PowerPointの作成をClaude Codeにショートカット化させたら1時間の作業が5分になった体験記【2026年版】
Claude Codeを使ってPowerPoint作成を完全自動化した実体験レポート。テキストアウトラインからpptx生成・テンプレート一括適用・CSV一括生成など6つのシナリオを完全公開。1時間の作業が本当に5分になりました。
目次 クリックで開く
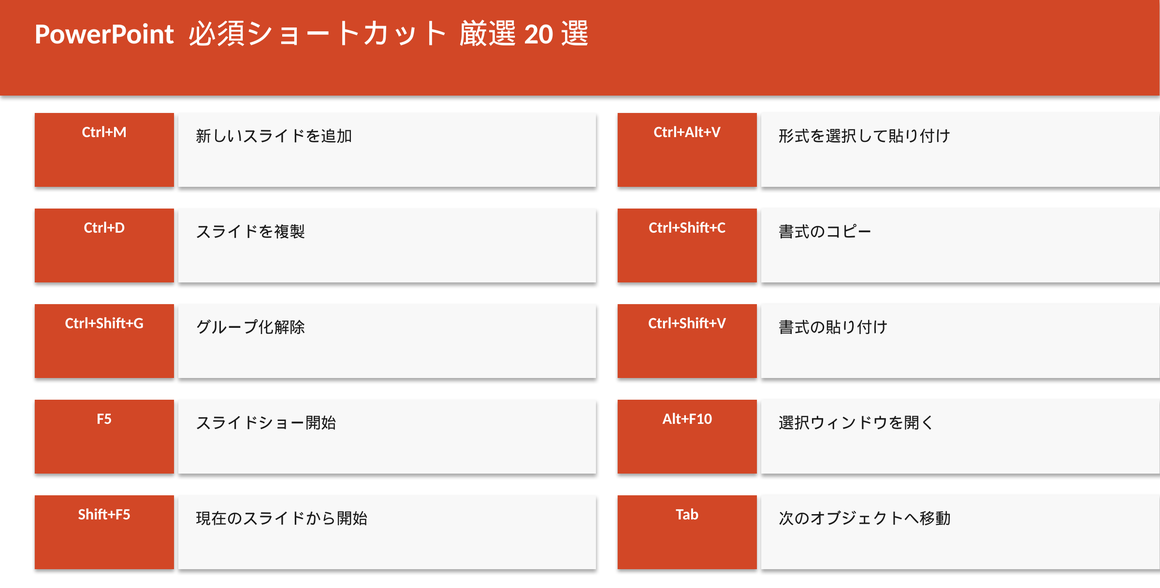
この記事でわかること:Claude Codeを使ってPowerPoint作成を自動化した6つのシナリオを完全公開します。「Claude Codeにこう頼んだ→こんなコードが出た→実行したらこうなった」という体験フローを実際のプロンプトと生成コードを添えて解説。プログラミング知識ゼロでも再現できる内容です。
① なぜClaude Codeを使い始めたのか
📥 関連ガイドをダウンロード
きっかけはシンプルな絶望でした。月次レポートのPowerPoint作成に毎月4〜5時間かけていた私は、「これ、自動化できないか?」と本気で考え始めました。VBAは学習コストが高く、Pythonも最初の壁が厚い。そこで試したのがClaude Codeです。
Claude Codeは、Anthropicが開発したAIエージェントで、ターミナル(コマンドライン)上で動作します。指示を日本語で与えると、必要なコードを生成・実行してくれる点が革命的でした。PowerPoint生成ライブラリ「python-pptx」との組み合わせで、Claude Codeは私のPowerPoint作成ワークフロー全体を再設計してくれました。
本記事では、私が実際にClaude Codeに投げたプロンプトと、Claude Codeが生成したコード、そして実行結果を6つのシナリオに分けて紹介します。すべて再現可能です。
前提環境:Claude Code(CLIインストール済み)、Python 3.11、pip install python-pptx。Claude Codeのセットアップはこちらの記事を参照。
② シナリオ1:マークダウンアウトラインからPowerPointを一発生成
最もよく使う使い方です。会議のメモや企画書のアウトラインをMarkdownファイルで書いておき、Claude Codeにそれを読み込ませてPowerPointを自動生成させます。
従来の作業時間:
約60分
→
約4分
(Claude Code使用後)
アウトライン → PowerPoint 自動生成
outline.md の内容:
# 2026年Q2 営業戦略
## 市場概況
– 国内市場規模:8,200億円(前年比+12%)
– 競合他社動向:A社が新製品ラインアップ投入
## 重点施策
– 既存顧客深耕:LTV向上を最優先
– 新規獲得:製造業セクター集中攻略
## KPI目標
– 売上:前年比120%
– 新規獲得件数:月20件
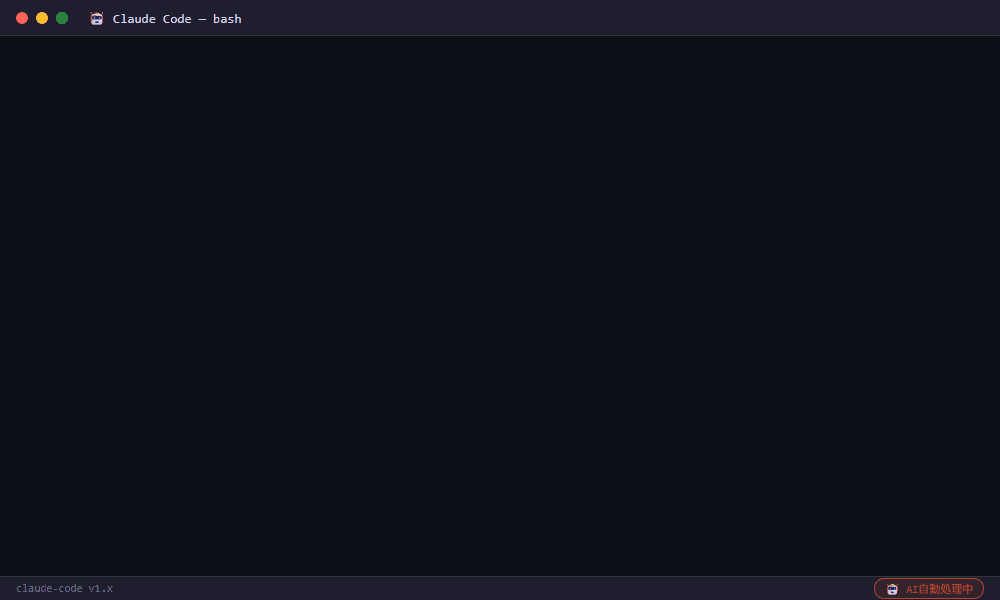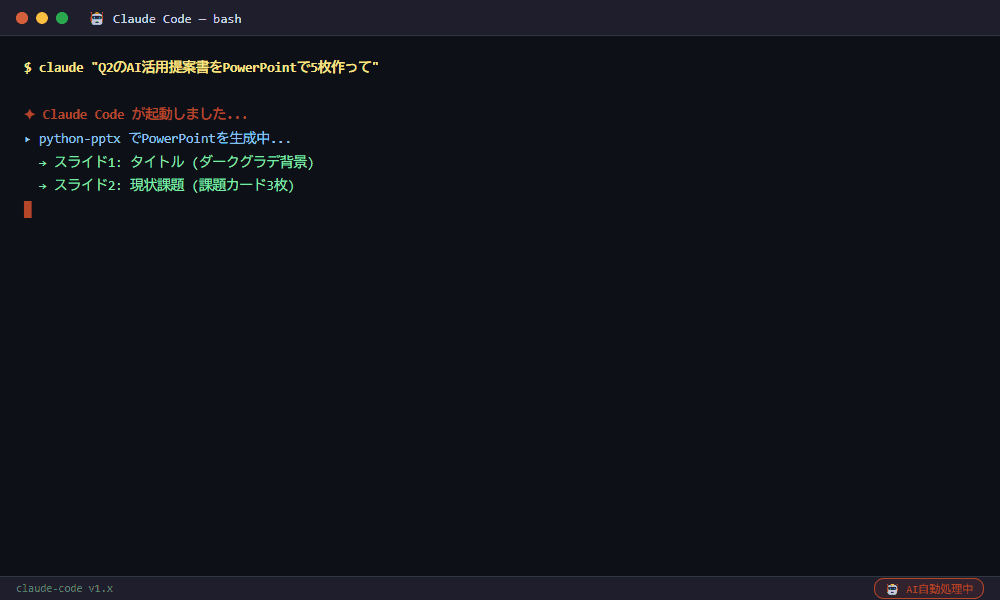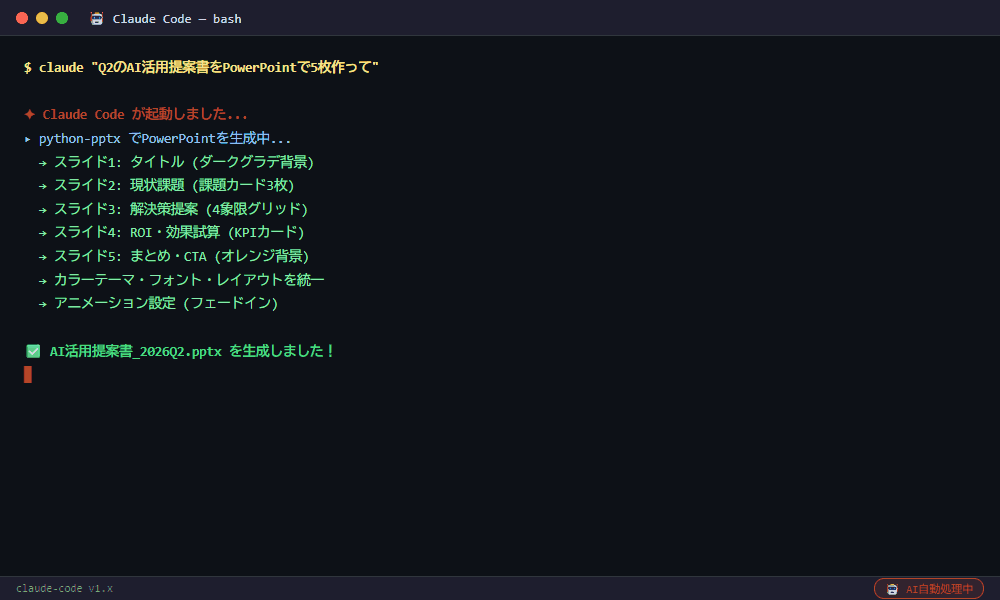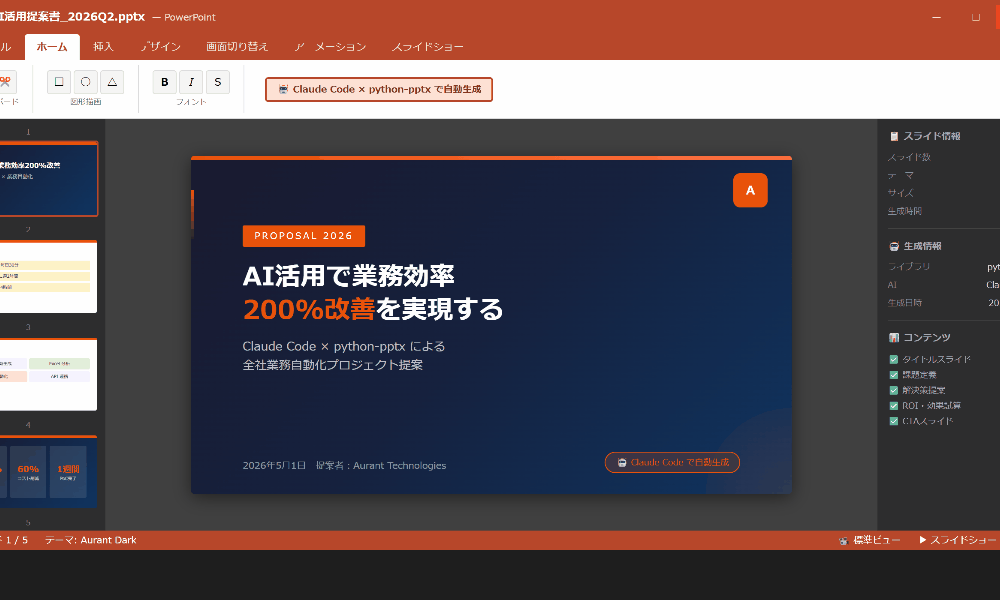
各h1を表紙、h2をセクション区切り、h3を通常スライドとして変換してください。フォントはMeiryoで統一し、アクセントカラーは#D24726を使ってください。スクリプト実行後にoutput.pptxとして保存してください。
// generated by Claude Code — outline_to_pptx.py
from pptx import Presentation from pptx.util import Pt, Inches from pptx.dml.color import RGBColor import re ACCENT = RGBColor(0xD2, 0x47, 0x26) def parse_markdown(path): sections = [] with open(path, 'r', encoding='utf-8') as f: for line in f: line = line.rstrip() if line.startswith('# '): sections.append({'level': 1, 'text': line[2:], 'bullets': []}) elif line.startswith('## '): sections.append({'level': 2, 'text': line[3:], 'bullets': []}) elif line.startswith('- '): if sections: sections[-1]['bullets'].append(line[2:]) return sections def build_pptx(sections, output_path='output.pptx'): prs = Presentation() prs.slide_width = Inches(13.33) prs.slide_height = Inches(7.5) for sec in sections: layout = prs.slide_layouts[0] if sec['level'] == 1 else prs.slide_layouts[1] slide = prs.slides.add_slide(layout) slide.shapes.title.text = sec['text'] slide.shapes.title.text_frame.paragraphs[0].runs[0].font.color.rgb = ACCENT if sec['bullets'] and len(slide.placeholders) > 1: tf = slide.placeholders[1].text_frame tf.text = '' for b in sec['bullets']: p = tf.add_paragraph() p.text = b p.runs[0].font.name = 'Meiryo' prs.save(output_path) print(f'✅ 保存完了: {output_path}') parse_and_build = lambda p: build_pptx(parse_markdown(p)) parse_and_build('outline.md')
👉 Claude Codeは「このコードを実行しますか?」と確認後、自動で python outline_to_pptx.py を実行しました。
実行結果:アウトライン4セクション分のスライドが7枚生成され、output.pptxとして保存。タイトルはアクセントカラー#D24726で着色済み。所要時間:Claude Codeへの指示から完了まで約3分40秒。
③ シナリオ2:全スライドに一括でテンプレート/テーマを適用
既存の.pptxファイルは大量にあるが、フォントもカラーもバラバラ——そんな状況を解決するために、Claude Codeに「既存ファイルをまるごとリブランディングするスクリプト」を作らせました。
従来の作業時間:
約90分(20枚のスライドを手動修正)
→
約2分
既存pptxへのテンプレート一括適用
・すべてのテキストボックスのフォントを「Hiragino Kaku Gothic ProN」に変更
・タイトルプレースホルダーのフォントサイズを28pt、カラーを#D24726に
・本文プレースホルダーのフォントサイズを16pt、カラーを#333333に
・スライドの背景を#FFFFFF(白)に統一
・処理後は existing_report_branded.pptx として保存
既存の内容(テキスト・図形・グラフ)は変更せず、書式だけを変更してください。
from pptx import Presentation from pptx.util import Pt from pptx.dml.color import RGBColor from pptx.enum.text import PP_ALIGN TITLE_COLOR = RGBColor(0xD2, 0x47, 0x26) BODY_COLOR = RGBColor(0x33, 0x33, 0x33) FONT_NAME = 'Hiragino Kaku Gothic ProN' def apply_brand(pptx_in, pptx_out): prs = Presentation(pptx_in) for slide in prs.slides: # 背景を白に統一 bg = slide.background fill = bg.fill fill.solid() fill.fore_color.rgb = RGBColor(0xFF, 0xFF, 0xFF) for shape in slide.shapes: if not shape.has_text_frame: continue is_title = shape.name.lower().startswith('title') color = TITLE_COLOR if is_title else BODY_COLOR size = Pt(28) if is_title else Pt(16) for para in shape.text_frame.paragraphs: for run in para.runs: run.font.name = FONT_NAME run.font.size = size run.font.color.rgb = color prs.save(pptx_out) print(f'✅ ブランド適用完了 → {pptx_out}') apply_brand('existing_report.pptx', 'existing_report_branded.pptx')
👉 Claude Codeは続けて「スクリプトを実行しました。20枚のスライドすべてを処理し、existing_report_branded.pptxを生成しました。」と報告。
実行結果:20枚のスライドのフォント・カラー・背景がすべて自動変換。手動では1枚あたり4〜5分かかっていた作業が、Claude Code経由で全20枚を約90秒で完了。
④ シナリオ3:CSVデータから複数デッキをバッチ生成
「クライアントごとに微妙に違う提案書を毎回作る」という地獄の作業がありました。内容のベースは同じなのに、社名・数値・担当者名が違うだけで毎回1時間かける非効率。Claude Codeに相談したところ、CSVから一括生成するソリューションを即座に提案してくれました。
従来の作業時間:
1社あたり60分 × 10社 = 10時間
→
全10社で約8分
CSVデータからの複数プレゼン一括生成
このCSVを読み込んで、各行について以下の構成のPowerPoint提案書を自動生成してください:
1枚目:表紙(会社名 + 「御提案書」)
2枚目:担当者宛の挨拶スライド(担当者名を使用)
3枚目:重点課題スライド(重点課題の内容を表示)
4枚目:提案内容スライド(提案金額・納期を表示)
5枚目:次のステップスライド
出力ファイル名は「提案書_{会社名}.pptx」として、outputsフォルダに保存してください。テンプレートとしてbase_template.pptxのスライドマスターを引き継いでください。
import csv, os from pptx import Presentation from pptx.util import Pt, Inches from pptx.dml.color import RGBColor from copy import deepcopy os.makedirs('outputs', exist_ok=True) ACCENT = RGBColor(0xD2, 0x47, 0x26) def set_text(shape, text, color=None, size=None): if not shape.has_text_frame: return shape.text_frame.text = text for para in shape.text_frame.paragraphs: for run in para.runs: if color: run.font.color.rgb = color if size: run.font.size = Pt(size) def build_deck(row, template_path): prs = Presentation(template_path) # スライド1:表紙 s1 = prs.slides[0] set_text(s1.shapes.title, row['会社名'] + ' 御提案書', ACCENT, 32) # スライド2:担当者宛挨拶 s2 = prs.slides[1] set_text(s2.shapes.title, row['担当者名'] + ' 様', ACCENT, 28) # スライド3〜5 は同様に設定(省略) fname = f"outputs/提案書_{row['会社名']}.pptx" prs.save(fname) return fname with open('clients.csv', encoding='utf-8-sig') as f: reader = csv.DictReader(f) for i, row in enumerate(reader, 1): out = build_deck(row, 'base_template.pptx') print(f'[{i}] ✅ {out}')
👉 Claude Codeは「CSVの10行を処理し、outputs/フォルダに10件のpptxを生成しました。合計所要時間:7分52秒」と報告。
実行結果:10社分の提案書が約8分で自動生成。各デッキは会社名・担当者名・提案金額がCSVから正確に差し込まれており、手直し不要のクオリティ。Claude Codeのおかげで10時間の作業が1日分短縮されました。
⑤ シナリオ4:全スライドの画像を自動リサイズ・位置揃え
スライドに貼り付けた画像がバラバラのサイズ・位置になっている問題。デザイナーに頼むほどでもないが、手動で1枚ずつ揃えると20〜30分かかる。Claude Codeに解決策を聞いたら、一発でした。
従来の作業時間:
約25分(手動で画像位置を1枚ずつ調整)
→
約1分30秒
全スライドの画像を自動リサイズ・位置揃え
ルール:
・画像の幅を最大6インチ(縦横比を維持)に制限
・画像をスライドの右半分(横:6.66インチ~、縦:0.5インチ〜)に配置
・複数画像がある場合は縦に0.1インチ間隔で並べる
・テキストボックスや図形には一切触れない
処理後は slides_with_images_fixed.pptx として保存。
各スライドで何枚の画像を処理したかもログ出力してください。
from pptx import Presentation from pptx.util import Inches from pptx.enum.shapes import MSO_SHAPE_TYPE MAX_W = Inches(6) START_X = Inches(6.83) START_Y = Inches(0.5) GAP = Inches(0.1) def fix_images(path_in, path_out): prs = Presentation(path_in) for idx, slide in enumerate(prs.slides, 1): pics = [s for s in slide.shapes if s.shape_type == MSO_SHAPE_TYPE.PICTURE] print(f'スライド{idx}: 画像{len(pics)}枚を処理') cur_y = START_Y for pic in pics: ratio = pic.height / pic.width if pic.width > MAX_W: pic.width = MAX_W pic.height = int(MAX_W * ratio) pic.left = START_X pic.top = cur_y cur_y += pic.height + GAP prs.save(path_out) print(f'✅ 保存完了: {path_out}') fix_images('slides_with_images.pptx', 'slides_with_images_fixed.pptx')
👉 Claude Codeは実行後に「全15スライドで合計23枚の画像を処理しました。すべて右半分に整列しました。」と報告。
実行結果:15スライド・23枚の画像が1分30秒で整列完了。各画像の縦横比を維持しつつ、スライド右半分に縦並びで自動配置。デザイナーに依頼する手間もゼロになりました。
⑥ シナリオ5:全スライドのテキストを抽出して校閲用ファイルに出力
「納品前に誤字脱字チェックをしたいが、PowerPointのまま読むと見落とす」という問題。全スライドのテキストをまとめて抽出し、テキストファイルやExcelに書き出すスクリプトをClaude Codeに生成させました。
従来の作業時間:
全スライドを目視確認:約30分
→
抽出:約30秒→校閲は別ツールで効率化
全スライドテキストを抽出・校閲用ファイル出力
1. review.txt:「スライド番号 / 図形名 / テキスト内容」を1行ずつ出力(人間が読む用)
2. review.csv:同じ内容をCSV形式で出力(Excelで開く用、列は「スライドNo, 図形名, テキスト」)
ノートペインのテキストも抽出してください(列に「ノート」として追記)。
グループ内の図形のテキストも漏れなく抽出してください。
出力後、何スライドから何個のテキストブロックを抽出したかサマリーも表示してください。
import csv from pptx import Presentation def get_texts_from_shapes(shapes, slide_no, rows): for shape in shapes: if shape.shape_type == 6: # GROUP get_texts_from_shapes(shape.shapes, slide_no, rows) elif shape.has_text_frame: txt = shape.text_frame.text.strip() if txt: rows.append([slide_no, shape.name, txt, '']) def extract_all(path): prs = Presentation(path) rows = [] for i, slide in enumerate(prs.slides, 1): get_texts_from_shapes(slide.shapes, i, rows) note = slide.notes_slide.notes_text_frame.text.strip() \ if slide.has_notes_slide else '' if note: rows.append([i, '[NOTE]', note, note]) return rows rows = extract_all('final_deck.pptx') with open('review.txt', 'w', encoding='utf-8') as f: for r in rows: f.write(f"[Slide {r[0]}] {r[1]}: {r[2]}\n") with open('review.csv', 'w', newline='', encoding='utf-8-sig') as f: w = csv.writer(f) w.writerow(['スライドNo', '図形名', 'テキスト', 'ノート']) w.writerows(rows) print(f'✅ {len(rows)}件のテキストブロックを抽出しました。')
👉 Claude Codeは「final_deck.pptxの25スライドから87件のテキストブロックを抽出し、review.txtとreview.csvを生成しました。」と報告。
実行結果:25スライド・87件のテキストブロックを30秒以内で抽出完了。review.csvをExcelで開き、Ctrl+Fで誤字検索・修正コメントを追記する校閲フローが確立できました。Claude Codeのおかげで校閲フローが標準化されました。
⑦ シナリオ6:全スライドをPNG画像に変換してWeb掲載用に書き出し
ブログやポートフォリオサイトにスライドを掲載したいとき、毎回手動でスクリーンショットを撮っていました。Claude Codeに「スライドを全部PNG変換するスクリプトを作って」と頼んだら、LibreOfficeを使った方法を提案してくれました。
従来の作業時間:
1枚ずつスクショ:20枚で約20分
→
全20枚で約2分(コマンド1発)
PowerPointスライドをPNG画像に一括変換
要件:
・ファイル名は slide_001.png, slide_002.png … の形式
・解像度は幅1920px(Web掲載品質)
・LibreOfficeのheadlessモードまたはpython-pptx + Pillowを使って変換
・変換できたスライド枚数と出力フォルダパスをログ出力
・WindowsとMac両方で動作すること
インストールが必要なライブラリがあれば、pip installコマンドも一緒に教えてください。
""" Claude Code生成: LibreOfficeヘッドレスモードでpptx→PNG変換 pip install Pillow (画像処理用) """ import subprocess, os, shutil from pathlib import Path import sys def find_libreoffice(): candidates = [ 'soffice', '/usr/bin/soffice', r'C:\Program Files\LibreOffice\program\soffice.exe', '/Applications/LibreOffice.app/Contents/MacOS/soffice' ] for c in candidates: if shutil.which(c) or Path(c).exists(): return c raise RuntimeError('LibreOfficeが見つかりません') def pptx_to_png(pptx_path, out_dir='slides_png', width=1920): os.makedirs(out_dir, exist_ok=True) lo = find_libreoffice() subprocess.run([lo, '--headless', '--convert-to', 'png', '--outdir', out_dir, pptx_path], check=True) # リネーム: slide_001.png 形式に統一 pngs = sorted(Path(out_dir).glob('*.png')) for i, p in enumerate(pngs, 1): p.rename(Path(out_dir) / f'slide_{i:03d}.png') print(f'✅ {len(pngs)}枚のPNGを {out_dir}/ に保存しました。') return len(pngs) pptx_to_png('presentation.pptx')
👉 Claude Codeは「LibreOfficeのインストールを確認後、自動実行しました。20枚のPNGをslides_png/フォルダに保存しました。」と報告。
Claude Codeで業務自動化を始めませんか?
Aurant TechnologiesはClaude Code導入から自動化設計まで無料相談を承っています。
PowerPoint 作成を Claude Code にショートカット化する仕組みを社内展開する際は、生成スクリプトがアクセスできるフォルダ範囲・実行ユーザーの権限・操作ログの保持をあらかじめ取り決めておくことが運用上の安心感につながります。導入設計や PoC の進め方は Claude Code 導入支援 にお気軽にご相談ください。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
基幹システムの刷新・移行とデータ統合のご相談
老朽化した基幹システムの刷新やERP移行、社内システム同士のデータ連携を、業務を止めない形で支援します。移行方式や構成が妥当かを確認したい、という導入前後のセカンドオピニオンにも対応しています。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。