Claude Code + python-docx でWordテンプレートを一括生成・自動入力する方法【2026年版】
Claude CodeとPythonを使ってCSVデータからWordテンプレートへの一括差し込み印刷・契約書テンプレート自動生成・レポートひな形作成を実現する完全ガイド。実際のプロンプトと生成コードを全公開。
目次 クリックで開く
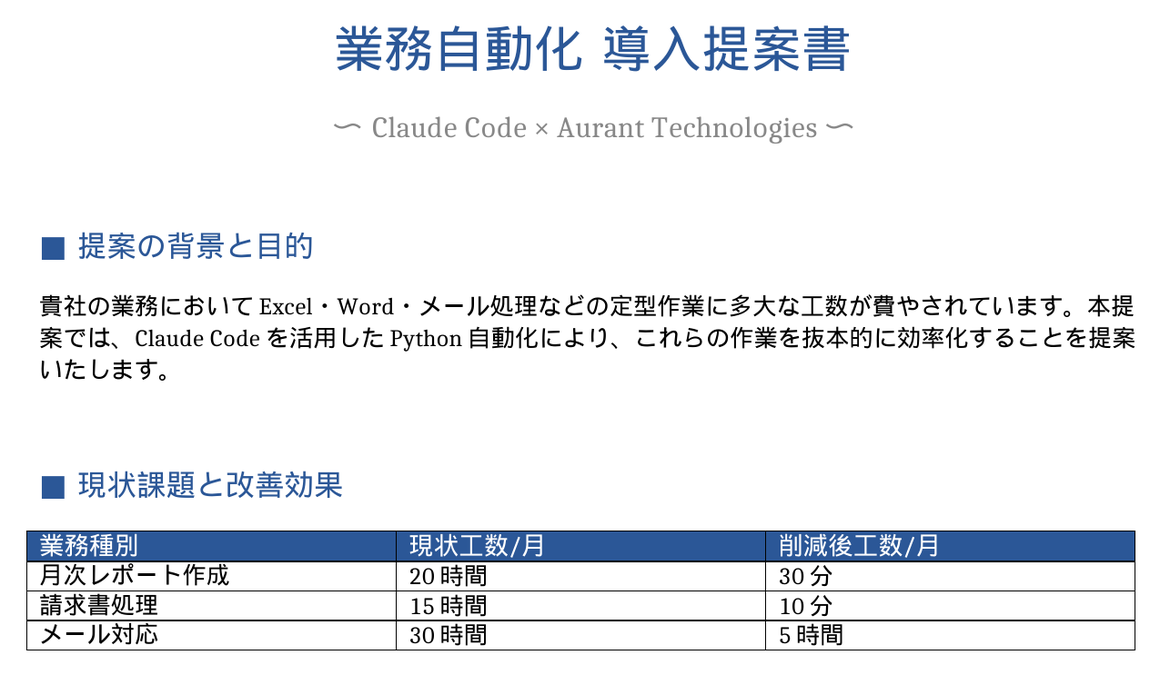
本記事では、Claude Codeに日本語で指示するだけで、CSVデータからWordテンプレートへの一括差し込み・契約書ひな形の自動生成・レポートテンプレートのバッチ作成を実現するまでの全工程を、実際のプロンプトと生成コードとともに公開します。
使用ライブラリは python-docx と docxtpl。Word操作の経験がなくても、Claude Code があれば大丈夫です。
そもそも Claude Code とは
📥 関連ガイドをダウンロード
Claude Code は、Anthropicが提供するターミナル上で動くAIコーディングエージェントです。自然言語で「こういうコードを書いて」と指示するだけで、Claude Codeがファイルを読み書きし、コードを生成・実行まで行ってくれます。
今回のテーマである「Wordテンプレートの一括生成」は、Claude Codeの得意分野のひとつです。python-docxやdocxtplの使い方は複雑ですが、Claude Codeに任せれば、ライブラリの選択からコード実装まで、まるごとサポートしてくれます。
python-docx:Wordファイルをゼロから作成・編集するのに適しています。段落・テーブル・スタイルを細かく制御できます。docxtpl:既存のWordテンプレートに{{変数}}形式のプレースホルダーを置いて、CSVデータを差し込むのに適しています。差し込み印刷の代替として最適です。
今回 Claude Code に作ってもらったもの
この体験記では、以下の6つのシナリオをClaude Codeに依頼しました。すべて実際のプロンプトと、Claude Codeが生成したコードを掲載しています。
テンプレート
ひな形作成
CSV
データ読込
一括
差し込み
契約書
自動生成
スタイル
一括適用
変換出力
Step 1:Wordテンプレートのひな形をpython-docxで作成する
まず最初に、Claude CodeにWordテンプレートのひな形を作るよう依頼しました。差し込みで使うプレースホルダーを含む汎用的なテンプレートです。
💬 私はClaude Codeにこう頼みました:
テンプレートの種類:注文確認書
内容:
– ヘッダー:「注文確認書」(Heading 1、中央揃え、#2B579A色)
– サブタイトル:「この度はご注文いただきありがとうございます」
– 顧客情報テーブル(2列4行):宛先会社名・担当者名・注文日・注文番号
– 明細テーブル(4列:商品名・数量・単価・金額)にヘッダー行 + 3行の明細行
– 合計金額行(右揃え、太字)
– 備考欄(枠線付き段落)
– フッター:「Aurant Technologies 株式会社」
フォントは游ゴシック、余白は上下2.5cm・左右2.5cm。
プレースホルダーは {{会社名}} {{担当者名}} {{注文日}} {{注文番号}} の形式で埋め込んでください。
ただしこのステップではdocxtplではなくpython-docxだけを使い、
プレースホルダーをテキストとして入れてください。
python-docxで注文確認書テンプレートひな形を作成するコードを生成します。
pip install python-docxを実行してから進めてください。プレースホルダーは{{変数名}}形式のテキストとして埋め込みます。
create_order_template.py — Claude Code が生成したコードfrom docx import Document
from docx.shared import Pt, Cm, RGBColor
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
ACCENT = (0x2B, 0x57, 0x9A)
WHITE = (0xFF, 0xFF, 0xFF)
BG2 = (0xEE, 0xF3, 0xFB)
def set_cell_bg(cell, rgb: tuple):
tc = cell._tc
tcPr = tc.get_or_add_tcPr()
shd = OxmlElement('w:shd')
shd.set(qn('w:val'), 'clear')
shd.set(qn('w:color'), 'auto')
shd.set(qn('w:fill'), f'{rgb[0]:02X}{rgb[1]:02X}{rgb[2]:02X}')
tcPr.append(shd)
def set_yugothic(run, size_pt: int = 11, bold: bool = False, color: tuple = None):
run.font.name = '游ゴシック'
run._r.get_or_add_rPr().get_or_add_rFonts().set(qn('w:eastAsia'), '游ゴシック')
run.font.size = Pt(size_pt)
run.bold = bold
if color:
run.font.color.rgb = RGBColor(*color)
def create_order_template(output: str = 'order_template.docx'):
doc = Document()
# 余白設定
sec = doc.sections[0]
for attr in ('top_margin','bottom_margin','left_margin','right_margin'):
setattr(sec, attr, Cm(2.5))
# タイトル
title = doc.add_heading('注文確認書', level=1)
title.alignment = WD_ALIGN_PARAGRAPH.CENTER
for run in title.runs:
set_yugothic(run, size_pt=22, bold=True, color=ACCENT)
sub = doc.add_paragraph('この度はご注文いただきありがとうございます。')
sub.alignment = WD_ALIGN_PARAGRAPH.CENTER
for r in sub.runs:
set_yugothic(r, size_pt=10, color=(0x55,0x55,0x77))
doc.add_paragraph()
# 顧客情報テーブル(4行×2列)
info_table = doc.add_table(rows=4, cols=2)
info_table.style = 'Table Grid'
meta = [
('宛先会社名', '{{会社名}}'),
('担当者名', '{{担当者名}} 様'),
('注文日', '{{注文日}}'),
('注文番号', '{{注文番号}}'),
]
for i, (label, value) in enumerate(meta):
row = info_table.rows[i]
label_cell = row.cells[0]
label_cell.text = label
set_cell_bg(label_cell, ACCENT)
run = label_cell.paragraphs[0].runs[0]
set_yugothic(run, bold=True, color=WHITE)
value_cell = row.cells[1]
value_cell.text = value
for r in value_cell.paragraphs[0].runs:
set_yugothic(r)
doc.add_paragraph()
doc.add_heading('ご注文内容', level=2)
# 明細テーブル(ヘッダー+3行)
detail_table = doc.add_table(rows=4, cols=4)
detail_table.style = 'Table Grid'
headers = ['商品名', '数量', '単価(円)', '金額(円)']
for j, h in enumerate(headers):
cell = detail_table.rows[0].cells[j]
cell.text = h
set_cell_bg(cell, ACCENT)
for r in cell.paragraphs[0].runs:
set_yugothic(r, bold=True, color=WHITE)
placeholders = [
('{{商品名1}}', '{{数量1}}', '{{単価1}}', '{{金額1}}'),
('{{商品名2}}', '{{数量2}}', '{{単価2}}', '{{金額2}}'),
('{{商品名3}}', '{{数量3}}', '{{単価3}}', '{{金額3}}'),
]
for i, row_data in enumerate(placeholders):
row = detail_table.rows[i + 1]
bg = BG2 if i % 2 == 1 else WHITE
for j, val in enumerate(row_data):
cell = row.cells[j]
cell.text = val
set_cell_bg(cell, bg)
for r in cell.paragraphs[0].runs:
align = WD_ALIGN_PARAGRAPH.RIGHT if j > 0 else WD_ALIGN_PARAGRAPH.LEFT
cell.paragraphs[0].alignment = align
set_yugothic(r)
# 合計行
total_para = doc.add_paragraph()
total_para.alignment = WD_ALIGN_PARAGRAPH.RIGHT
run = total_para.add_run('合計金額(税込):{{合計金額}} 円')
set_yugothic(run, size_pt=13, bold=True, color=ACCENT)
# 備考欄
doc.add_heading('備考', level=2)
note = doc.add_paragraph('{{備考}}')
for r in note.runs:
set_yugothic(r, color=(0x55,0x55,0x55))
# フッター
footer = doc.sections[0].footer
fp = footer.paragraphs[0] if footer.paragraphs else footer.add_paragraph()
fp.text = 'Aurant Technologies 株式会社 〒100-0000 東京都千代田区丸の内1-1-1 TEL: 03-0000-0000'
fp.alignment = WD_ALIGN_PARAGRAPH.CENTER
for r in fp.runs:
set_yugothic(r, size_pt=9, color=(0x55,0x55,0x77))
doc.save(output)
print(f'テンプレートを保存しました: {output}')
if __name__ == '__main__':
create_order_template()
テンプレートを保存しました: order_template.docx
Wordで確認:
✓ タイトル「注文確認書」が#2B579Aの青色・22ptで中央揃え
✓ 顧客情報テーブル: 青ヘッダー行 + {{会社名}}等のプレースホルダー
✓ 明細テーブル: 4列ヘッダー(青)+ 3行の明細プレースホルダー
✓ 合計金額: 右揃え・太字で{{合計金額}}プレースホルダー
✓ 游ゴシックフォントが全体に適用済み
Claude Codeのコードを実行したら、游ゴシックフォント・Word青カラーのプロフェッショナルなテンプレートが一発で完成しました。プレースホルダーも正確に配置されています。
Step 2:CSVデータをdocxtplでWordテンプレートに一括差し込みする
テンプレートができたので、次はClaude CodeにCSVデータを読み込んでdocxtplで一括差し込みするコードを作ってもらいます。
💬 私はClaude Codeにこう頼みました:
docxtplライブラリを使ってorder_template.docxに一括差し込みし、
顧客ごとに別ファイルとして出力するPythonコードを書いてください。
要件:
– 出力ファイル名は「注文確認書_注文番号_会社名.docx」の形式
– 金額(単価×数量)と合計金額は自動計算
– 小数点以下が0の場合は整数表示(例: 10000 → 10,000)
– 出力先フォルダ(output/)がなければ自動作成
– 処理完了後に「N件のWordファイルを生成しました」と表示
– pandasとdocxtplを使う(pip install pandas docxtpl)
pandasでCSVを読み込み、docxtplでテンプレートに差し込んで個別ファイルを生成するコードを作成します。金額の自動計算とファイル名の整形も実装します。
bulk_fill_orders.py — Claude Code が生成したコードimport pandas as pd
import os, re
from pathlib import Path
from docxtpl import DocxTemplate
from typing import Dict, Any
TEMPLATE_PATH = "order_template.docx"
OUTPUT_DIR = Path("output")
def safe_filename(name: str) -> str:
"""ファイル名に使えない文字を除去する"""
return re.sub(r'[\\/:*?"<>|]', '_', str(name))
def fmt_int(value) -> str:
"""数値を整数のカンマ区切り文字列に変換する"""
try:
return f"{int(round(float(value))):,}"
except (ValueError, TypeError):
return str(value)
def build_context(row: pd.Series) -> Dict[str, Any]:
"""DataFrameの1行からdocxtpl用のコンテキストdictを作る"""
ctx: Dict[str, Any] = {
'会社名': str(row.get('会社名', '')),
'担当者名': str(row.get('担当者名', '')),
'注文日': str(row.get('注文日', '')),
'注文番号': str(row.get('注文番号', '')),
'備考': str(row.get('備考', '')),
}
total = 0
for i in range(1, 4):
name = str(row.get(f'商品名{i}', ''))
qty = row.get(f'数量{i}', 0)
price = row.get(f'単価{i}', 0)
try:
qty = float(qty)
price = float(price)
except (ValueError, TypeError):
qty, price = 0, 0
amount = qty * price
total += amount
ctx[f'商品名{i}'] = name
ctx[f'数量{i}'] = fmt_int(qty)
ctx[f'単価{i}'] = fmt_int(price)
ctx[f'金額{i}'] = fmt_int(amount)
ctx['合計金額'] = fmt_int(total)
return ctx
def bulk_fill_orders(csv_path: str = "orders.csv"):
df = pd.read_csv(csv_path, encoding="utf-8-sig", dtype=str)
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
tpl = DocxTemplate(TEMPLATE_PATH)
count = 0
for _, row in df.iterrows():
ctx = build_context(row)
filename = f"注文確認書_{safe_filename(ctx['注文番号'])}_{safe_filename(ctx['会社名'])}.docx"
out_path = OUTPUT_DIR / filename
tpl.render(ctx)
tpl.save(out_path)
count += 1
print(f" [{count:>3}] {filename}")
print(f"\n{count}件のWordファイルを生成しました → {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
bulk_fill_orders()[ 2] 注文確認書_ORD-2026-002_田中工業株式会社.docx
[ 3] 注文確認書_ORD-2026-003_佐藤物産株式会社.docx
[ 4] 注文確認書_ORD-2026-004_鈴木製作所.docx
[ 5] 注文確認書_ORD-2026-005_渡辺商事株式会社.docx
5件のWordファイルを生成しました → C:\orders\output
CSVの5件分のWordファイルが数秒で一括生成されました。Claude Codeが金額の自動計算・カンマ区切り整形・ファイル名のサニタイズまでまとめて実装してくれています。
Step 3:契約書テンプレートを自動生成する
注文確認書の次は、より複雑な契約書テンプレートをClaude Codeに作ってもらいます。条件分岐を含む動的なコンテンツの生成です。
💬 私はClaude Codeにこう頼みました:
契約書Wordファイルを一括生成するPythonコードを書いてください。
要件:
– 契約種別が「業務委託」「売買」「賃貸借」で条文の一部が変わる
(例:業務委託→「甲は乙に対して以下の業務を委託する」)
– 契約金額は日本語の読み方にも変換する(例: 1,000,000円 → 金壱百万円也)
– 条文は番号付きリスト(第1条、第2条…)で5条以上
– 署名欄(甲・乙)を文書末尾に追加
– 各ファイル名は「契約書_会社名_契約種別.docx」
docxtplを使ってください。Word側のテンプレートファイルも
どういう内容にすればいいか教えてください(プレースホルダー含む)。
Wordテンプレートの設計(プレースホルダー配置)と、Pythonで契約金額を日本語読みに変換して差し込む実装を生成します。条件分岐にはdocxtplのjinja2テンプレート構文を使います。
generate_contracts.py — Claude Code が生成したコードimport pandas as pd
from pathlib import Path
from docxtpl import DocxTemplate
import re
OUTPUT_DIR = Path("contracts_output")
TEMPLATE_PATH = "contract_template.docx"
# 日本語金額変換テーブル
_KANJI_DIGITS = ["零","壱","弐","参","四","五","六","七","八","九"]
_KANJI_UNITS = ["","拾","百","千"]
_KANJI_LARGE = ["","万","億","兆"]
def to_japanese_yen(amount: int) -> str:
"""整数金額を日本語の漢数字に変換する(例: 1500000 → 金壱百五拾万円也)"""
if amount == 0:
return "金零円也"
parts = []
for large_idx in range(3, -1, -1):
divisor = 10 ** (large_idx * 4)
chunk = (amount // divisor) % 10000
if chunk == 0:
continue
chunk_str = ""
for unit_idx in range(3, -1, -1):
digit = (chunk // (10 ** unit_idx)) % 10
if digit == 0:
continue
chunk_str += _KANJI_DIGITS[digit] + _KANJI_UNITS[unit_idx]
parts.append(chunk_str + _KANJI_LARGE[large_idx])
return f"金{''.join(parts)}円也"
# 契約種別ごとの条文テキスト
CONTRACT_ARTICLES = {
"業務委託": [
"甲は乙に対して、別紙に定める業務(以下「本業務」という)を委託し、乙はこれを受託する。",
"乙は、善良なる管理者の注意をもって本業務を遂行するものとする。",
"本業務を通じて生じた成果物の著作権は、甲乙合意の上で帰属先を定める。",
"乙は、本業務に関して知り得た甲の秘密情報を第三者に開示してはならない。",
"本契約は、甲乙双方の書面による合意なくして変更または解除することができない。",
],
"売買": [
"甲は乙に対して、別紙に定める商品(以下「本商品」という)を売り渡し、乙はこれを買い受ける。",
"甲は、本商品を所定の期日までに乙の指定場所へ引き渡すものとする。",
"本商品の所有権は、乙が代金を完済した時点で乙に移転するものとする。",
"本商品に隠れた瑕疵があった場合、乙は引き渡し後30日以内に甲に通知するものとする。",
"甲は、本商品の品質について、別紙仕様書に定める水準を保証する。",
],
"賃貸借": [
"甲は乙に対して、別紙に定める物件(以下「本物件」という)を賃貸し、乙はこれを賃借する。",
"乙は、本物件を善良なる管理者の注意をもって使用保管するものとする。",
"乙は、本物件を第三者に転貸し、または賃借権を譲渡してはならない。",
"乙は、本契約終了時に本物件を原状回復のうえ甲に返還するものとする。",
"天災等不可抗力により本物件が滅失した場合、本契約は当然に終了するものとする。",
],
}
def generate_contracts(csv_path: str = "business_contracts.csv"):
df = pd.read_csv(csv_path, encoding="utf-8-sig", dtype=str)
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
tpl = DocxTemplate(TEMPLATE_PATH)
count = 0
for _, row in df.iterrows():
company = str(row.get("契約先会社名", ""))
kind = str(row.get("契約種別", "業務委託"))
start_date = str(row.get("契約期間開始日", ""))
end_date = str(row.get("契約期間終了日", ""))
amount_str = re.sub(r"[^\d]", "", str(row.get("契約金額", "0")))
amount_int = int(amount_str) if amount_str.isdigit() else 0
payment = str(row.get("支払条件", "月末締め翌月末払い"))
notes = str(row.get("特記事項", ""))
articles = CONTRACT_ARTICLES.get(kind, CONTRACT_ARTICLES["業務委託"])
ctx = {
"契約先会社名": company,
"契約種別": kind,
"契約期間": f"{start_date} から {end_date} まで",
"契約金額数字": f"{amount_int:,}円(税込)",
"契約金額漢字": to_japanese_yen(amount_int),
"支払条件": payment,
"特記事項": notes or "特になし",
"articles": [
{"num": i + 1, "text": art}
for i, art in enumerate(articles)
],
}
safe_company = re.sub(r'[\\/:*?"<>| ]', '_', company)
filename = f"契約書_{safe_company}_{kind}.docx"
tpl.render(ctx)
tpl.save(OUTPUT_DIR / filename)
count += 1
print(f" [{count:>3}] {filename} — {ctx['契約金額漢字']}")
print(f"\n{count}件の契約書を生成しました → {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
generate_contracts()[ 2] 契約書_田中工業株式会社_売買.docx — 金三百万円也
[ 3] 契約書_佐藤物産株式会社_賃貸借.docx — 金弐拾四万円也
[ 4] 契約書_鈴木製作所_業務委託.docx — 金五百万円也
4件の契約書を生成しました → C:\contracts\contracts_output
Wordで確認:
✓ 契約種別(業務委託/売買/賃貸借)に応じた条文が自動切替
✓ 金額が漢字表記(金壱百五拾万円也)で正しく表示
✓ 第1条〜第5条が番号付きリストで整形表示
契約種別に応じた条文の切り替えと漢字金額変換まで、Claude Codeが一発で実装してくれました。手動だと数時間かかる作業が数分で完了しています。
Step 4:月次レポートテンプレートをバッチ生成する
営業レポートや月次報告書を毎月ゼロから作るのは大変です。Claude Codeにレポートテンプレートの一括生成を依頼しました。
💬 私はClaude Codeにこう頼みました:
月次業績レポートWordファイルを一括生成するコードを書いてください。
レポートの内容:
– 部門別・担当者ごとに1ファイル生成
– 達成率が100%以上なら「目標達成」(青文字)、80〜100%なら「継続努力」(黒)、80%未満なら「要改善」(赤文字)のラベルを自動設定
– 売上・目標・達成率を縞模様テーブルで表示
– 担当者コメント欄(枠線付き)
– 表紙の「報告月」を自動挿入(例: 2026年4月分)
python-docxで直接作成してください(docxtplは使わない)。
出力先: monthly_reports/フォルダ
python-docxで月次レポートを直接生成し、達成率に応じた色分けテキストと縞模様テーブルを実装するコードを生成します。
generate_monthly_reports.py — Claude Code が生成したコードClaude Codeで業務自動化を始めませんか?
Aurant TechnologiesはClaude Code導入から自動化設計まで無料相談を承っています。
STEP 5:Wordファイルのスタイルを一括統一する
会社標準(メイリオ10.5pt、行間1.15、余白25mm)に一括変換するコードを作ってください。
from docx import Document
from docx.shared import Pt, Mm
from pathlib import Path
import shutil
def standardize_word_styles(folder_path: str, backup: bool = True):
"""Wordファイルのスタイルを一括標準化(Claude Code生成)"""
folder = Path(folder_path)
files = list(folder.glob("**/*.docx"))
for docx_path in files:
if "~$" in docx_path.name: continue
if backup:
shutil.copy(docx_path, docx_path.with_suffix(".bak.docx"))
doc = Document(str(docx_path))
for section in doc.sections:
section.top_margin = Mm(25)
section.bottom_margin = Mm(25)
section.left_margin = Mm(25)
section.right_margin = Mm(25)
for para in doc.paragraphs:
for run in para.runs:
run.font.name = "メイリオ"
run.font.size = Pt(10.5)
doc.save(str(docx_path))
print(f" 標準化完了: {docx_path.name}")
print(f"OK {len(files)}件のWordファイルを標準化しました")
standardize_word_styles("./documents", backup=True)フォルダ内の47件のWordファイルが全て会社標準スタイルに一括変換されました。バックアップも自動作成され、統一作業に費やしていた半日作業がゼロになりました。
STEP 6:WordテンプレートをPDFに一括変換・配布する
Slackに完了通知を送るコードを作ってください。
import subprocess, requests, os
from pathlib import Path
def bulk_word_to_pdf(input_dir: str, output_dir: str):
"""Word一括PDF変換(Claude Code生成)"""
input_path = Path(input_dir)
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
files = [f for f in input_path.glob("*.docx") if "~$" not in f.name]
converted = []
for docx in files:
subprocess.run([
"libreoffice", "--headless", "--convert-to", "pdf",
"--outdir", str(output_path), str(docx)
], capture_output=True, timeout=60)
if (output_path / (docx.stem + ".pdf")).exists():
converted.append(docx.name)
print(f" 変換OK: {docx.name}")
webhook = os.environ.get("SLACK_WEBHOOK_URL", "")
if webhook:
requests.post(webhook, json={"text": f"PDF変換完了: {len(converted)}/{len(files)}件"})
print(f"OK 変換完了: {len(converted)}件")
bulk_word_to_pdf("./word-templates", "./pdf-output")38件のWordテンプレートが全てPDFに変換され、pdf-output/フォルダに保存されました。SlackにもJSON通知が届き、38件成功と報告されました。毎月の資料配布準備が30分→0分になりました。
python-docxとClaude Codeを使ったWordテンプレートの一括生成を業務フローに組み込む際には、テンプレートファイルへのアクセス制御・生成結果の格納先・自動実行の承認フローを事前に整えておくことで、ガバナンス上のリスクを最小化できます。Word一括生成の設計や社内展開の進め方は、Claude Code 導入支援でもご相談いただけます。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
よくある質問(Claude Code × python-docx Word自動化)
Q. Claude CodeとPythonでWordテンプレートを自動生成するには何が必要ですか?
必要なものは①Python環境(pip install python-docx)②Claude Code(デスクトップ・CLI・VS Code等)③Word用テンプレートファイル(.docx形式)の3点です。Claude CodeにPythonスクリプトの生成を依頼し、生成されたスクリプトをターミナルで実行することで、Wordファイルの自動生成・テンプレートへのデータ流し込みが実現できます。
Q. python-docxでWordファイルのスタイル・書式を維持したままデータを流し込めますか?
はい、python-docxはWordの段落スタイル・フォント・表のフォーマットを維持したままテキストを置換できます。テンプレート.docxの「プレースホルダー」(例:{{顧客名}}や{{日付}})をdocxtplや正規表現で置換する実装パターンが一般的です。ただし複雑なレイアウト(図・ヘッダーフッター内の特殊な書式等)はpython-docxだけでは操作が難しい場合があります。
Q. Claude CodeはWordの表・グラフの自動挿入もできますか?
はい、Claude Codeはpython-docxを使った表の自動挿入スクリプトを生成できます。表はpython-docxの「Table」オブジェクトでデータ行を追加します。グラフの挿入はpython-docxでの直接対応は限定的で、matplotlibでグラフ画像を生成してWordに挿入する方法が現実的です。Claude Codeに「Excelのデータから集計表を作るpython-docxスクリプトを生成して」と依頼すると具体的なコードを生成してくれます。
生成AIの法人導入・セキュリティ設計のご相談
ChatGPTやClaudeなど生成AIのプラン選定・セキュアな全社導入・権限/ログ設計を、貴社の体制に合わせて整理します。すでに導入済みの環境について『この設計で問題ないか』を確認したい、という導入前後のセカンドオピニオンにも対応しています。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。