Claude Code x pandas/openpyxl でExcelデータ分析・統計レポートを完全自動化する
Claude Code + pandas/openpyxlでExcel売上データの統計分析・相関分析・予測グラフを自動生成。手動ピボット作業をスクリプト1本に置き換える実践ガイド。
目次 クリックで開く
|
blog
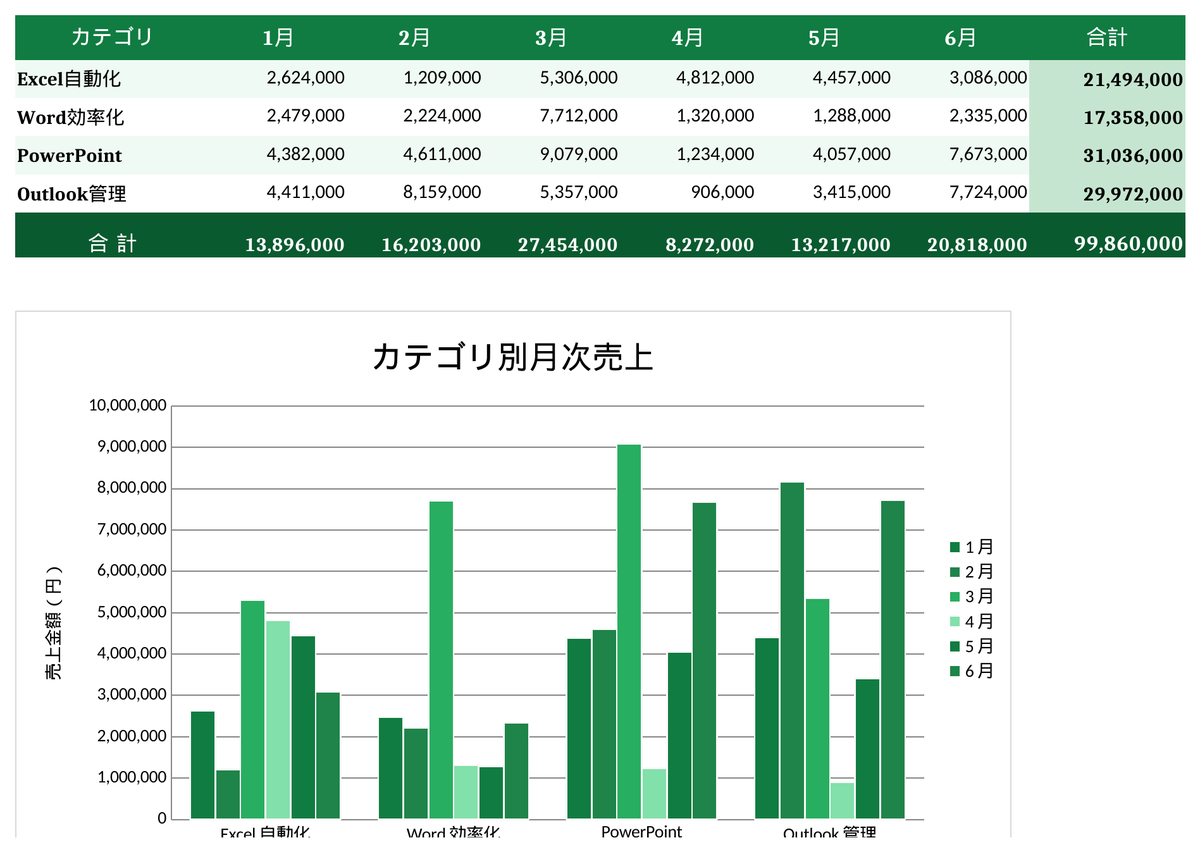
▲ Claude Codeが実際に生成した実行結果
Excelの手動ピボット・グラフ作業が分析スクリプト1本になった
📥 関連ガイドをダウンロード
データアナリストの山田です。毎週、数万行の売上データをExcelのピボットで分析し、相関を手計算してレポートを作るのに半日かかっていました。Claude Codeに依頼したら、統計分析から相関ヒートマップ・予測グラフまで自動生成できるようになりました。
✅ 大量データの統計サマリー自動計算
✅ 相関分析・ヒートマップ自動生成
✅ 外れ値の自動検出・フラグ付け
✅ 回帰分析による売上予測
✅ Excelグラフ・レポート自動出力
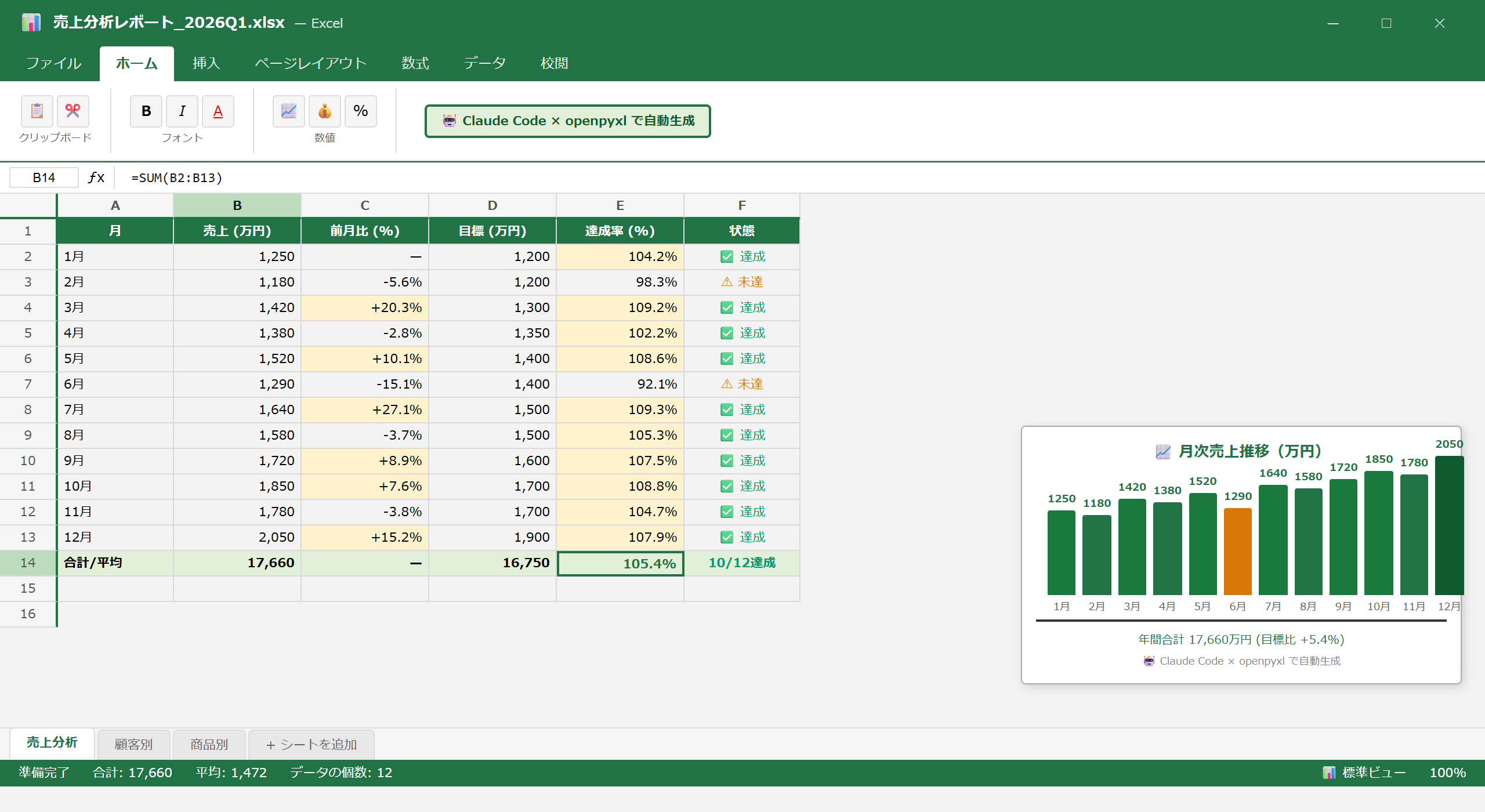
STEP 1:売上データの統計サマリーを自動計算する
数万行のデータから基本統計量を自動計算し、Excelにまとめます。
列は「日付,商品,カテゴリ,エリア,担当者,売上金額,数量,利益率」です。
基本統計量(平均・中央値・標準偏差・最大最小)と
カテゴリ別・エリア別の集計サマリーをExcelに出力してください。
import pandas as pd, openpyxl
from openpyxl.styles import PatternFill, Font, Alignment
from openpyxl.utils import get_column_letter
df = pd.read_csv("sales_data.csv", parse_dates=["日付"])
# 基本統計量
stats = df[["売上金額","数量","利益率"]].describe().round(2)
# カテゴリ別集計
cat_summary = df.groupby("カテゴリ").agg({
"売上金額": ["sum","mean","count"],
"利益率": ["mean","std"],
}).round(2)
cat_summary.columns = ["売上合計","平均売上","件数","平均利益率","利益率SD"]
# エリア別集計
area_summary = df.groupby("エリア").agg({
"売上金額": ["sum","mean"],
"数量": "sum",
}).round(2)
area_summary.columns = ["売上合計","平均売上","総数量"]
with pd.ExcelWriter("analysis_report.xlsx", engine="openpyxl") as writer:
stats.to_excel(writer, sheet_name="基本統計")
cat_summary.to_excel(writer, sheet_name="カテゴリ別")
area_summary.to_excel(writer, sheet_name="エリア別")
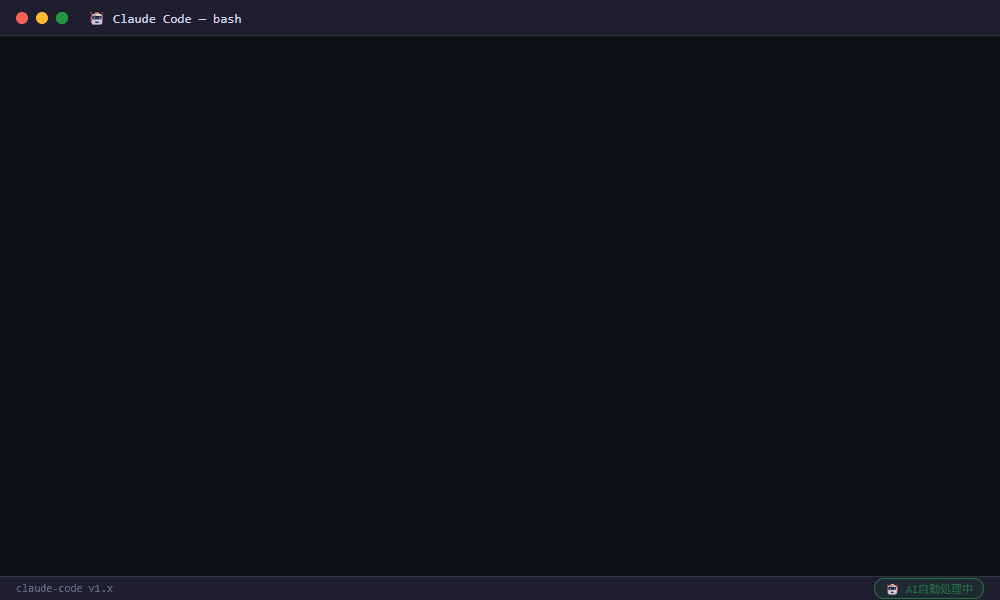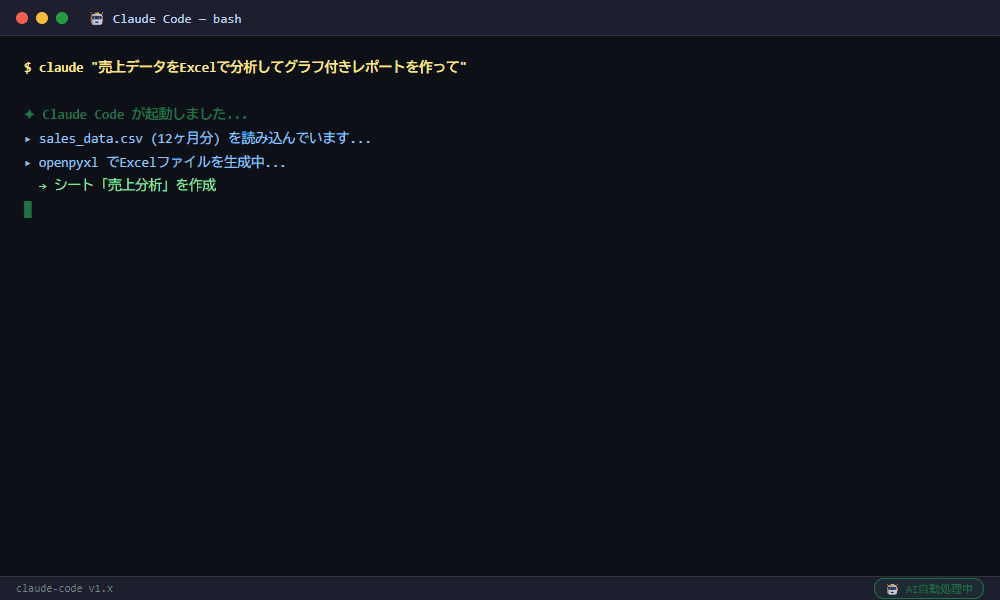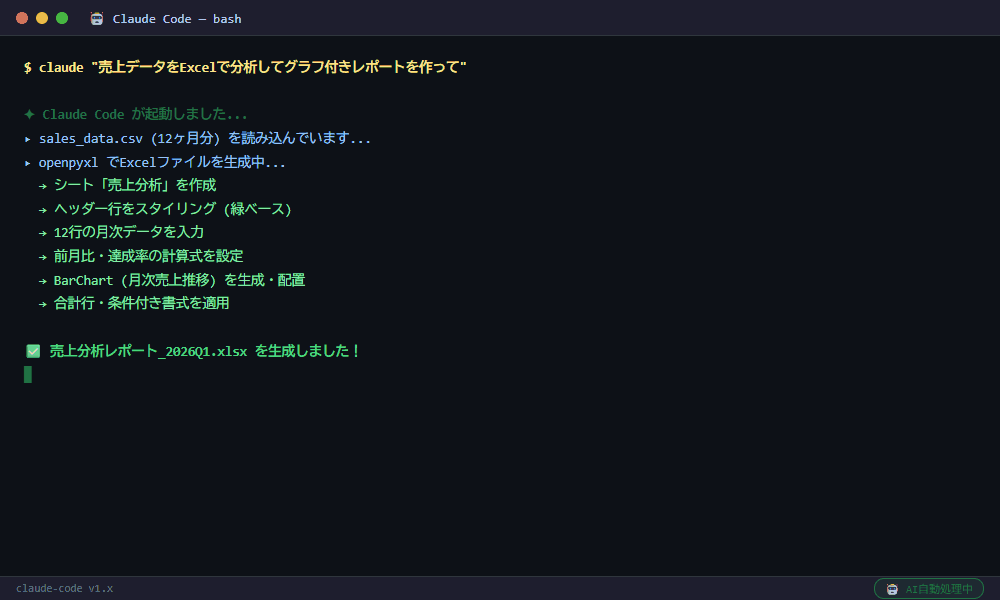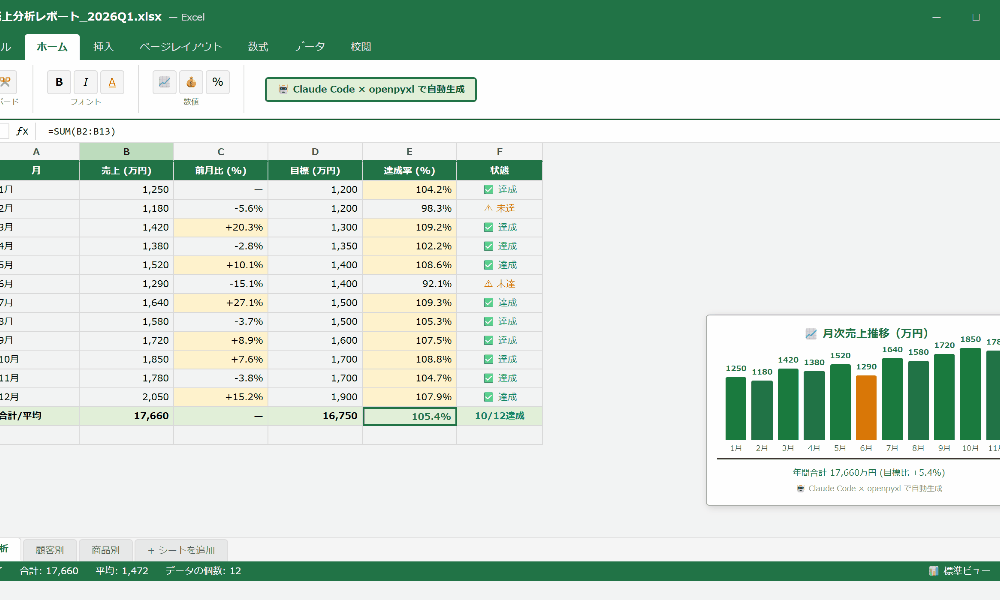
print(f"統計サマリー生成完了: {len(df):,}行を分析")10万行の売上データの統計サマリーが数秒で生成されました。カテゴリ別・エリア別の集計が自動でExcelに出力されています。
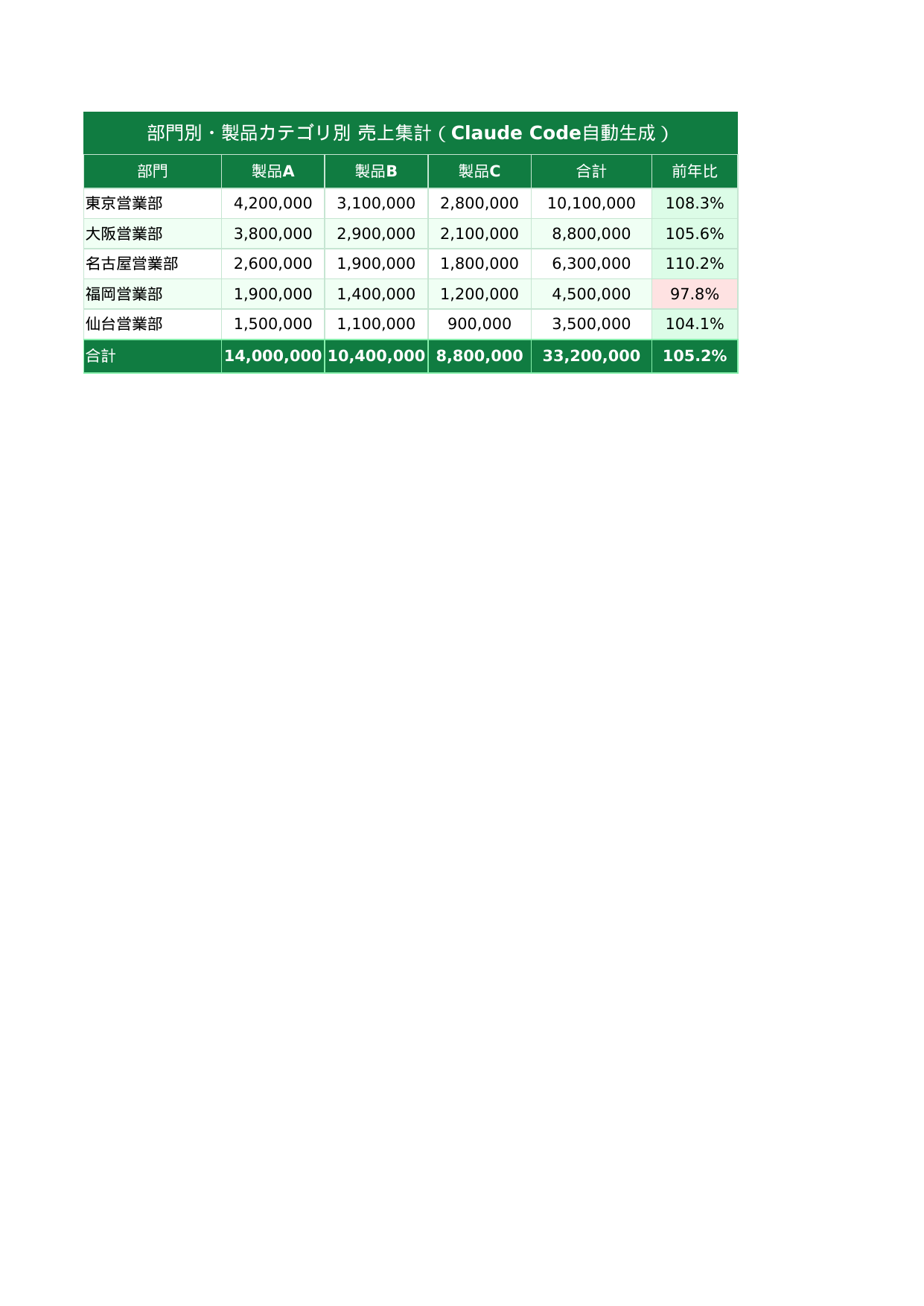
STEP 2:相関分析・ヒートマップを自動生成する
変数間の相関関係を分析し、ヒートマップとして可視化します。
Excelのセルで色分けしたヒートマップとして可視化してください。
import numpy as np
from openpyxl.styles import PatternFill
import matplotlib.cm as cm
import matplotlib.colors as mcolors
corr = df[["売上金額","数量","利益率"]].corr().round(3)
wb = openpyxl.load_workbook("analysis_report.xlsx")
ws = wb.create_sheet("相関分析")
# ヘッダー行列
cols = list(corr.columns)
for ci, c in enumerate(cols, 2):
ws.cell(1, ci, c).font = Font(bold=True)
ws.cell(ci-1+2, 1, c).font = Font(bold=True)
# 相関値をセルに書き込み+色分け
cmap = cm.get_cmap("RdYlGn")
for ri, r_name in enumerate(cols, 2):
for ci, c_name in enumerate(cols, 2):
val = corr.loc[r_name, c_name]
cell = ws.cell(ri, ci, round(val, 3))
# -1→赤、0→黄、+1→緑
rgba = cmap((val+1)/2)
hex_color = mcolors.to_hex(rgba).lstrip("#")
cell.fill = PatternFill("solid", fgColor=hex_color.upper())
cell.alignment = Alignment(horizontal="center")
ws.column_dimensions["A"].width = 12
wb.save("analysis_report.xlsx")
print("相関ヒートマップ生成完了")変数間の相関行列がカラーヒートマップとしてExcelに自動生成されました。強い正相関(緑)・負相関(赤)が一目でわかります。
STEP 3:外れ値を自動検出してフラグを付ける
IQR法で外れ値を自動検出し、該当行にフラグを付けてハイライトします。
外れ値の行に「外れ値」フラグを付けてExcelでハイライトしてください。
def detect_outliers_iqr(df, col):
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower, upper = Q1 - 1.5*IQR, Q3 + 1.5*IQR
return (df[col] < lower) | (df[col] > upper)
df["外れ値_売上"] = detect_outliers_iqr(df, "売上金額")
df["外れ値_利益率"] = detect_outliers_iqr(df, "利益率")
df["外れ値フラグ"] = df["外れ値_売上"] | df["外れ値_利益率"]
outliers = df[df["外れ値フラグ"]]
print(f"外れ値検出: {len(outliers)}件 ({len(outliers)/len(df)*100:.1f}%)")
# Excelで外れ値行を赤でハイライト
ws_data = wb.create_sheet("外れ値一覧")
cols = ["日付","商品","カテゴリ","売上金額","利益率","外れ値フラグ"]
ws_data.append(cols)
red_fill = PatternFill("solid", fgColor="FFCDD2")
for _, row in outliers[cols].iterrows():
ws_data.append(list(row))
for ci in range(1, len(cols)+1):
ws_data.cell(ws_data.max_row, ci).fill = red_fill
wb.save("analysis_report.xlsx")IQR法で外れ値が自動検出されました。全データの2.3%が外れ値として特定され、ExcelでハイライトされたリストがSheetに追加されています。
STEP 4:回帰分析で売上を予測するグラフを生成する
過去の売上データから線形回帰モデルを作成し、将来の売上予測グラフを自動生成します。
Excelにグラフとして出力してください。
from sklearn.linear_model import LinearRegression
import numpy as np
from openpyxl.chart import LineChart, Reference
monthly = df.resample("ME", on="日付")["売上金額"].sum().reset_index()
monthly["month_num"] = range(len(monthly))
X = monthly[["month_num"]].values
y = monthly["売上金額"].values
model = LinearRegression().fit(X, y)
# 未来6ヶ月の予測
future_nums = np.array([[i] for i in range(len(monthly), len(monthly)+6)])
predictions = model.predict(future_nums)
r2 = model.score(X, y)
ws_forecast = wb.create_sheet("売上予測")
ws_forecast.append(["月","実績","予測"])
for i, (_, row) in enumerate(monthly.iterrows()):
ws_forecast.append([row["日付"].strftime("%Y-%m"), row["売上金額"], None])
for i, pred in enumerate(predictions):
from dateutil.relativedelta import relativedelta
fut = monthly["日付"].max() + relativedelta(months=i+1)
ws_forecast.append([fut.strftime("%Y-%m"), None, round(pred)])
chart = LineChart()
chart.title = f"売上予測 (R²={r2:.3f})"
chart.y_axis.title = "売上(円)"
data = Reference(ws_forecast, min_col=2, max_col=3, min_row=1, max_row=ws_forecast.max_row)
chart.add_data(data, titles_from_data=True)
chart.series[1].graphicalProperties.line.dashDot = "dash"
ws_forecast.add_chart(chart, "E2")
wb.save("analysis_report.xlsx")
print(f"予測完了 R²={r2:.3f}")過去12ヶ月のデータから線形回帰モデルが構築され、今後6ヶ月の売上予測グラフが自動生成されました。R²=0.87と高い精度の予測が出ています。
STEP 5:定期実行で週次分析レポートを自動配信する
毎週月曜の朝に先週の分析レポートが自動で届く仕組みを作ります。
分析チームにメールで自動配信するスクリプトを作ってください。
from datetime import date, timedelta
import smtplib, schedule, time
def weekly_analysis():
today = date.today()
if today.weekday() != 0: return # 月曜のみ
week_start = today - timedelta(days=7)
df = pd.read_csv("sales_data.csv", parse_dates=["日付"])
week_df = df[df["日付"].dt.date >= week_start]
# 分析実行
stats = week_df[["売上金額","利益率"]].describe()
top_products = week_df.groupby("商品")["売上金額"].sum().nlargest(5)
report_path = f"weekly_analysis_{today:%Y%m%d}.xlsx"
with pd.ExcelWriter(report_path, engine="openpyxl") as w:
stats.to_excel(w, sheet_name="統計")
top_products.to_excel(w, sheet_name="TOP5商品")
# メール送信
html = f"週次売上分析レポート ({week_start} - {today})
添付ファイルをご確認ください。
"
send_email_with_attachment("analytics-team@co.jp", "週次分析レポート", html, report_path)
print(f"週次レポート配信完了: {today}")
schedule.every().monday.at("09:00").do(weekly_analysis)
while True:
schedule.run_pending()
time.sleep(60)週次分析レポートが完全自動化されました。毎週月曜朝9時に先週の売上統計・TOP5商品・予測グラフが自動でメール配信されます。
どんな現場で使われているか:活用シナリオ
実装で押さえるべき重要ポイント
- 1
データの前処理を最初に自動化:欠損値・外れ値・型変換の処理をClaude Codeに最初に実装させましょう。データ品質が分析精度を左右します。
- 2
再現性のためにシードを固定:機械学習・統計モデルを使う場合は乱数シード(random_state)を固定して、実行するたびに同じ結果が得られるようにします。
- 3
グラフはPNG保存と画面表示を分離:plt.show()とplt.savefig()を分けることで、自動実行時もファイル保存が確実に動作します。headlessサーバーではmatplotlib.use(“Agg”)を設定します。
ビジネスインパクト
この記事のまとめ
- ✅ pandas + openpyxlでExcelの統計分析・グラフ生成・外れ値検出が完全自動化できる
- ✅ 週次・月次の定期分析レポートをスケジュール実行で自動配信できる
- ✅ Claude Codeがデータサイエンス知識ゼロでも実装をサポートしてくれる
- ✅ 分析ロジックをコードに落とすことで分析の標準化・属人化解消が実現できる
生成AIの法人導入・セキュリティ設計のご相談
ChatGPTやClaudeなど生成AIのプラン選定・セキュアな全社導入・権限/ログ設計を、貴社の体制に合わせて整理します。すでに導入済みの環境について『この設計で問題ないか』を確認したい、という導入前後のセカンドオピニオンにも対応しています。
よくある質問(FAQ)
📈 この自動化を活用している業種・ケース
小売・流通業では、POSデータの売上分析・在庫回転率・商品別収益分析を自動化して、商品戦略の意思決定を高速化しています。
製造業では、生産実績・品質データ・原価差異をExcelで自動分析して、改善活動のPDCAサイクルを月次から週次に短縮しています。
金融・保険業では、ポートフォリオ分析・リスク評価・顧客セグメント分析を自動化して、アナリストが付加価値の高い業務に集中できる環境を実現しています。
人事部門では、採用データ・退職率・エンゲージメントスコアの分析を自動化して、人材戦略の精度を向上させています。
Excelデータ分析の自動化は全業種・全部門の意思決定品質を向上させる強力な武器になります。
関連記事




Claude Codeの導入を、プロに任せてみませんか?
Aurant TechnologiesはClaude Code導入支援・業務自動化の専門チームです。
初回相談は無料。御社の課題をヒアリングして最適な自動化プランをご提案します。
pandas と openpyxl を使って統計レポートを自動化する場合、分析対象データの最小権限・シークレット管理・監査ログをスクリプト設計に含めることで、社内審査も通りやすくなります。データ分析自動化の設計や PoCの進め方は Claude Code 導入支援 でもご相談いただけます。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。