコントロール権) |
| コスト構造 | 初期費用 + 高額な固定月額(機能・レコード数に応じる) | クラウドのストレージと計算リソースに応じた従量課金(安価) |
| データ処理の柔軟性 | ベンダー独自のクエリ仕様や画面操作に依存する | 標準的なSQL(dbt等)で自由にデータモデルを構築可能 |
| 拡張・リプレイス | システム全体の入れ替えが必要でリスク大 | 特定の要件が変わっても、該当ツールの差し替えだけで済む |
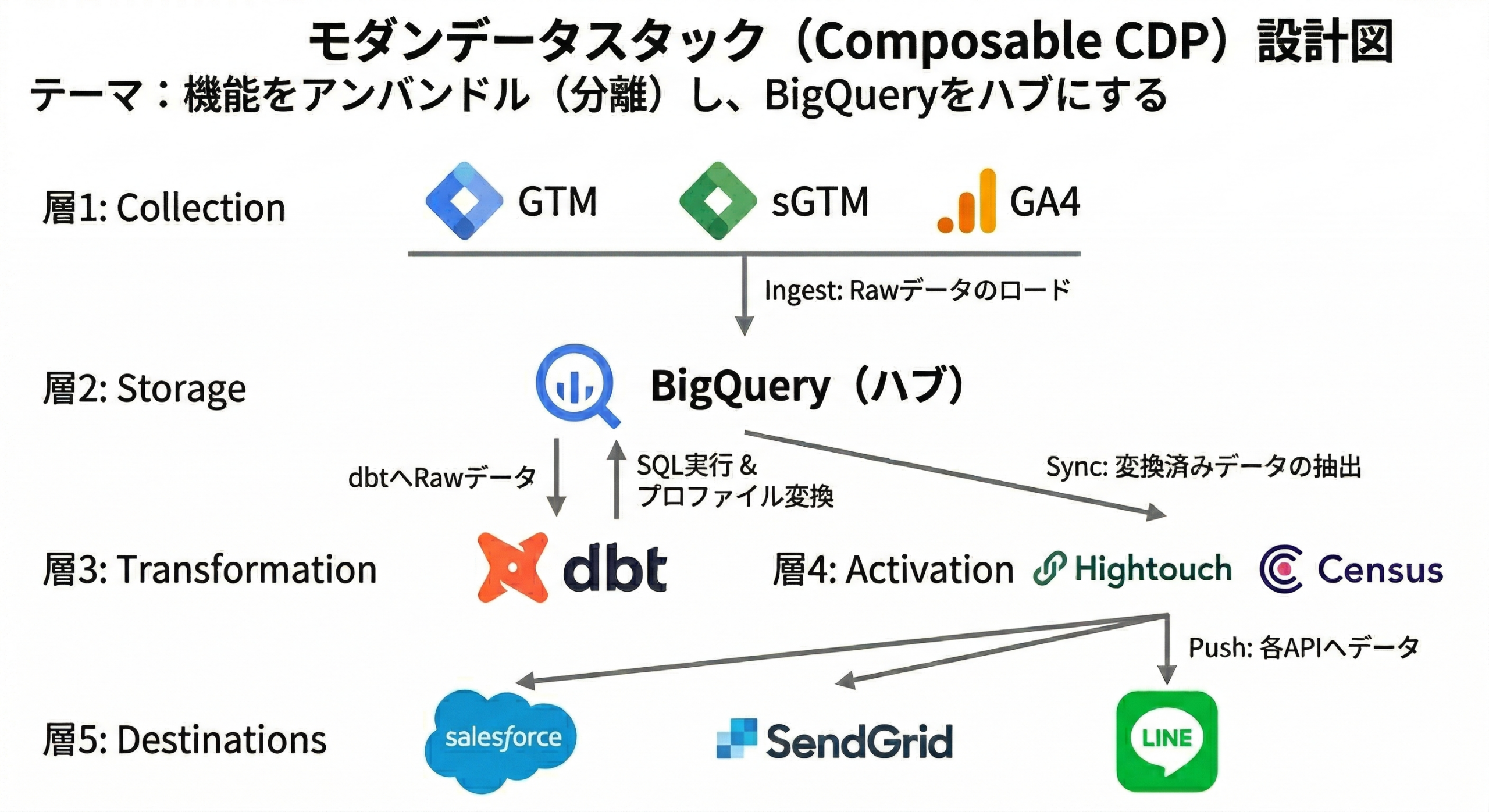
2. プロが選定するデータパイプラインの構成ツール(全4工程)
それでは、Web行動ログの収集からSalesforceへの同期までを、実務において何のツールを使って構築するのか、工程別に明確な選定基準を解説します。
工程①:データ収集(トラッキング)
Web上のユーザー行動を検知し、裏側のデータベースへ送信する工程です。
- GTM / サーバーサイドGTM
- GA4 (Google Analytics 4)
【設計の詳細】
GA4の「BigQueryへの無料エクスポート機能」を活用するのが業界のベストプラクティスです。サーバーサイドGTM(sGTM)を併用してHTTPヘッダ経由のCookieを発行し、ITP規制を回避するセキュアなトラッキングを実現します。
工程②:データ蓄積(DWH・データレイク)
数千万〜数億件の行動ログを安価に保存し、高速にSQL集計できる「ハブ」となる工程です。
- Google Cloud BigQuery (圧倒的推奨)
- Snowflake / Amazon Redshift
【設計の詳細】
BigQueryはサーバーのインフラ管理が不要(サーバーレス)であり、使った分だけの従量課金です。テラバイト級のデータを保存しても月額数千円〜数万円に収まることが多く、Salesforceに全ログを保存するのに比べ圧倒的に安価です。
工程③:データ変換(名寄せ・モデリング)
BigQuery内に溜まった「匿名のCookie」と「CRMの実名ID」を結合(JOIN)し、「過去7日のログイン回数」などのスコアを計算する工程です。
- dbt (data build tool)
【設計の詳細】
BigQueryのスケジュールクエリ単体で運用すると、SQLの依存関係が複雑化し「スパゲッティ化」します。dbtを導入することで、SQLコードのバージョン管理(Git連携)、テストの自動化、データリネージの可視化が可能になり、データモデルの品質を担保できます。
工程④:データ同期(リバースETL)
計算されたスコアやフラグを、Salesforce等のCRMへ自動的に書き戻す工程です。
- Hightouch / Census (大規模向け)
- Make (Integromat) (小〜中規模向け・iPaaS)
【設計の詳細】
自前でPython等を使ってSalesforceのAPIを叩くバッチ処理を開発すると、APIの制限(Rate Limit)やエラーハンドリングの保守工数が甚大になります。Hightouchなどの「リバースETLツール」を利用すれば、BigQueryのテーブルとSalesforceの項目をUI上でマッピングするだけで、差分同期をノーコードで安全に実行してくれます。
💡 アーキテクトのインサイト:なぜ「リバースETL」が画期的なのか?
これまでのシステム構築では、計算結果をSalesforceに反映させるために「自前で連携プログラムを書く」必要がありました。Hightouch等のリバースETLツールは、DWHとSaaSの間に立ち、SQLを書くだけで「どのデータを、SaaSのどの項目に同期するか」を管理してくれます。このツールの台頭により、高額なCDPを買わずとも、データ基盤からCRMへの「ラストワンマイル」が容易に開通するようになりました。
公式リファレンス:リバースETLの概念(Hightouch)
Hightouchは、データウェアハウス(BigQueryやSnowflake)を組織の中心的なデータソース(Single Source of Truth)として扱い、そこからSalesforceやMarketoなどのビジネスツールへデータを同期する「リバースETL」のパイオニアです。
(出典:Hightouch Blog – What is Reverse ETL?)
3. モダンデータスタック(MDS)導入の公式成功事例
実際にコンポーザブルな構成を採用し、ビジネス成果を上げている企業の事例をご紹介します。
米国 Lucid社:Salesforceへの営業インサイト提供
課題: 営業部門が、顧客の製品利用状況(誰がどの機能をどれくらい使っているか)を把握できず、アップセルの機会を逃していた。
解決策(MDSの導入): DWH(Snowflake)に集約された製品の利用ログを、リバースETL(Hightouch)を用いてSalesforceへ直接同期するアーキテクチャを構築。自前でのAPI連携開発を廃止した。
成果: 営業担当者はSalesforceの画面を見るだけで「製品をアクティブに利用している顧客(PQL)」を瞬時に把握できるようになり、営業効率が劇的に向上。開発チームはAPI連携の保守業務から解放された。
国内の潮流:データ基盤のコンポーザブル化
動向: 日本国内においても、株式会社10Xなどのデータ活用を推進するテック企業を中心に「BigQuery + dbt + リバースETL」の構成が標準化しつつあります。高額なCDPの導入を見送り、自社のGCPインフラを拡張することで、マーケティング部門だけでなく、経営企画・カスタマーサクセスといった全社横断的なデータ統合基盤として運用するケースが増加しています。
4. トラッキングからSalesforce連携までの全体データフロー
上記のツール群を組み合わせた、Web行動ログの取得からCRM連携に至るデータフローの全貌は以下のようになります。
ユーザーがWebサイトで行動を起こした際、GTMがデータレイヤーの値を拾います。
GA4の標準エクスポート機能を利用します。
BigQuery内でSQLがスケジュール実行されます。
スコアの高いユーザーの情報を、現場の営業が使うシステムへ返します。
まとめ:システムの「機能」ではなく、データの「主導権」を握る
「顧客の行動を可視化するために、とりあえず有名なCDPを入れよう」とツール名から入るプロジェクトは、高い確率で運用が行き詰まります。巨大な箱の中身を使いこなせず、データの移行もできなくなるからです。
重要なのは、**「自社のトラッキング要件において、どこにデータを貯め、どうやってCRMに返すのか」**というデータパイプラインの設計図を自社でコントロールすることです。
BigQueryを中心としたコンポーザブルな構成であれば、スモールスタートで構築を始め、事業の拡大に合わせて連携ツール(ブロック)を柔軟に差し替えていく運用が可能です。
- 「オールインワンCDPの更新見積もりが高すぎて、リプレイスを検討している」
- 「BigQueryにログは溜まっているが、名寄せができずSalesforceへ還元できていない」
- 「dbtやリバースETLを用いた、安価なデータ基盤の構築手法を知りたい」
もしこうしたデータ基盤構築の壁にぶつかっていらっしゃるなら、ぜひ一度ご相談ください。特定のベンダーに依存しないアーキテクトの視点で、貴社の予算と体制に最適な「コンポーザブルなデータ統合基盤」をご提案します。
【無料相談】貴社のデータ基盤、コストに見合っていますか?
既存のクラウドインフラを活かしたトラッキングとCRM連携を診断する「CX to Backoffice 構造診断」を実施中です。お問い合わせはこちら
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
【2026年版】モダンデータスタック 完全構成 ツール一覧
| レイヤー | 推奨ツール | 月額目安 |
|---|---|---|
| DWH | BigQuery / Snowflake | 5〜30万円 |
| 取込(ELT) | Fivetran / trocco / Airbyte | 5〜30万円 |
| 変換(モデリング) | dbt Cloud / Core | 無料〜10万円 |
| リバースETL(CDP化) | Hightouch / Census / RudderStack | 5〜30万円 |
| BI | Looker Studio / Tableau | 無料〜10万円 |
| カタログ/ガバナンス | dbt docs / Atlan / DataHub | 無料〜要問合せ |
| 品質モニタリング | dbt Tests / Monte Carlo | 無料〜 |
パッケージCDP vs MDS 5年TCO比較(中堅企業)
| 構成 | 月額 | 5年TCO |
|---|---|---|
| Treasure Data(パッケージ) | 100〜300万円 | 8,000万〜2億円 |
| Salesforce Data Cloud | 100〜400万円 | 1〜3億円 |
| MDS(BigQuery+dbt+Hightouch) | 30〜80万円 | 3,000〜6,000万円 |
FAQ
- Q1. MDS の最大の弱点は?
- A. 「データチームが必要」。エンジニアリング体力ゼロの組織では Packaged CDPが現実解。
- Q2. ハイブリッド構成は可能?
- A. 「DWH=MDS、配信=Packaged」のハイブリッドが2026年の主流。
- Q3. 構築期間は?
- A. 中堅で3〜6ヶ月。詳細は 顧客データ分析の最終稿。
関連記事
- 【CX 5大トレンド 2026】Composable CDP(ID 203)
- 【Reverse ETL】(ID 441)
- 【dbt×BigQuery】(ID 372)
- 【DWH構築実践ガイド】(ID 276)
- 【データガバナンス】(ID 396)
※ 2026年5月時点の市場動向を反映。
CDP・顧客データ基盤の関連完全ガイド
本記事のテーマに関連するCDP/顧客データ基盤の徹底解説記事を以下にまとめています。ツール選定・アーキテクチャ設計の参考にどうぞ。
- 【完全ガイド】Treasure Data 徹底解説 2026:Treasure AI / Engage Studio 進化、機能・コスト・他社CDPとの比較
- 【完全ガイド】Braze 徹底解説 2026:CEPからBraze Data Platformへ、設計思想・機能・TCO・他社比較
- 【完全ガイド】KARTE Datahub 徹底解説:BigQuery基盤Web接客CDPの活用パターン・コスト・他社比較
- 【完全ガイド】Twilio Segment 徹底解説 2026:4モジュール構成・MTU課金・他社CDPとの比較
- 【完全ガイド】Adobe Real-Time CDP 徹底解説:3エディション・Identity Graph・Adobe Experience Cloud統合・TCO
- 【完全ガイド】Composable CDP vs パッケージCDP 徹底比較:Snowflake+dbt+Hightouch型と統合パッケージ型の判断軸
- 【完全ガイド】Reverse ETL 徹底解説 2026:Hightouch・Census・Polytomic・RudderStack を比較
- 【完全ガイド】CDP × Claude Code / MCP 活用パターン 2026:自然言語でCDPを運用する実装事例
レガシーシステム刷新・モダナイゼーションの関連完全ガイド
本記事のテーマに関連する旧基幹/旧SaaSからのモダナイゼーション完全ガイド一覧です。移行戦略・選定軸の参考にどうぞ。
- 【完全ガイド】大塚商会 SMILE V 2nd Edition から他社ERPへの乗り換え:NetSuite・SAP・Dynamics 365・kintoneを比較
- 【完全ガイド】Microsoft Access から kintone への移行:データ移行・VBA資産の扱い・Power Apps との比較
- 【完全ガイド】AS/400 (IBM i) モダナイゼーション戦略 2026:4つの選択肢とクラウドERP移行先を徹底比較
- 【完全ガイド】富士通 GLOVIA から他社ERPへの移行:SAP S/4HANA・Oracle Fusion・Dynamics 365・NetSuite・Inforを徹底比較
- 【完全ガイド】弥生会計 デスクトップ版 から クラウド会計への移行:弥生会計オンライン・freee 会計・MFクラウド会計を徹底比較
- 【完全ガイド】Notes/Domino から Microsoft 365・kintone への移行戦略 2026:業務DB別の置き換えパターンとリプレース実務
- 【完全ガイド】SuperStream-NX から SuperStream-CLOUD・SAP S/4HANA・Workday・NetSuite への移行戦略
- 【完全ガイド】COMPANY から SmartHR・Workday・SAP SuccessFactors への移行戦略:大企業HR刷新の選定軸
- 【完全ガイド】eセールスマネージャー Remix から Salesforce・HubSpot・kintone・Zoho CRM への移行戦略
- 【完全ガイド】mcframe 7 から mcframe XA・SAP S/4HANA・Oracle Fusion・Infor CloudSuite への移行戦略
- 【完全ガイド】リコー文書管理システム から Box・Microsoft 365・kintone・Google Workspace への移行戦略
- 【完全ガイド】大塚商会 たよれーる契約の見直し:継続・部分内製化・完全切替の判断軸とコスト最適化
- 【完全ガイド】Oracle EBS / JD Edwards から Oracle Fusion Cloud Applications への移行戦略
- 【完全ガイド】Microsoft Dynamics 旧版(AX/GP/NAV/SL)から Dynamics 365 への移行戦略
- 【完全ガイド】desknet’s NEO・サイボウズ Office・Garoon オンプレ から クラウド型グループウェアへの移行戦略
- 【完全ガイド】NEC ACOS・富士通 GS21・日立 VOS3・IBM z/OS メインフレーム モダナイゼーション戦略
- 【完全ガイド】Pardot から Salesforce Marketing Cloud Account Engagement (MCAE) への移行:継続 vs HubSpot/Marketo 乗り換えの判断軸
- 【完全ガイド】Sansan の見直し:HubSpot・Salesforce・kintone+AI OCR・Microsoft 365 への乗り換え判断
- 【完全ガイド】旧世代CRM (SugarCRM・vTiger・Dynamics CRM旧版・Notes/Domino) からモダンCRMへの移行戦略
関連する無料ホワイトペーパー
本記事のテーマに関連する詳細資料を、メール登録のみで無料ダウンロードいただけます(業種別ROI試算・選定マトリクス・移行ロードマップを掲載)。
- Composable CDP 比較ガイド 2026
- Snowflake vs BigQuery vs Redshift TCO試算ガイド 2026
- iPaaS5社比較(新規導入版) 2026
Salesforce Agentforce 完全攻略シリーズ
Salesforce Agentforce の事前準備・データ接続・KPI・プロンプト設計までフェーズ別に深掘りした完全ガイドです。
- Agentforce導入成功の鍵!決めるべき5つの事前準備(ユースケース・データ・権限・ガバナンス・体制)
- AgentforceでCSATを最大化する戦略:ナレッジ検索、AI回答、シームレスなエスカレーション設計
- Agentforce×ナレッジベース整備:RAG精度を最大化するコンテンツ設計チェックリスト【Aurant Technologies独自】
- Agentforce導入企業の必読!情報漏洩を防ぐ権限・監査ログ設計とガバナンス実装
- Agentforceで失敗しない!自動化できる業務・できない業務の見極め方と導入戦略
- Agentforceの品質KPI:正答率を超え、有用性・安全性・工数削減でビジネス成果を最大化する評価戦略
- Agentforceの真価を引き出すデータ接続設計:Salesforceレコード・ナレッジ・DWHの使い分けと連携パターンを徹底解説
- Agentforceプロンプト設計入門:トーン&マナー・禁止事項・引き継ぎ文でAIエージェントをビジネスの力に変える
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】Salesforce 完全ガイド:CRM/SFA/MA/CDP/Agentforce の使い分けと統合設計、業界別実装パターン
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
関連するAurantのソリューション
本ガイドの内容を踏まえた、選定・導入・運用支援サービス
データ分析・BI
Looker Studio・Tableau・BigQueryを活用したBIダッシュボード構築から、データ基盤整備・KPI設計まで対応。経営判断をデータで支援します。