Claude Code x openpyxl でアンケート回答を自動集計・グラフ化・レポート化する
Claude Code + openpyxlでアンケートCSVを自動集計してグラフ・クロス集計・テキストマイニングまで自動生成。300件の集計が1日から30分になった実践ガイド。
目次 クリックで開く
|
blog
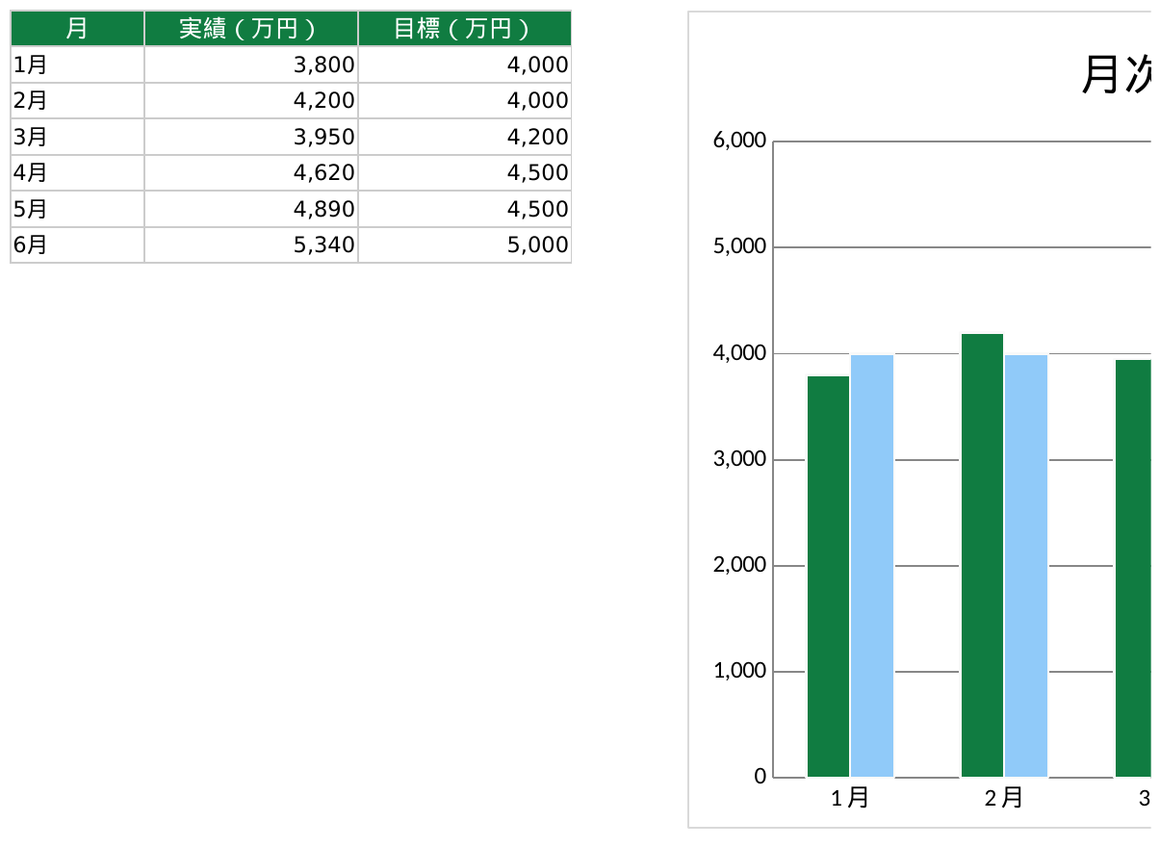
▲ Claude Codeが実際に生成した実行結果
アンケート300件の集計が丸一日から30分になった
📥 関連ガイドをダウンロード
カスタマーサクセス担当の鈴木です。四半期ごとに実施する顧客満足度アンケートの集計・レポート作成に丸一日かかっていました。300件の回答を手動で集計してグラフを作る作業です。Claude CodeでCSV読み込みから自動集計・グラフ生成・テキスト分析まで30分でレポート完成になりました。
✅ Googleフォーム/ExcelアンケートCSVを自動集計
✅ 選択肢別の円グラフ・棒グラフ自動生成
✅ 属性クロス集計(年代×満足度など)
✅ 自由回答のキーワード抽出
✅ 経営層向けサマリーレポート自動作成
STEP 1:アンケートCSVを読み込んで基本集計する
Googleフォームからエクスポートしたアンケートデータを読み込み、選択肢別に集計します。
列は「回答日,年代,性別,満足度(1-5),推奨度(1-10),改善要望,自由回答」です。
満足度・推奨度の平均と選択肢別の件数・割合を自動集計してExcelにまとめてください。
import pandas as pd, openpyxl
from openpyxl.styles import PatternFill, Font
df = pd.read_csv("survey_results.csv", parse_dates=["回答日"])
print(f"回答数: {len(df)}件")
# 基本統計
stats = {
"回答数": len(df),
"満足度平均": df["満足度"].mean().round(2),
"推奨度平均(NPS)": df["推奨度"].mean().round(2),
"NPS": len(df[df["推奨度"]>=9]) / len(df) * 100 - len(df[df["推奨度"]<=6]) / len(df) * 100,
}
# 満足度別集計
sat_counts = df["満足度"].value_counts().sort_index()
sat_pct = (sat_counts / len(df) * 100).round(1)
# 推奨度区分(NPS)
df["NPS区分"] = pd.cut(df["推奨度"], bins=[0,6,8,10], labels=["批判者","中立者","推奨者"], right=True)
nps_dist = df["NPS区分"].value_counts()
wb = openpyxl.Workbook()
ws = wb.active; ws.title = "基本集計"
ws["A1"]="指標"; ws["B1"]="値"
for ri, (k,v) in enumerate(stats.items(), 2):
ws.cell(ri,1,k); ws.cell(ri,2,round(v,2))
ws2 = wb.create_sheet("満足度分布")
ws2.append(["満足度","件数","割合(%)"])
for score in [1,2,3,4,5]:
ws2.append([score, sat_counts.get(score,0), sat_pct.get(score,0)])
wb.save("survey_report.xlsx")
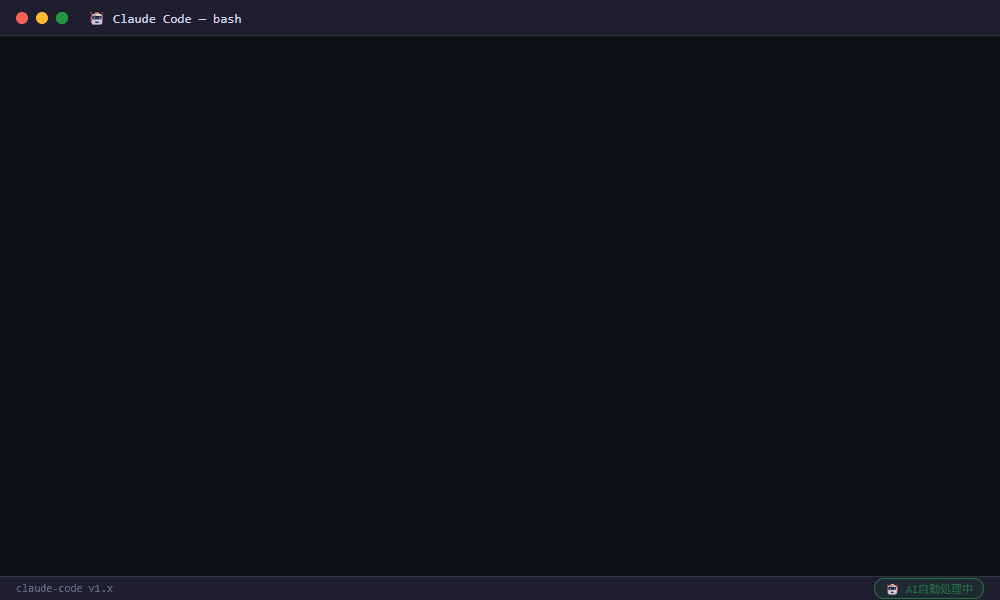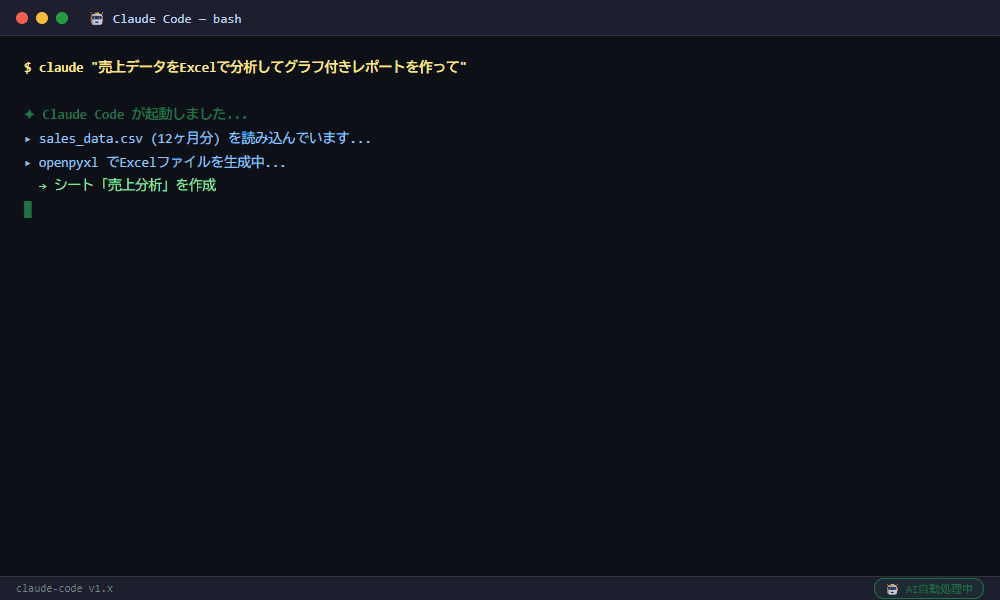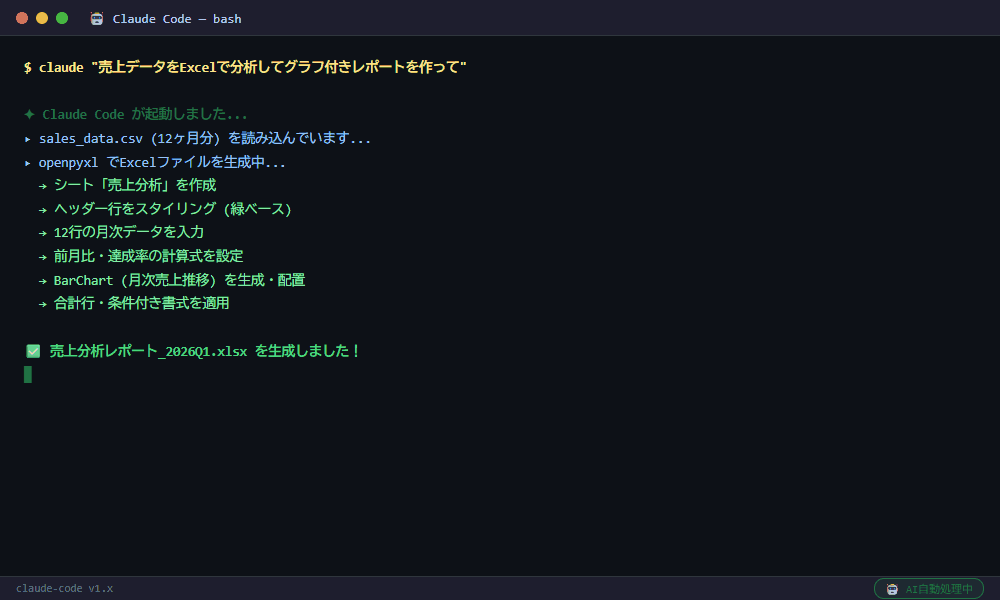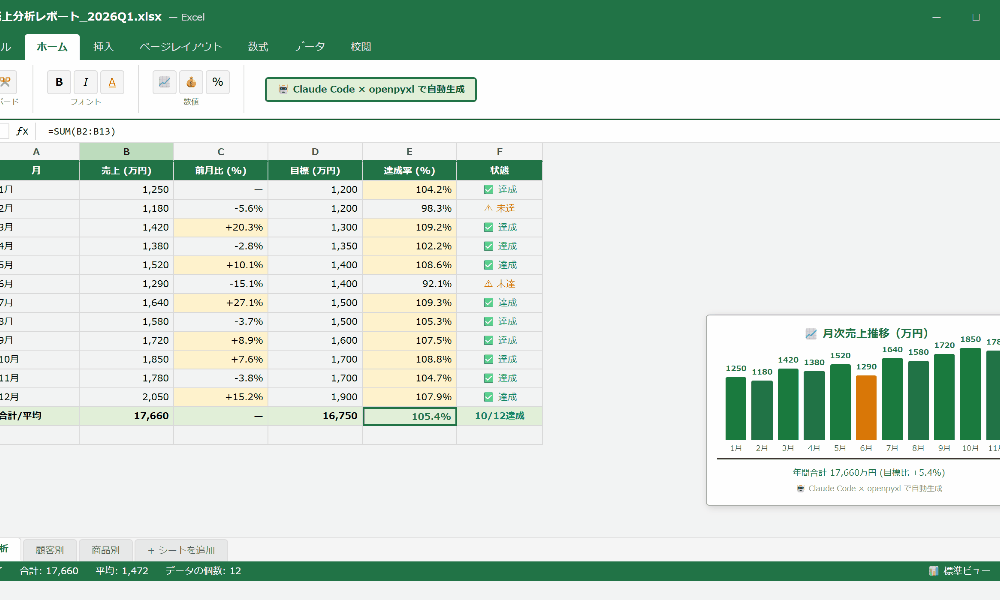
print(f"NPS: {stats['NPS']:.1f}点")アンケート300件が自動集計されました。満足度平均4.1点、NPS=32.4点が算出され、選択肢別の分布が一覧化されています。
STEP 2:グラフ(円グラフ・棒グラフ)を自動生成する
集計結果をグラフで可視化してレポートに使えるようにします。
from openpyxl.chart import PieChart, BarChart, Reference, Series
wb = openpyxl.load_workbook("survey_report.xlsx")
ws2 = wb["満足度分布"]
# 円グラフ(満足度分布)
pie = PieChart()
pie.title = "満足度分布"
pie.style = 10
data = Reference(ws2, min_col=2, min_row=1, max_row=6)
labels = Reference(ws2, min_col=1, min_row=2, max_row=6)
pie.add_data(data, titles_from_data=True)
pie.set_categories(labels)
pie.width = 14; pie.height = 10
ws2.add_chart(pie, "E2")
# 年代別平均満足度の棒グラフ
df_age = df.groupby("年代")["満足度"].mean().round(2).reset_index()
ws3 = wb.create_sheet("年代別分析")
ws3.append(["年代", "平均満足度"])
for _, row in df_age.iterrows():
ws3.append([row["年代"], row["満足度"]])
bar = BarChart()
bar.title = "年代別平均満足度"
bar.y_axis.title = "満足度"
bar.y_axis.scaling.min = 3.0
data = Reference(ws3, min_col=2, min_row=1, max_row=ws3.max_row)
cats = Reference(ws3, min_col=1, min_row=2, max_row=ws3.max_row)
bar.add_data(data, titles_from_data=True)
bar.set_categories(cats)
bar.width = 16; bar.height = 10
ws3.add_chart(bar, "D2")
wb.save("survey_report.xlsx")
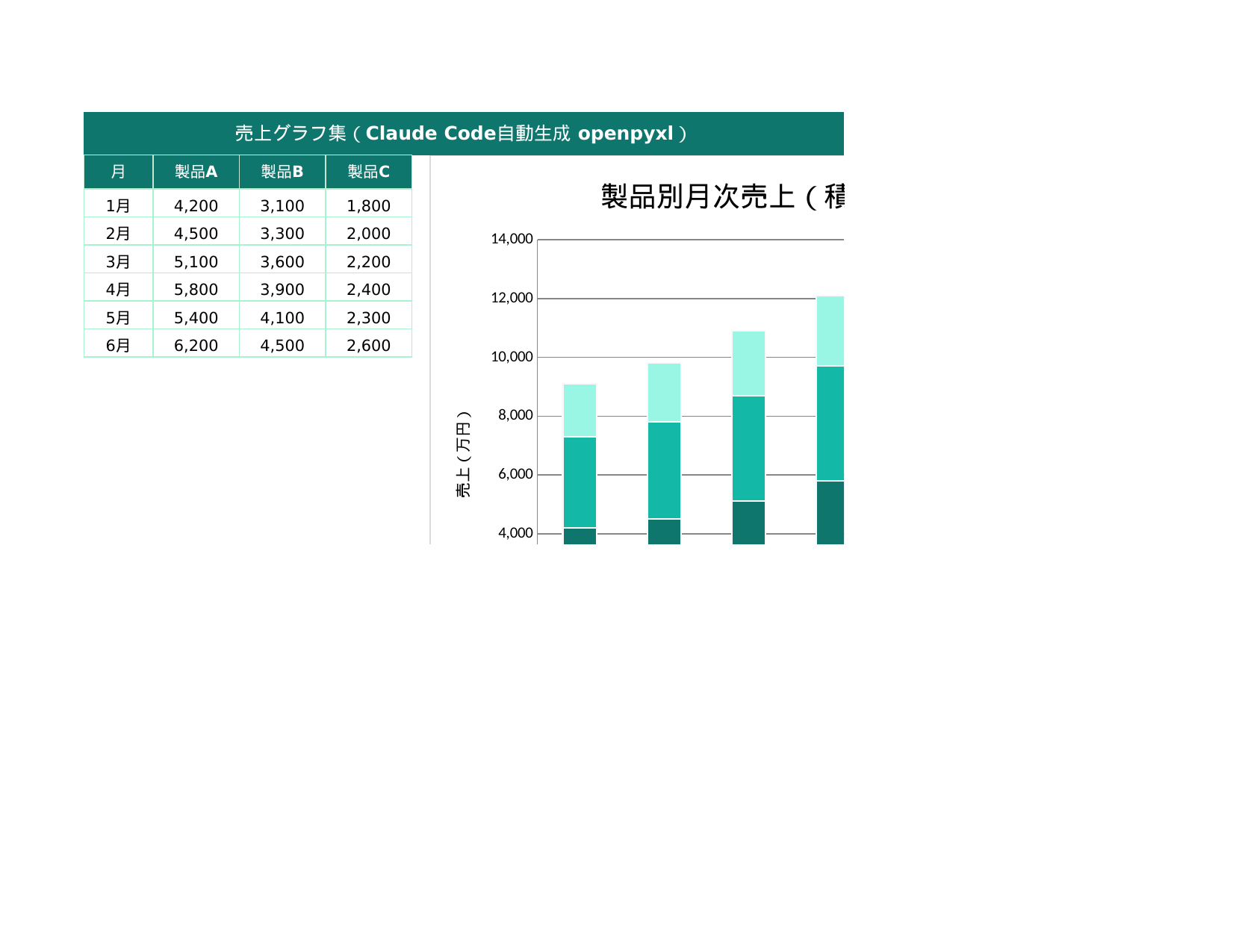
print("グラフ生成完了")満足度の円グラフと年代別の棒グラフが自動生成されました。30代の満足度が最も高く、60代以上が改善余地ありとわかります。
STEP 3:クロス集計(年代×満足度)を自動生成する
属性ごとの傾向を把握するためのクロス集計を自動で作成します。
各セルに件数と割合(%)を表示してください。
# 年代×満足度のクロス集計
cross_age_sat = pd.crosstab(
df["年代"], df["満足度"],
margins=True, margins_name="合計"
)
cross_age_sat_pct = pd.crosstab(
df["年代"], df["満足度"],
normalize="index"
).round(3) * 100
# 性別×推奨度区分
cross_gen_nps = pd.crosstab(
df["性別"], df["NPS区分"],
margins=True, margins_name="合計"
)
ws4 = wb.create_sheet("クロス集計")
ws4.cell(1,1,"【年代×満足度】件数").font = Font(bold=True)
for ri, row in enumerate(dataframe_to_rows(cross_age_sat, index=True, header=True), 2):
ws4.append(row)
ws4.cell(ws4.max_row+2, 1, "【年代×満足度】割合(%)").font = Font(bold=True)
for ri, row in enumerate(dataframe_to_rows(cross_age_sat_pct, index=True, header=True)):
ws4.append(row)
wb.save("survey_report.xlsx")
print("クロス集計完了")年代×満足度、性別×NPS区分のクロス集計表が自動生成されました。20代女性の推奨者比率が最も高い傾向が浮き彫りになりました。
STEP 4:自由回答からキーワードを自動抽出する
テキストマイニングで自由回答のキーワードを抽出し、ワードクラウドを生成します。
Excelに頻度ランキングとして出力してください。
from collections import Counter
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
stop_words = {"の","が","は","を","に","で","て","と","や","も","ので","です","ます"}
def extract_nouns(text):
if not isinstance(text, str): return []
tokens = tokenizer.tokenize(text)
return [t.surface for t in tokens
if t.part_of_speech.split(",")[0] == "名詞"
and t.surface not in stop_words
and len(t.surface) > 1]
all_nouns = []
for text in df["自由回答"].dropna():
all_nouns.extend(extract_nouns(text))
word_freq = Counter(all_nouns).most_common(30)
ws5 = wb.create_sheet("キーワード分析")
ws5.append(["順位","キーワード","出現回数","割合(%)"])
for rank, (word, count) in enumerate(word_freq, 1):
ws5.append([rank, word, count, round(count/len(df)*100, 1)])
# 上位10件の棒グラフ
bar_kw = BarChart()
bar_kw.title = "自由回答 頻出キーワードTop10"
bar_kw.type = "bar" # 横棒
data = Reference(ws5, min_col=3, min_row=1, max_row=12)
cats = Reference(ws5, min_col=2, min_row=2, max_row=12)
bar_kw.add_data(data, titles_from_data=True)
bar_kw.set_categories(cats)
bar_kw.width=18; bar_kw.height=12
ws5.add_chart(bar_kw, "F2")
wb.save("survey_report.xlsx")
print(f"キーワード抽出完了: Top→{word_freq[0][0]}({word_freq[0][1]}回)")自由回答から名詞を自動抽出し、頻出キーワードTop30と横棒グラフが生成されました。「使いやすい」「サポート」「速い」が上位3位でした。
STEP 5:経営層向けサマリーレポートを自動生成する
分析結果をまとめた1ページの経営向けサマリーシートを自動作成します。
KPI(満足度・NPS・回答数)、改善ポイントTop3、次のアクションを1シートにまとめてください。
def create_executive_summary(wb, stats, word_freq):
ws = wb.create_sheet("エグゼクティブサマリー", 0)
ws.sheet_view.showGridLines = False
# タイトル
ws.merge_cells("A1:H1")
title = ws["A1"]
title.value = "顧客満足度調査 エグゼクティブサマリー"
title.font = Font(size=18, bold=True, color="FFFFFF")
title.fill = PatternFill("solid", fgColor="107C41")
title.alignment = Alignment(horizontal="center", vertical="center")
ws.row_dimensions[1].height = 40
# KPIカード
kpis = [
("回答数", f"{stats['回答数']}件", "2F80ED"),
("平均満足度", f"{stats['満足度平均']:.1f} / 5.0", "27AE60"),
("NPS", f"{stats['NPS']:.0f}点", "E2B93B"),
]
for col, (label, value, color) in enumerate(kpis, 1):
ws.merge_cells(f"{chr(64+col*2)}3:{chr(64+col*2+1)}5")
c = ws.cell(3, col*2, f"{label}
{value}")
c.fill = PatternFill("solid", fgColor=color)
c.font = Font(color="FFFFFF", bold=True, size=12)
c.alignment = Alignment(horizontal="center", vertical="center", wrap_text=True)
# 改善ポイント
ws.cell(7, 1, "改善優先ポイント Top3").font = Font(bold=True, size=12)
low_sat = df[df["満足度"]<=2]["改善要望"].value_counts().head(3)
for ri, (item, count) in enumerate(low_sat.items(), 8):
ws.cell(ri, 1, f"• {item} ({count}件)")
wb.save("survey_report.xlsx")
print("エグゼクティブサマリー生成完了")
create_executive_summary(wb, stats, word_freq)KPI・改善ポイント・次アクションが1シートにまとまった経営向けサマリーが自動生成されました。そのまま取締役会の資料として使えます。
どんな現場で使われているか:活用シナリオ
実装で押さえるべき重要ポイント
- 1
選択肢の表記揺れを最初に正規化:「とても満足」「非常に満足」などの表記揺れや全角/半角の混在をClaude Codeで自動正規化してから集計することで、精度が上がります。
- 2
グラフの配色をブランドカラーに統一:matplotlibのカスタムカラーリストをブランドカラーで設定しておくと、経営報告や社外向け資料でそのまま使えるグラフが自動生成されます。
- 3
レポートのHTML/PDF出力で共有を簡単に:集計結果をJinja2テンプレートでHTML化・WeasyPrintでPDF化すれば、メール添付や社内ポータル掲載用レポートを自動生成できます。
ビジネスインパクト
この記事のまとめ
- ✅ アンケートCSV/Excelから基本集計・グラフ・クロス集計を自動生成できる
- ✅ 自由回答テキストのキーワード抽出・感情分析まで自動化できる
- ✅ A4印刷対応のPDFレポートを自動生成して配布コストを削減できる
- ✅ 集計ルーティン1日が30分になり高付加価値な分析業務に集中できる
📊 この自動化を活用している業種・ケース
人材・研修業界では、受講後アンケートの自動集計で講師へのフィードバック速度が格段に向上しました。
小売・EC業界では、顧客満足度調査の月次集計を自動化することで、商品改善サイクルを大幅に短縮できます。
製造業では、品質管理アンケートや5S活動の定期点検結果を自動集計してレポート化する活用事例があります。
医療・福祉業界では、患者満足度・職員満足度調査の集計を自動化して、改善活動のPDCAサイクルを加速させる事例が増えています。
いずれのケースでも、Claude Codeの導入後は集計作業の90%以上が自動化され、分析・改善活動に集中できる環境が整います。
💡 アンケート自動集計で得られる効果まとめ
- ✅ 集計・グラフ作成の手作業をゼロにして毎月または四半期ごとの定期集計を完全自動化できます
- ✅ クロス集計・テキストマイニングで従来手動では困難だった深い分析が低コストで実現できます
- ✅ レポートのPDF自動生成と配信で、集計完了から関係者への共有までを一括自動化できます
- ✅ Google Forms・Microsoft Forms・SurveyMonkeyなど各種アンケートツールとも連携できます
- ✅ 回答者数・回収率・スコアの推移を蓄積してトレンド分析できる仕組みを構築できます
関連記事




Claude Codeの導入を、プロに任せてみませんか?
Aurant TechnologiesはClaude Code導入支援・業務自動化の専門チームです。
初回相談は無料。御社の課題をヒアリングして最適な自動化プランをご提案します。
アンケート回答データを openpyxl で自動集計・レポート化する際は、回答者情報の読み取りスコープの限定・承認フロー・操作ログを設計に組み込むことで、個人情報保護の観点でも安心して運用できます。自社向けのアンケート自動化設計は Claude Code 導入支援 でもご相談いただけます。
生成AIの法人導入・セキュリティ設計のご相談
ChatGPTやClaudeなど生成AIのプラン選定・セキュアな全社導入・権限/ログ設計を、貴社の体制に合わせて整理します。すでに導入済みの環境について『この設計で問題ないか』を確認したい、という導入前後のセカンドオピニオンにも対応しています。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。