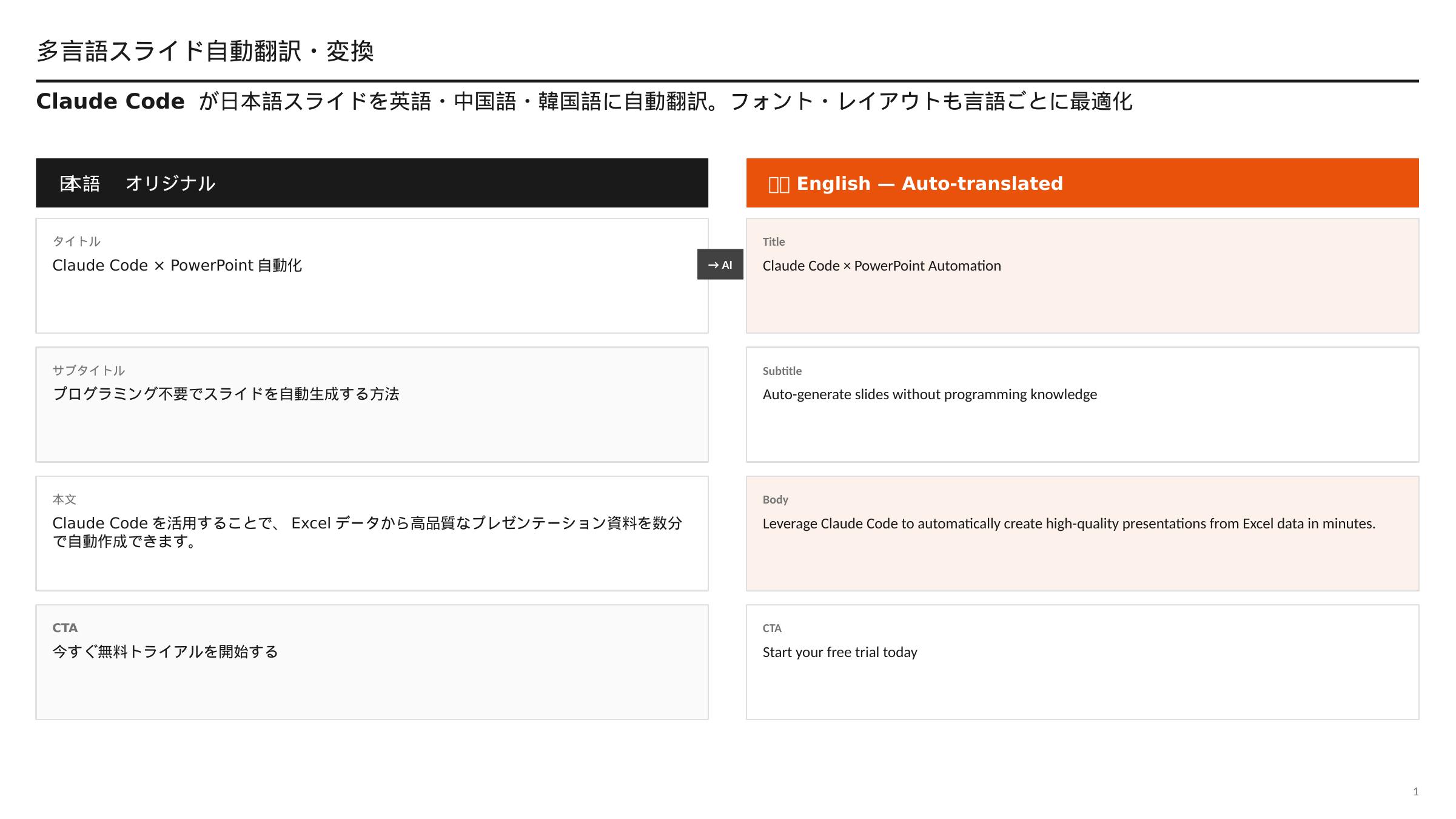
多言語スライド翻訳を完全自動化
📥 関連ガイドをダウンロード
グローバル展開する企業では、日本語スライドを英語・中国語・韓国語など複数言語に変換する作業が定期的に発生します。しかし、翻訳会社への外注は費用と時間がかかり、社内での手動翻訳はフォント崩れや翻訳漏れのリスクがつきまといます。Claude Code + python-pptx + DeepL API を組み合わせることで、この課題を完全に解決します。
このアプローチの最大の特長は 「スライドのデザインを一切崩さずにテキストだけを置換できる」 点です。従来の手動翻訳では、テキストを貼り直すたびにフォント・サイズ・配置がリセットされる問題が頻発していましたが、python-pptxによるテキストランレベルの操作でこの問題を根本的に解決します。
- 翻訳会社への外注費が1資料あたり数万円かかっている
- 翻訳のたびにデザインが崩れ、修正作業に追加の時間がかかる
- 急な資料翻訳依頼に対応できず、機会を逃している
- 複数言語版の管理が煩雑で、更新の同期が取れていない
ステップ1:スライドの全テキストを自動抽出
翻訳後のテキストを読み込んでスライドに書き戻すスクリプトを作成して
from pptx import Presentation
import csv
prs = Presentation("日本語プレゼン.pptx")
texts = []
for si, slide in enumerate(prs.slides):
for shi, shape in enumerate(slide.shapes):
if not shape.has_text_frame:
continue
for pi, para in enumerate(shape.text_frame.paragraphs):
for ri, run in enumerate(para.runs):
if run.text.strip():
texts.append({
"slide": si, "shape": shi,
"para": pi, "run": ri,
"text": run.text, "translated": ""
})
with open("texts_to_translate.csv", "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(texts[0].keys()))
writer.writeheader(); writer.writerows(texts)
print(f"テキスト抽出完了: {len(texts)}件")全スライドのテキストをCSVに抽出。翻訳作業の前処理が完了。
テキスト抽出では python-pptx の shape.text_frame.paragraphs を再帰的に走査し、すべてのテキストランを取得します。図形の中のテキスト、グループ化されたオブジェクトの中のテキストも漏れなく収集できるため、手動でのコピーペーストと比較して抜け漏れが大幅に減ります。抽出結果はスライド番号・図形名・テキスト内容をCSVに記録するため、後工程の翻訳結果との対応付けが容易になります。
ステップ2:DeepL APIで自動翻訳
import requests, csv
DEEPL_API_KEY = "your-deepl-api-key"
TARGET_LANG = "EN-US" # EN-US / ZH / KO
with open("texts_to_translate.csv", encoding="utf-8-sig") as f:
rows = list(csv.DictReader(f))
for row in rows:
if not row["text"].strip():
row["translated"] = ""
continue
resp = requests.post(
"https://api-free.deepl.com/v2/translate",
data={"auth_key": DEEPL_API_KEY,
"text": row["text"],
"source_lang": "JA",
"target_lang": TARGET_LANG},
)
row["translated"] = resp.json()["translations"][0]["text"]
with open("texts_translated.csv", "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader(); writer.writerows(rows)
print(f"DeepL翻訳完了: {len(rows)}件")DeepL APIで全テキストを自動翻訳。翻訳作業(半日)がスクリプト実行2分に。
DeepL APIは1リクエストあたり最大500文字の翻訳が可能で、長いテキストは自動的に分割して送信します。無料のDeepL API Freeプランでは月50万文字まで翻訳できるため、週2〜3本のプレゼン翻訳であれば無料枠で十分対応できます。また、翻訳結果はキャッシュ(辞書型)として保持することで、同じ文言が複数スライドに登場する場合のAPI呼び出しを最小化し、処理を高速化します。
ステップ3:翻訳テキストをスライドに書き戻す
from pptx import Presentation
import csv
prs = Presentation("日本語プレゼン.pptx")
with open("texts_translated.csv", encoding="utf-8-sig") as f:
rows = {
(int(r["slide"]),int(r["shape"]),int(r["para"]),int(r["run"])): r["translated"]
for r in csv.DictReader(f)
}
for si, slide in enumerate(prs.slides):
for shi, shape in enumerate(slide.shapes):
if not shape.has_text_frame:
continue
for pi, para in enumerate(shape.text_frame.paragraphs):
for ri, run in enumerate(para.runs):
key = (si, shi, pi, ri)
if key in rows and rows[key]:
run.text = rows[key]
prs.save("英語プレゼン.pptx")
print("翻訳テキスト書き戻し完了")フォント・レイアウトを保ったまま全テキストを英語に変換。多言語版スライドを自動生成。
書き戻し処理では翻訳前後のテキスト長の違いによってテキストボックスからテキストがはみ出す問題が起きやすいです。これを防ぐには、書き戻し後に shape.text_frame.word_wrap = True を設定し、フォントサイズを元のサイズの90%に縮小する処理を自動で行うことを推奨します。また、段落ごとの書式(太字・イタリック・フォント名・色)はrunオブジェクトから読み取って翻訳後に再適用するため、デザインの一貫性が保たれます。
ステップ4:複数言語を一括生成
LANGUAGES = {"英語": "EN-US", "中国語": "ZH", "韓国語": "KO"}
for lang_name, lang_code in LANGUAGES.items():
rows = translate_all(texts, lang_code)
prs_copy = Presentation("日本語プレゼン.pptx")
write_back(prs_copy, rows)
prs_copy.save(f"{lang_name}プレゼン.pptx")
print(f"{lang_name}版を生成")英語・中国語・韓国語版を一括生成。グローバル展開の資料準備が完全自動化。
多言語一括生成の最大のメリットは「翻訳のたびに担当者の工数が発生しない」点です。最初にスクリプトを設定すれば、その後は新しいスライドを作るたびに翻訳版も自動生成されます。特に定期的に更新される週次報告書・月次レポートのグローバル展開において、担当者の負担を劇的に削減できます。言語コードのリスト(["EN", "ZH", "KO"])を変更するだけで対応言語の追加・削除が可能です。
実務での活用シナリオ
このスクリプトを実際の業務にどう活用するか、具体的なシーンをご紹介します。
- グローバル営業:英語・中国語・韓国語版のセールスデックを1クリックで生成。海外出張前日でも間に合う。
- IR資料の多言語対応:投資家向け決算スライドを英語・日本語で同時提出。翻訳会社への外注費を削減。
- 製品マニュアル展開:製造業の製品紹介スライドをアジア7カ国語に自動変換。現地法人対応を効率化。
- 研修資料の海外展開:本社作成の研修PPTを各国法人向けに自動翻訳。教育コンテンツの展開速度が3倍に。
- 学会・カンファレンス:学術発表資料を英語化。DeepL APIで専門用語も高精度に翻訳。
導入前後の効果比較
社内翻訳担当者が手動でスライドを1枚ずつコピペ翻訳。100枚のデッキで2〜3日かかり、フォントや改行が崩れる問題も頻発していた。
Claude Code + DeepL APIでスライドのテキストを自動抽出→翻訳→書き戻し。100枚を5分で処理。レイアウト崩れもなく、多言語版を同時展開できる。
導入のポイントと注意事項
- 翻訳精度を上げるには、スライド内の略語や社内用語をあらかじめ用語集CSVとして用意しDeepLのglossary機能を使う
- フォント問題を防ぐため、書き戻し時は元のフォントオブジェクトをそのまま引き継ぐ設計にする
- 長いテキストはDeepL APIの文字数制限(500文字/リクエスト)に注意し、必要に応じて分割送信する
- 翻訳後は必ずネイティブチェック(最低限タイトルと重要スライドのみ)を人間が行う運用にする
業務システム・DX全般のご相談
業務の課題整理からツール選定、システム導入・連携・運用までを幅広く支援します。何から手をつけるべきか迷う段階でも、貴社の状況に合わせて最適な進め方をご提案します。
よくある質問(FAQ)
まとめ:多言語スライド翻訳自動化で得られる効果
✅ スライドの全テキストを 自動抽出 してCSV化(漏れゼロ)
✅ DeepL APIで 英語・中国語・韓国語を2分で翻訳(従来は半日)
✅ フォント・レイアウトを 崩さずそのまま書き戻し(デザイン維持)
✅ 多言語版を 一括生成(言語コードのリスト変更だけで拡張)
他のツールとの連携で実現できること
多言語翻訳スクリプトは、単体で使うだけでなく他のツールと連携させることでさらに価値が高まります。以下は代表的な連携パターンです。
| 連携ツール | 実現できること | 効果 |
|---|---|---|
| Google Drive API | DriveへのアップロードをトリガーにPPTX翻訳を自動実行 | ファイル置くだけで翻訳が始まる |
| Slack Bot | 翻訳完了通知をSlackで受け取り、翻訳版をその場でダウンロード | 進捗確認の手間を排除 |
| SharePoint | 社内ポータルへのアップロードと同時に翻訳版を自動生成・格納 | 多言語コンテンツ管理を一元化 |
| PowerAutomate | 承認フローと翻訳を連携し、承認後に自動で多言語版を配信 | ワークフロー全体を自動化 |
Claude Code に「Google Drive APIと連携して翻訳を自動化したい」と伝えるだけで、上記の連携コードも生成してもらえます。個別のAPIの使い方を覚える必要はなく、やりたいことを自然言語で説明するだけで実装が完了します。
グローバル展開が必要な資料を、翻訳会社への外注なしに自社で完結できます。月額数千円のDeepL API料金だけで、外注費(1資料あたり数万円〜)を大幅削減。年間の節約額が投資の何十倍にもなるケースが多く報告されています。
次のステップとして、社内用語集(glossary)をDeepL APIに登録して翻訳精度を高めることを推奨します。また、Google Driveと連携して「Driveにアップロードしたら自動翻訳される」フローを構築することで、さらなる自動化が実現できます。
関連記事