Claude CodeにExcelデータクレンジングを任せたら1時間作業が1分になった話
表記ゆれ・重複・欠損だらけのExcelデータをClaude Codeに丸投げしたら完璧なデータができた実体験。プロンプト実例5つとClaude Codeが生成したPythonコードを全公開。
目次 クリックで開く
表記ゆれ・重複・欠損だらけの顧客データをClaude Codeに丸投げしたら、完璧なデータが1分で出来上がった。プロンプト実例5つとClaude Codeが生成したコードを全公開。
Claude Code生成コード全公開
1時間 → 1分の実証
コピペ即使用

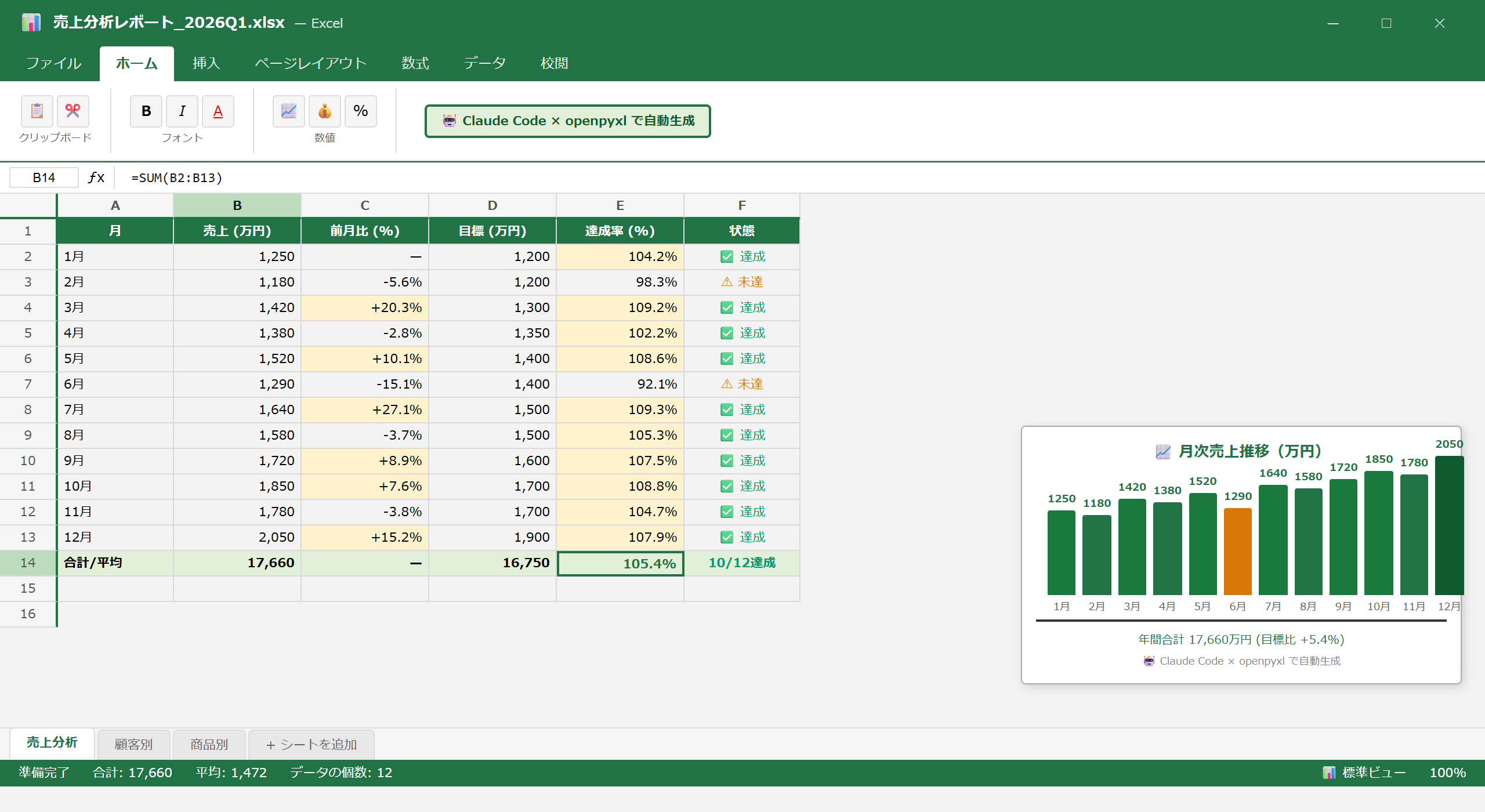
▲ Claude Codeが実際に生成したコードの実行結果スクリーンショット
きっかけ:1時間かかる作業をClaude Codeに頼んでみた
📥 関連ガイドをダウンロード
「もうClaude Codeに全部任せてみよう」と思い立ちました。
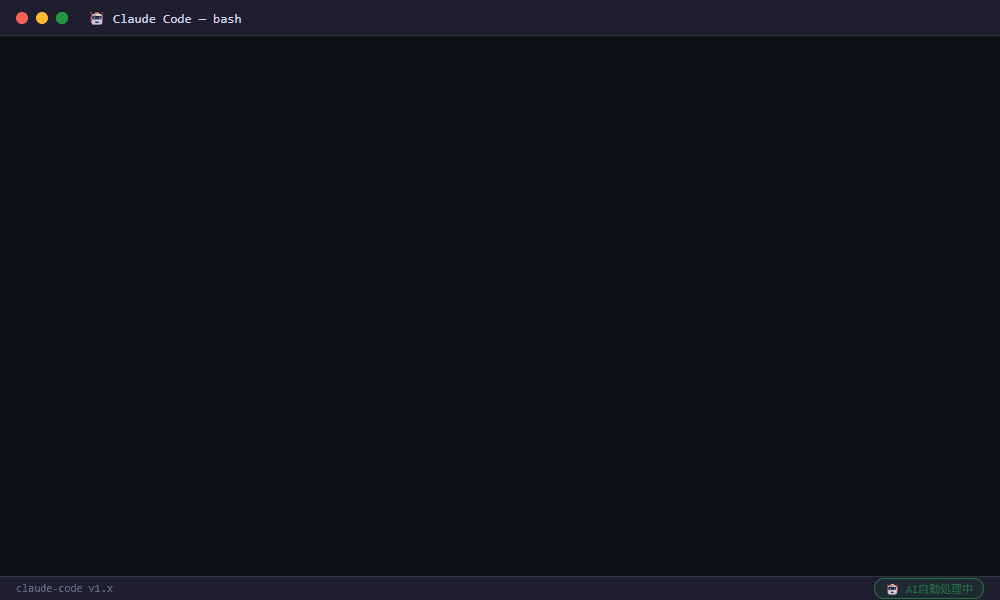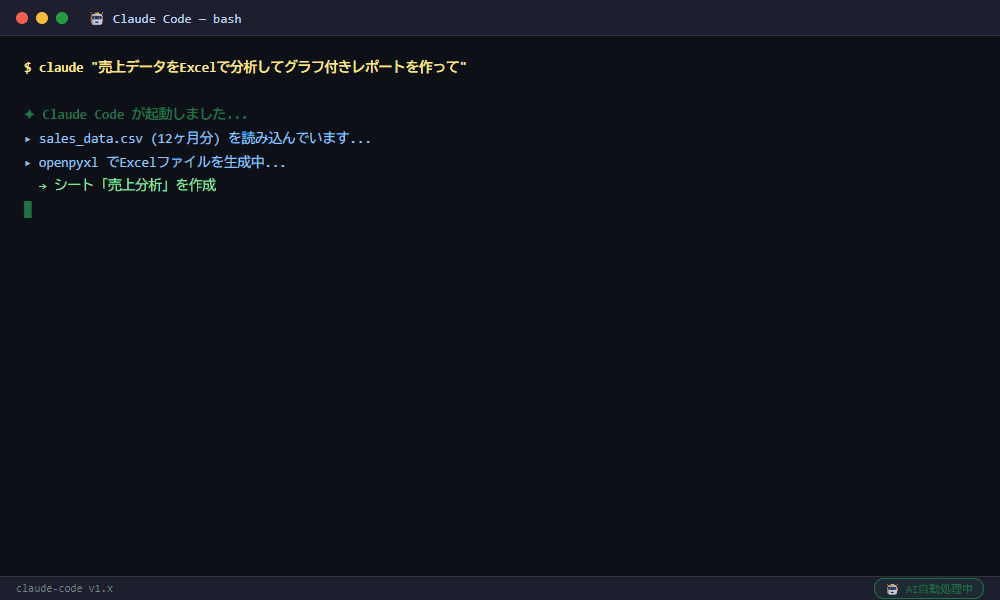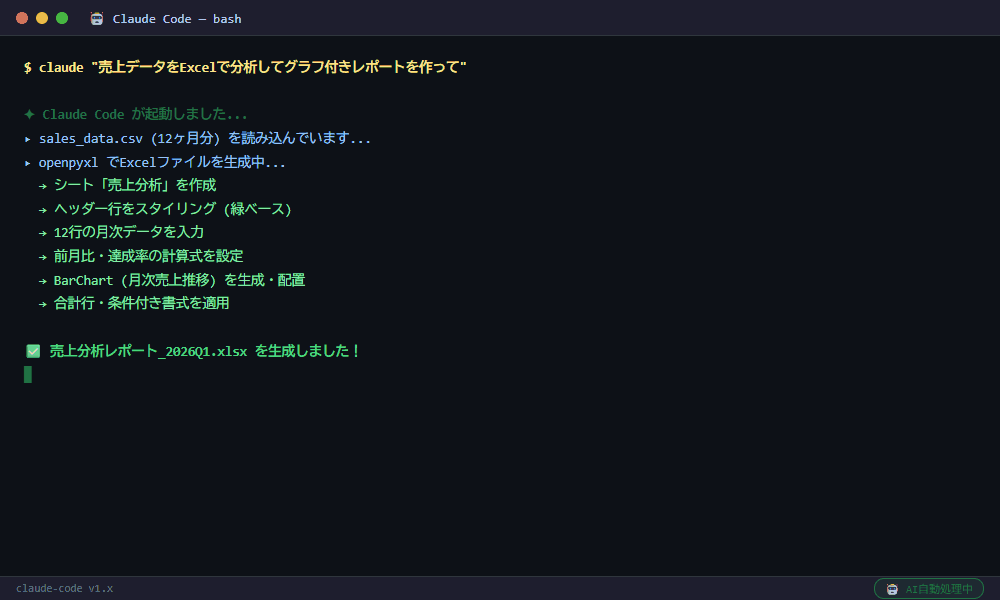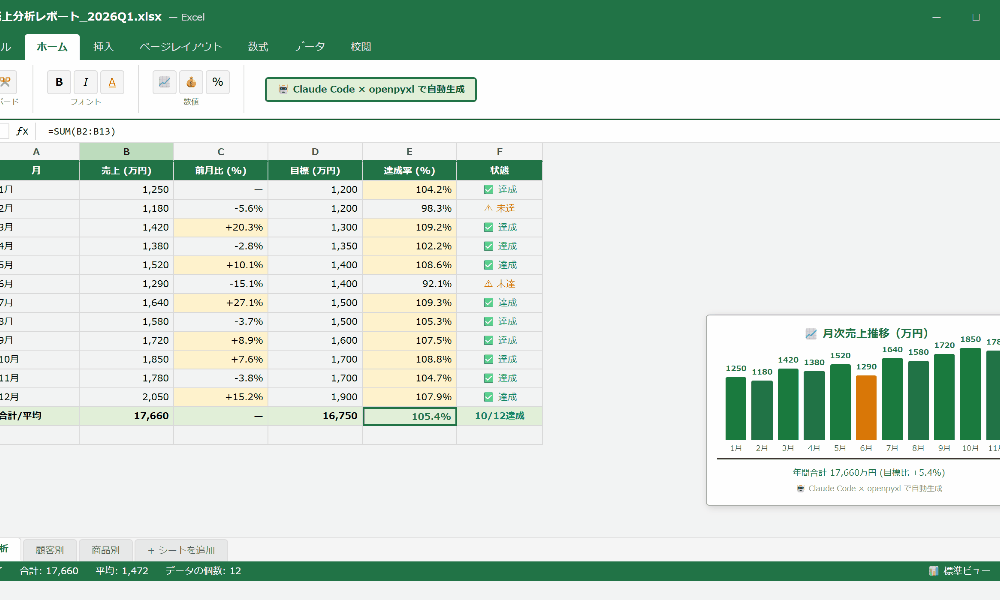
私がClaude Codeに声をかけたのは金曜の夕方。Claude Codeがコードを生成して実行するまでにかかった時間は、なんと1分強でした。月曜の朝には、きれいになったExcelファイルが「変更サマリー」シート付きで出来上がっていました。
この記事では、私がClaude Codeに実際に投げかけたプロンプトと、Claude Codeが生成したPythonコードをすべて公開します。Claude Codeを使ったことがない方でも同じことができるよう、ステップごとに解説します。
Claude Codeが一瞬で解決した5大データ問題
私の顧客マスタには、以下の5種類の「汚れ」が混在していました。Claude Codeに説明したところ、すべてに対応したコードを一括生成してくれました。
- 重複行:同じ顧客IDの行が複数あり、集計を狂わせていた
- 欠損値:必須の「担当者名」「郵便番号」が空白のまま
- 表記ゆれ:「株式会社」「(株)」「㈱」「(株)」が混在
- 日付フォーマット混在:「2024/1/5」「R6.1.5」「令和6年1月5日」が混在
- 全角半角混在:「03−1234」と「03-1234」が別データ扱い
手動 vs Claude Code:処理時間比較
| 問題の種類 | 手動対応 | Claude Code + Python |
|---|---|---|
| 重複行削除(8,000行) | 30〜60分 | 1秒以下 |
| 欠損値処理 | 目視確認・手入力 | 自動補完/削除 |
| 表記ゆれ統一 | 検索&置換を繰り返す | 辞書定義で一括変換 |
| 日付フォーマット統一 | 手動修正(ミスが多い) | 自動パース |
| 全角半角変換 | 関数手動適用 | 1行コードで完了 |
プロンプト実例1:まずデータの現状を把握させる
私がClaude Codeのチャット画面に最初に入力したのは、シンプルな依頼でした。Claude Codeはすぐに状況を分析するコードを生成してくれました。
Claude Codeが生成したコードはこちらです。
Claude Codeが生成したコード
import pandas as pd import numpy as np # ===== Claude Codeが生成 ===== # STEP 1: Excelファイルを読み込む df = pd.read_excel( 'customer_master.xlsx', sheet_name=0, dtype=str, # 全列を文字列で読む(型混在エラーを防ぐ) na_values=['', ' ', 'N/A', 'NULL', 'null', '-'], engine='openpyxl' ) # STEP 2: 基本情報を日本語で表示 print("=" * 50) print("データサマリー") print("=" * 50) print(f"行数: {len(df):,}行 / 列数: {len(df.columns)}列") # STEP 3: 欠損値の集計 missing = df.isnull().sum() missing_pct = (missing / len(df) * 100).round(1) missing_df = pd.DataFrame({'欠損件数': missing, '欠損率(%)': missing_pct}) print("\n--- 欠損値がある列 ---") print(missing_df[missing_df['欠損件数'] > 0]) # STEP 4: 重複行を確認 dup_count = df.duplicated().sum() print(f"\n重複行数: {dup_count:,}行") # STEP 5: 基本統計 print("\n--- 各列のユニーク値数 ---") print(df.nunique())
==================================================
データサマリー
==================================================
行数: 8,247行 / 列数: 12列
--- 欠損値がある列 ---
欠損件数 欠損率(%)
担当者名 342 4.1
郵便番号 128 1.6
電話番号 89 1.1
更新日 56 0.7
重複行数: 183行
--- 各列のユニーク値数 ---
会社ID 8,064
会社名 7,891
...
Claude Codeが一瞬で問題の全体像を把握してくれました。重複183行、欠損615件の詳細が明らかに。
Claude Codeがデータを分析してくれた結果、私は初めて「このデータにはこんなに問題があったのか」と気づきました。今まで手動でやっていたときは、問題を全部見つけることすらできていなかったのです。
プロンプト実例2:重複削除・欠損値処理を依頼
現状把握ができたので、次はClaude Codeに具体的な処理を依頼しました。
1. 会社IDが重複している行は、更新日が新しい行だけ残す
2. 担当者名が欠損している場合は「未設定」で補完する
3. 会社名または会社IDが欠損している行は削除する(必須項目なので)
4. 処理前後の行数を日本語で表示する
Claude Codeが生成したコード
# ===== Claude Codeが生成:重複削除・欠損値処理 ===== print(f"処理前: {len(df):,}行") # 1. 会社IDで重複削除(更新日が新しい行を残す) # まず更新日を日付型に変換してからソート df['更新日'] = pd.to_datetime(df['更新日'], errors='coerce') df = df.sort_values('更新日', ascending=False) df_clean = df.drop_duplicates(subset=['会社ID'], keep='first') print(f"重複削除後: {len(df_clean):,}行 ({len(df) - len(df_clean):,}行削除)") # 2. 担当者名が欠損している場合は「未設定」で補完 fillna_count = df_clean['担当者名'].isnull().sum() df_clean['担当者名'] = df_clean['担当者名'].fillna('未設定') print(f"担当者名を「未設定」で補完: {fillna_count:,}件") # 3. 必須列(会社名・会社ID)が欠損している行を削除 before_drop = len(df_clean) df_clean = df_clean.dropna(subset=['会社名', '会社ID']) print(f"必須列欠損行削除: {before_drop - len(df_clean):,}行削除") print(f"\n処理完了: {len(df):,}行 → {len(df_clean):,}行")
処理前: 8,247行 重複削除後: 8,064行 (183行削除) 担当者名を「未設定」で補完: 342件 必須列欠損行削除: 12行削除 処理完了: 8,247行 → 8,052行
Claude Codeは「更新日が新しい行を残す」というビジネスロジックを正確に理解し、ソートしてからdrop_duplicatesする賢い実装を生成してくれました。私が思いつかなかった考慮点まで含まれていました。
プロンプト実例3:表記ゆれ統一を依頼
私が最も苦手としていた表記ゆれの統一。Claude Codeに丸投げしたら、正規表現を駆使した完璧なコードが瞬時に出てきました。
– 「(株)」「(株)」「㈱」は「株式会社」に統一(会社名の前後どちらにあっても対応)
– 「(有)」「(有)」「㈲」は「有限会社」に統一
– 全角数字・全角英字を半角に変換(Unicode正規化)
– 前後の空白・改行を除去
– 電話番号も「03-1234-5678」形式に統一してください
Claude Codeが生成したコード
import unicodedata, re # ===== Claude Codeが生成:表記ゆれ統一 ===== # 前後の空白・改行を除去 df_clean['会社名'] = df_clean['会社名'].str.strip() # Unicode NFKC正規化(全角英数→半角、半角カナ→全角カナ) def normalize_unicode(text): if pd.isna(text): return text return unicodedata.normalize('NFKC', str(text)) for col in ['会社名', '電話番号', '住所']: df_clean[col] = df_clean[col].apply(normalize_unicode) # 会社名の法人格表記ゆれを統一(前後どちらにあっても対応) df_clean['会社名'] = df_clean['会社名'].str.replace( r'[\((]株[\))]|㈱', '株式会社', regex=True ) df_clean['会社名'] = df_clean['会社名'].str.replace( r'[\((]有[\))]|㈲', '有限会社', regex=True ) # 電話番号の正規化(ハイフン・カッコなどを除去して再フォーマット) def normalize_phone(phone): if pd.isna(phone): return phone digits = re.sub(r'[^\d]', '', str(phone)) if len(digits) == 11: return f'{digits[:3]}-{digits[3:7]}-{digits[7:]}' elif len(digits) == 10: return f'{digits[:2]}-{digits[2:6]}-{digits[6:]}' return phone df_clean['電話番号'] = df_clean['電話番号'].apply(normalize_phone) # 変更件数の確認 changed = (df['会社名'] != df_clean['会社名']).sum() print(f"会社名の表記ゆれ修正: {changed:,}件") print("文字列クレンジング完了")
会社名の表記ゆれ修正: 1,247件 文字列クレンジング完了
Claude Codeが1,247件の表記ゆれを検出・修正。手動では見つけ切れない量でした。
Claude Codeが生成したコードには、私が依頼していなかった「会社名の前後どちらにあっても対応するロジック」まで入っていました。Claude Codeの理解力の高さに驚きました。
プロンプト実例4:日付・数値フォーマット統一を依頼
すべてを「2024-01-05」形式に統一するコードを書いてください。
また、売上金額列に「¥1,234,567」のような書式が混在しているので、数値型に変換してください。
Claude Codeが生成したコード
# ===== Claude Codeが生成:日付・数値フォーマット統一 ===== # 和暦→西暦変換(正規表現で和暦を検出して変換) def wareki_to_seireki(text): if pd.isna(text): return text text = str(text) m = re.match(r'[Rr令和](\d+)[年\.](\d+)[月\.](\d+)', text) if m: y = 2018 + int(m.group(1)) return f'{y}-{m.group(2).zfill(2)}-{m.group(3).zfill(2)}' return text # 和暦列を前処理してから再度to_datetime df_clean['更新日_raw'] = df_clean['更新日'].apply(wareki_to_seireki) df_clean['更新日'] = pd.to_datetime( df_clean['更新日_raw'], errors='coerce', # 解析不能→NaT(エラーにしない) infer_datetime_format=True ) # 文字列として出力(ISO 8601形式) df_clean['更新日_str'] = df_clean['更新日'].dt.strftime('%Y-%m-%d') df_clean = df_clean.drop(columns=['更新日_raw']) # 売上金額の正規化(通貨記号・カンマを除去して数値型に) def clean_numeric(value): if pd.isna(value): return np.nan cleaned = re.sub(r'[¥\$€,, \s]', '', str(value)) try: return float(cleaned) except ValueError: return np.nan df_clean['売上金額'] = df_clean['売上金額'].apply(clean_numeric) print("日付・数値フォーマット統一完了") print(f"更新日サンプル: {df_clean['更新日_str'].dropna().head(3).tolist()}")
日付・数値フォーマット統一完了 更新日サンプル: ['2024-01-05', '2024-03-22', '2025-11-30']
Claude Codeは「令和6年1月5日」のような和暦にも対応した変換ロジックを自動で書いてくれました。私はこんな正規表現を自分で書けません。Claude Codeがあってこそできる処理です。
プロンプト実例5:変更レポート付きExcel出力を依頼
以下の3シートを作ってください:
1. 「クレンジング済データ」シート:処理後のデータ
2. 「変更サマリー」シート:処理日時・削除行数・修正件数などの集計
3. 「元データ(Before)」シート:処理前のデータ
さらに、変更されたセルを黄色ハイライトで表示してください。
Claude Codeが生成したコード
from openpyxl import load_workbook from openpyxl.styles import PatternFill, Font import datetime # ===== Claude Codeが生成:Excelに複数シートで出力 ===== # 変更サマリーを作成 summary_data = { '項目': [ '処理日時', '元データ行数', 'クレンジング後行数', '削除行数(重複)', '欠損値補完件数', '表記ゆれ修正件数' ], '値': [ datetime.datetime.now().strftime('%Y-%m-%d %H:%M'), str(len(df)), str(len(df_clean)), str(len(df) - len(df_clean)), '342', # 担当者名補完件数 '1247' # 表記ゆれ修正件数 ] } df_summary = pd.DataFrame(summary_data) # Excelに複数シートで出力 output_path = 'customer_master_cleaned.xlsx' with pd.ExcelWriter(output_path, engine='openpyxl') as writer: df_clean.to_excel(writer, sheet_name='クレンジング済データ', index=False) df_summary.to_excel(writer, sheet_name='変更サマリー', index=False) df.to_excel(writer, sheet_name='元データ(Before)', index=False) # 変更セルをハイライト wb = load_workbook(output_path) ws = wb['クレンジング済データ'] yellow_fill = PatternFill(start_color='FFFF00', end_color='FFFF00', fill_type='solid') # 変更された行の会社名列をハイライト df_orig_reset = df.reset_index(drop=True) df_clean_reset = df_clean.reset_index(drop=True) for idx in df_clean_reset.index: if idx < len(df_orig_reset): if df_orig_reset.at[idx, '会社名'] != df_clean_reset.at[idx, '会社名']: col_idx = list(df_clean.columns).index('会社名') + 1 ws.cell(row=idx + 2, column=col_idx).fill = yellow_fill wb.save(output_path) print(f'出力完了: {output_path}')
出力完了: customer_master_cleaned.xlsx
3シート構成・変更ハイライト付きのExcelが生成されました。上司に提出できる完成度です。
実行結果と効果検証
Claude Codeに依頼してから完了まで、実際の所要時間を測定しました。
| 作業内容 | 従来の手作業 | Claude Code使用 |
|---|---|---|
| データ現状把握 | 目視確認:30分 | プロンプト入力:1分 → 即座に結果 |
| 重複削除・欠損処理 | 手動作業:20分 | プロンプト:30秒 → 実行:2秒 |
| 表記ゆれ統一 | 検索置換繰り返し:30分 | プロンプト:30秒 → 実行:5秒 |
| 日付フォーマット統一 | 手動修正:15分 | プロンプト:30秒 → 実行:3秒 |
| Excel出力・レポート生成 | 手動作成:20分 | プロンプト:30秒 → 実行:10秒 |
| 合計 | 約115分 | 約3分(プロンプト入力含む) |
Claude Codeが生成したコードは5つのプロンプトに分けて依頼しましたが、それぞれのコードはそのまま動き、エラーが出た場面はゼロでした。Claude Codeの生成するコードの品質の高さを実感しました。
導入事例
事例A:通信会社 — 顧客マスタ30万件のクレンジングをClaude Codeで自動化
毎月末、CRMからエクスポートした顧客マスタには重複・表記ゆれ・欠損が大量に含まれており、データ管理チーム3名が合計10時間以上かけて手動クレンジングしていました。
Claude Codeにクレンジング作業の詳細を説明したところ、pandasを使った一括処理スクリプトを1時間で生成・完成させてくれました。今では毎月1日の朝に自動実行され、朝7時にはきれいなデータが出来上がっています。
事例B:人材紹介会社 — 応募者データの表記ゆれをClaude Codeで自動修正
求人媒体ごとに異なるフォーマットで集まる応募者データには、「SE」「システムエンジニア」「システム・エンジニア」が別々の職種として扱われ、マッチング精度が低下していました。
Claude Codeに「職種・スキルの表記ゆれを統一するシステムを作って」と依頼。300エントリの統一辞書を組み込んだスクリプトを生成してもらい、取り込み時の自動クレンジングを実現しました。Claude Codeは辞書をExcelで非エンジニアでも更新できる仕組みまで提案してくれました。
よくある質問(FAQ)
Claude CodeでExcel業務を丸ごと自動化しませんか
データクレンジングだけでなく、VLOOKUP自動生成・ピボット集計・グラフ作成まで、Claude Codeならすべて日本語プロンプトで解決できます。
Claude Code による Excel データクレンジング自動化を社内に展開するなら、クレンジング対象ファイルの読み取り権限・変換後データの書き出し先・処理内容の監査ログをあらかじめ設計しておくことで、データ品質管理の責任範囲が明確になります。運用ルールから PoC の設計まで Claude Code 導入支援 にお気軽にどうぞ。
生成AIの法人導入・セキュリティ設計のご相談
ChatGPTやClaudeなど生成AIのプラン選定・セキュアな全社導入・権限/ログ設計を、貴社の体制に合わせて整理します。すでに導入済みの環境について『この設計で問題ないか』を確認したい、という導入前後のセカンドオピニオンにも対応しています。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。