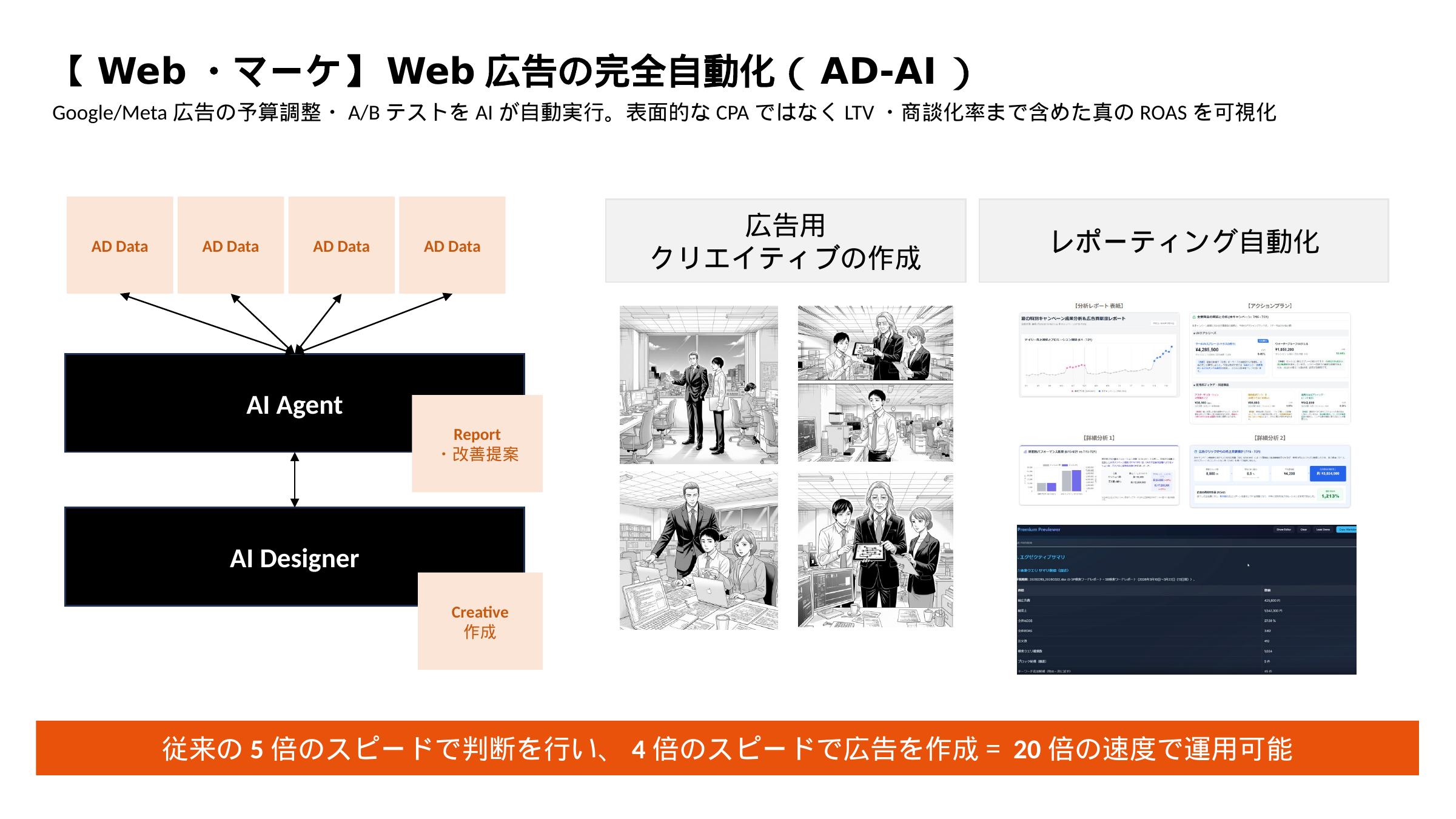
Power Query自動化の全体像
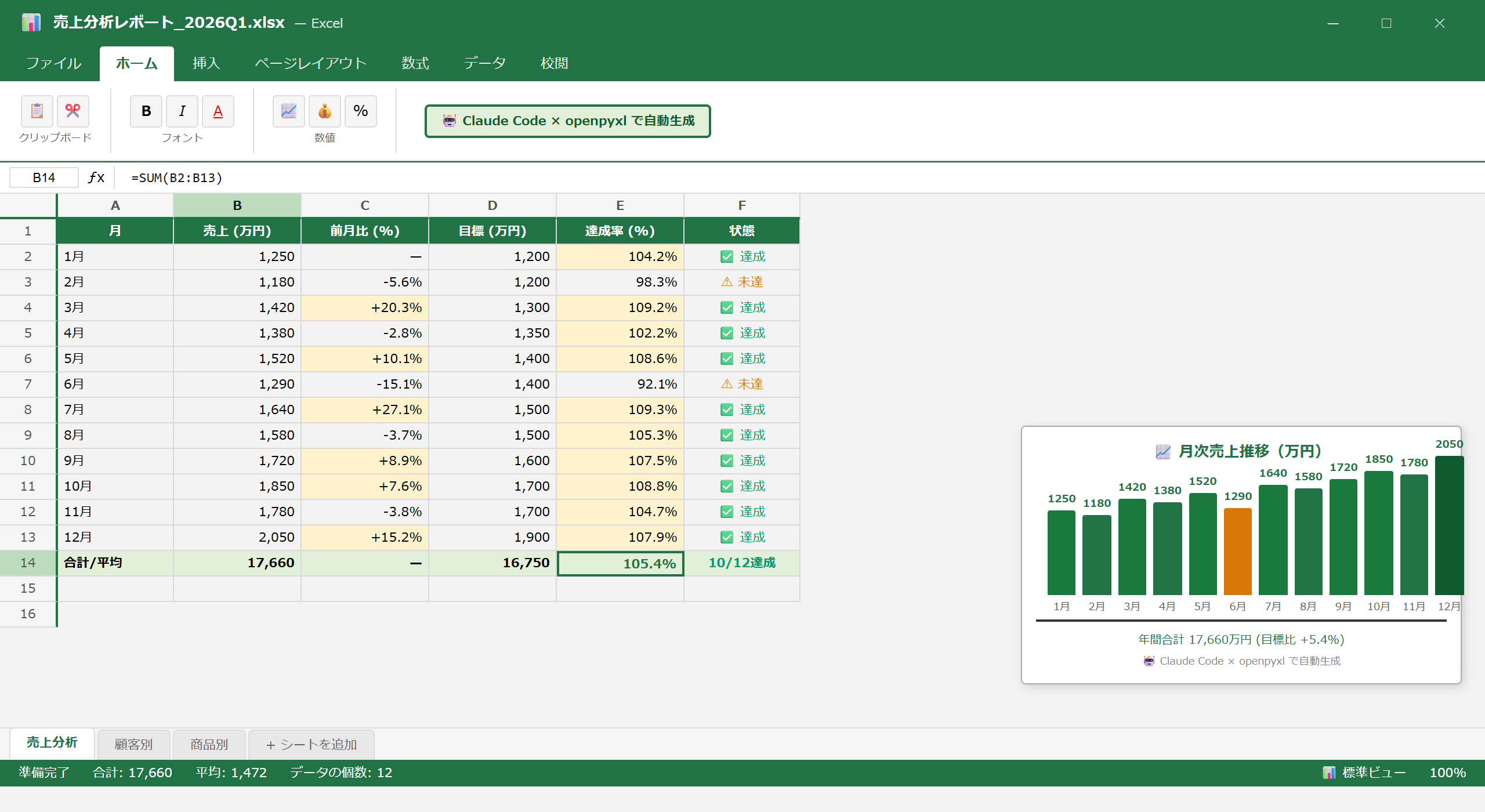
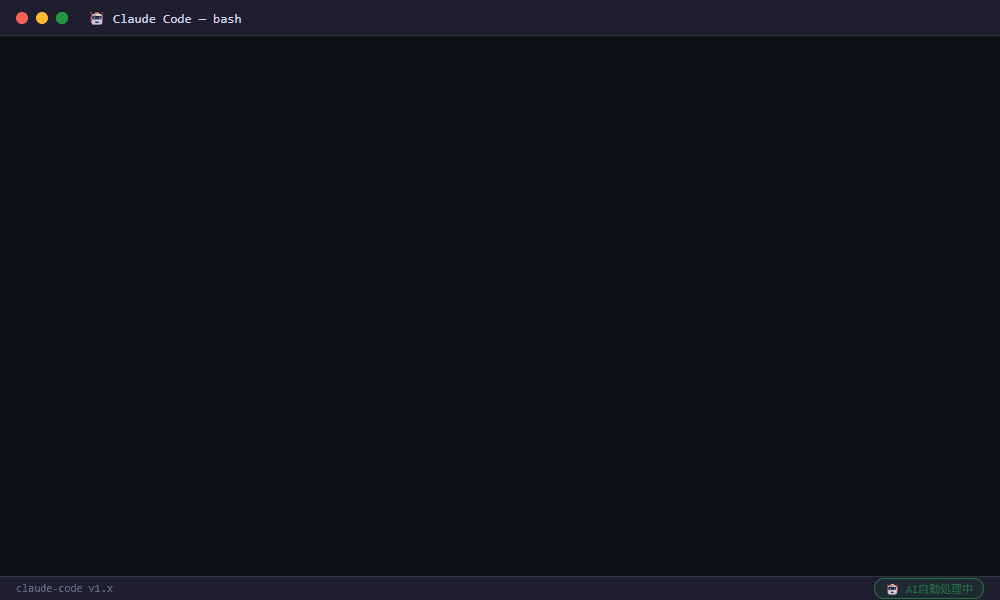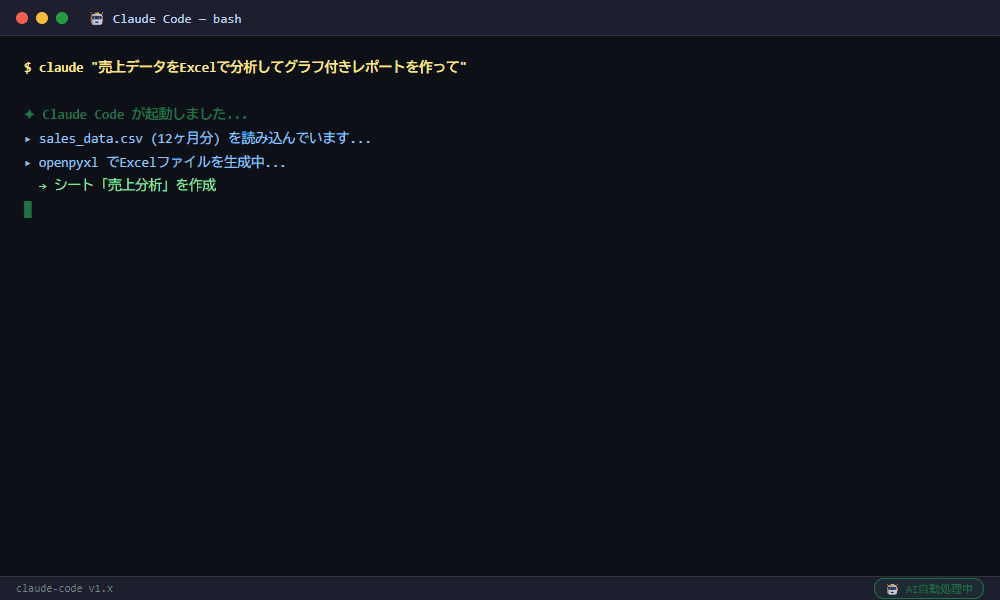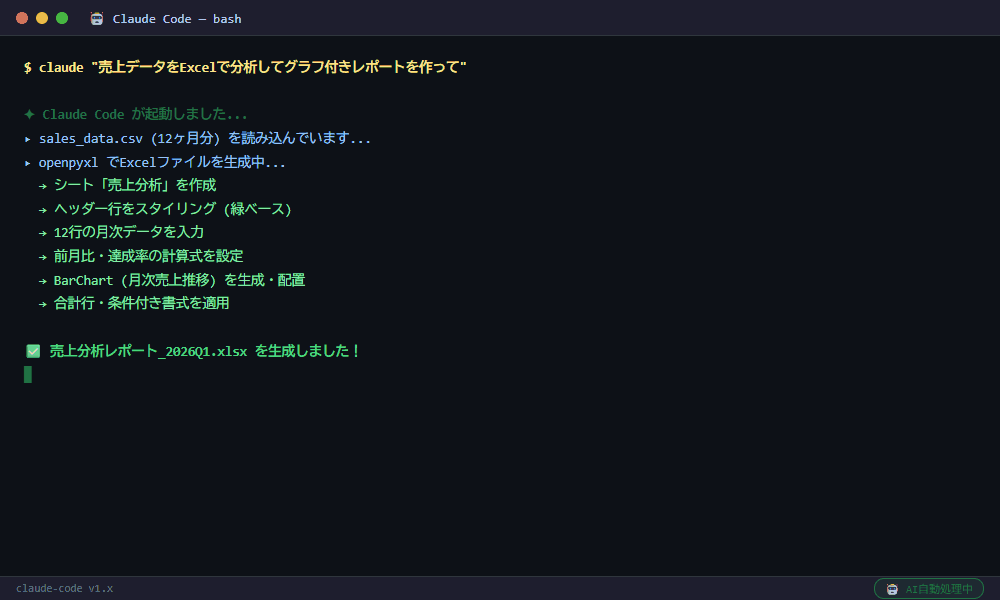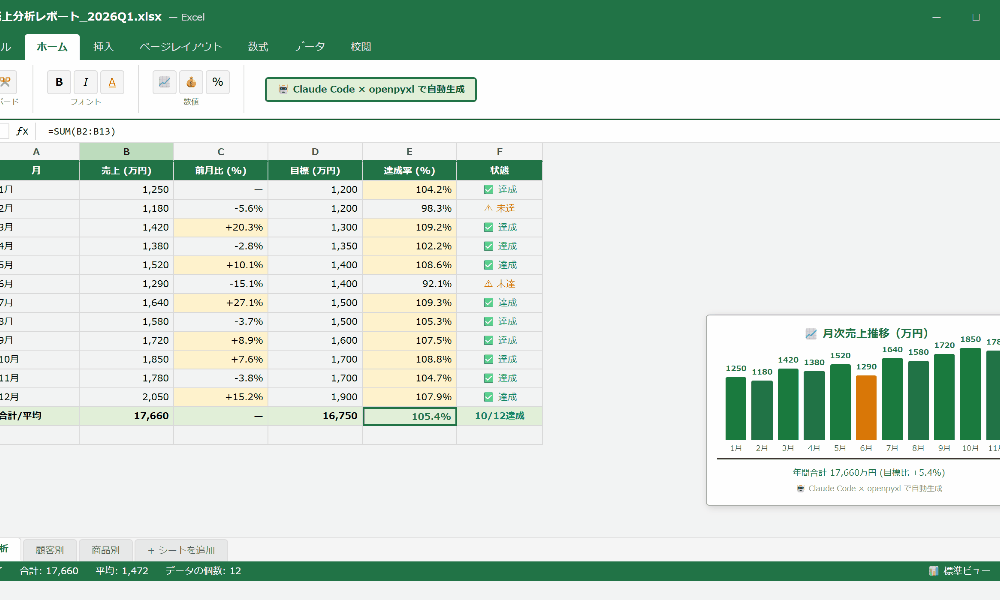
📥 関連ガイドをダウンロード
- Power Query→Python ETL自動化の完全自動化を実現するPythonスクリプトを5ステップで解説
- 「複雑な変換ステップのブラックボックス化」という課題を根本から解消する
- Claude Codeへの自然言語指示だけでスクリプトを生成できる
- 月・週・日単位の定期実行で完全無人化を実現する方法も紹介
以下のステップを順番に実行することで、今日から業務自動化を始められます。コピーして使えるコードと、Claude Codeへの指示文をセットで解説します。
Power Query は Excel の強力なデータ変換エンジンです。Claude Code を使えば、複数CSVの結合・データ型変換・不要列削除・ピボット展開を自然言語で指示し、openpyxl や pandas で完全自動化できます。毎朝の手動作業を夜間バッチに置き換えます。
ステップ1:複数CSVを自動結合して1シートにまとめる
ファイル名を「出所」列として追加して
import pandas as pd
from pathlib import Path
import openpyxl
folder = Path("./data_csv")
dfs = []
for csv_file in sorted(folder.glob("*.csv")):
df = pd.read_csv(csv_file, encoding="utf-8-sig")
df["出所ファイル"] = csv_file.name
dfs.append(df)
combined = pd.concat(dfs, ignore_index=True)
# Excelに出力
with pd.ExcelWriter("結合データ.xlsx", engine="openpyxl") as writer:
combined.to_excel(writer, sheet_name="結合データ", index=False)
print(f"結合完了: {len(dfs)}ファイル / {len(combined)}行")12ファイル・3,800行を自動結合。手動コピペ(1時間30分)がスクリプト実行12秒に。
毎月20〜30個のCSVを手でコピペして結合し、不整合データを目視確認。作業に丸1日かかっていた。
Power QueryをPythonで自動化することで、CSVの結合・クレンジング・集計を全自動化。月次作業が1日→10分に。
ステップ2:データクレンジングを自動化する
import pandas as pd
df = pd.read_excel("結合データ.xlsx")
# 空白・重複・異常値を自動除去
df = df.dropna(subset=["顧客ID", "売上金額"]) # 必須列のNaN除去
df = df.drop_duplicates(subset=["注文ID"]) # 重複行除去
df = df[df["売上金額"] > 0] # 売上が0以下を除去
# 文字列クレンジング
df["顧客名"] = df["顧客名"].str.strip() # 前後空白除去
df["電話番号"] = df["電話番号"].str.replace("-", "").str.replace(" ", "")
# 型変換
df["注文日"] = pd.to_datetime(df["注文日"], format="%Y/%m/%d", errors="coerce")
df["売上金額"] = pd.to_numeric(df["売上金額"], errors="coerce")
df.to_excel("クレンジング済.xlsx", index=False)
print(f"クレンジング完了: {len(df)}行")空白・重複・型エラーを自動除去。データ品質チェック(2時間)がゼロに。
ステップ3:Webから最新データを自動取得
import requests, pandas as pd, openpyxl
from datetime import datetime
# 例: 為替レートAPIから最新レートを取得
url = "https://api.exchangerate-api.com/v4/latest/JPY"
resp = requests.get(url, timeout=10)
data = resp.json()
rates = [{"通貨": k, "JPY換算": 1/v if v else None, "取得日時": datetime.now()}
for k, v in data["rates"].items() if k in ["USD","EUR","GBP","CNY","KRW"]]
df = pd.DataFrame(rates)
df["JPY換算"] = df["JPY換算"].round(2)
wb = openpyxl.load_workbook("為替管理.xlsx")
ws = wb["レート履歴"]
for _, row in df.iterrows():
ws.append(list(row.values))
wb.save("為替管理.xlsx")
print("最新レートをExcelに追記完了")毎朝9時に最新為替レートを自動取得・追記。手動更新作業が完全不要に。
ステップ4:ピボット展開を自動化する
import pandas as pd
df = pd.read_excel("売上明細.xlsx")
# ピボットテーブル:月×部門×商品カテゴリ
pivot = df.pivot_table(
values="売上金額",
index=["年月", "部門"],
columns="商品カテゴリ",
aggfunc="sum",
fill_value=0
).reset_index()
# 小計行を追加
pivot["合計"] = pivot.select_dtypes("number").sum(axis=1)
with pd.ExcelWriter("ピボット集計.xlsx", engine="openpyxl") as w:
pivot.to_excel(w, sheet_name="月次集計", index=False)
df.to_excel(w, sheet_name="元データ", index=False)
print("ピボット展開完了")月次ピボット集計が自動生成。毎月末の集計作業(3時間)がスクリプト実行20秒に。
ステップ5:差分検出で変更履歴を自動管理
import pandas as pd
old = pd.read_excel("先月データ.xlsx")
new = pd.read_excel("今月データ.xlsx")
# 共通キーで差分検出
merged = old.merge(new, on="顧客ID", suffixes=("_旧","_新"), how="outer", indicator=True)
added = merged[merged["_merge"] == "right_only"][["顧客ID","顧客名_新"]]
removed = merged[merged["_merge"] == "left_only"][["顧客ID","顧客名_旧"]]
changed = merged[(merged["_merge"] == "both") &
(merged["売上金額_旧"] != merged["売上金額_新"])]
with pd.ExcelWriter("差分レポート.xlsx", engine="openpyxl") as w:
added.to_excel(w, sheet_name="新規追加", index=False)
removed.to_excel(w, sheet_name="削除済み", index=False)
changed.to_excel(w, sheet_name="変更あり", index=False)
print(f"追加:{len(added)} 削除:{len(removed)} 変更:{len(changed)}")先月比の差分を自動抽出。変更確認作業(2時間)がスクリプト実行30秒に。
このシステムが解決する課題
データ変換・クレンジングをPythonで自動化。この自動化が特に効果的な場面と、解決できる課題を整理します。
- Power Queryの設定が複雑で、変換手順をチームメンバーに引き継ぎにくい
- 大量データ(100万行以上)をPower Queryで処理すると動作が重くなる
- CSVやAPIなど異なるデータソースを統合するETL処理の設計が難しい
- Power Queryの変換手順をバージョン管理・文書化する方法がわからない
実務での活用シナリオ
導入前後の効果比較
Power Queryで手動設定した変換ステップが多すぎてブラックボックス化。ビジネスロジックが変わるたびにステップを全部やり直していた。100万行のデータ処理は1時間以上かかることも。
pandasでデータ変換ロジックをコードで明示的に記述。処理内容が可読・再利用可能になり、変更が1行修正で完了。100万行のデータも数分で処理完了。
導入のポイントと注意事項
- pandas.read_csv()のdtype引数で読み込み時に型を指定すると、後の変換処理でのエラーを大幅に減らせる
- データクレンジングの処理は関数化して単体テストを書くことで、バグの早期発見と品質担保が実現できる
- 大規模データ(100万行以上)はpolarsライブラリを使うとpandasより10〜50倍高速に処理できる
- ETLパイプラインはAirflowやPrefectで管理するとスケジュール実行・失敗時の再実行・ログ管理が容易になる
業務システム・DX全般のご相談
業務の課題整理からツール選定、システム導入・連携・運用までを幅広く支援します。何から手をつけるべきか迷う段階でも、貴社の状況に合わせて最適な進め方をご提案します。
よくある質問(FAQ)
まとめ
✅ 複数CSVの自動結合・縦積み
✅ 空白・重複・型エラーのクレンジング自動化
✅ Web APIからのリアルタイムデータ取得
✅ ピボット展開と差分検出を完全自動化
どんな現場で使われているか:活用シナリオ
実装で押さえるべき重要ポイント
- 1
pandasでPower Queryの主要操作を代替:merge(結合)・groupby(集計)・pivot_table(ピボット)・str.replace(テキスト変換)でPower Queryの主要操作の大半をPythonで再現できます。
- 2
データ変換ステップをログに記録:各変換ステップの入力件数・出力件数・除外件数をログ出力することで、データ品質の追跡と問題発生時のデバッグが格段に容易になります。
- 3
データソースの変更に対応できる設計にする:CSVのカラム名・フォーマットが変わることを想定して、設定ファイルでカラムマッピングを管理する設計にすることで、スクリプトを書き直さずに対応できます。
ビジネスインパクト
この記事のまとめ
- ✅ PythonでPower Query相当のデータ変換・結合・クレンジングを自動化できる
- ✅ 複数ソースのデータを自動取得・統合してExcelに出力できる
- ✅ Power QueryのM言語より可読性が高くメンテナンスしやすい実装ができる
- ✅ 月次のデータ整備作業を完全自動化して分析業務に集中できる
関連記事