BigQuery 動的セグメント基盤 構築ガイド 2026:4ステップで「更新され続けるセグメント」自動配布
常に最新の顧客セグメントを現場へ!BigQueryで動的セグメントを自動生成し、マーケティング・営業活動を劇的に変革。データに基づいた顧客理解で、成果を最大化する実践手法を解説します。
目次 クリックで開く
顧客セグメント運用を劇的に変革!BigQueryで「更新され続けるセグメント」を自動生成し、現場へ配布する実践ガイド
100件超のBI研修と50件超のCRM導入支援から見えた、現場が本当に動くデータ活用の正解。静的なリストを捨て、動的な「攻めのデータ基盤」を構築する手法を詳説します。
はじめに:なぜあなたの企業の「顧客セグメント」は機能していないのか
多くのB2B企業で「顧客セグメント」という言葉が形骸化しています。マーケティング部門が四半期に一度作成するExcelの抽出リスト、あるいはMAツール(マーケティングオートメーション)の中に眠る古い条件設定……。これらは作成された瞬間から陳腐化が始まり、現場の営業担当者が手にする頃には「既に商談が終わっている」「状況が変わっている」という事態が常態化しています。
私はこれまで、100社を超えるBI(ビジネスインテリジェンス)研修や50件以上のCRM導入プロジェクトに携わってきましたが、成果を出している企業に共通しているのは、「セグメントは静的なものではなく、常に更新され続ける動的なもの」という認識です。
本ガイドでは、Google Cloudのデータウェアハウスである「BigQuery」を核に、最新のデータスタックを用いて、現場が迷わず動ける「究極の顧客セグメント運用」を構築する具体的なステップを解説します。
多くの企業で陥る落とし穴は、「条件が複雑すぎて誰も理解できないセグメント」を作ってしまうことです。データサイエンティストが高度な統計モデルで抽出した「購入可能性80%以上のリスト」であっても、その理由(根拠となる行動)が営業に伝わらなければ、現場は動きません。セグメントには「更新頻度」と同じくらい「解釈性(なぜその顧客が選ばれたか)」が重要です。
—
1. 従来のセグメント運用が抱える3つの「限界」
① 手動更新によるタイムラグ(鮮度の欠如)
CRMからデータをCSVで吐き出し、ExcelでVLOOKUPを駆使して成形する。この作業に月数日を費やしている企業は少なくありません。しかし、現代の顧客行動は驚くほど速いです。昨日自社サイトの料金ページを5回見た顧客を、来月の月次リストで追いかけても手遅れなのです。
② ツール間のデータ分断(サイロ化)
「Webでの行動はGA4にあるが、商談履歴はSalesforce、過去の購入履歴は基幹システムにある」という状態では、多角的なセグメントは作れません。MAツール単体でセグメントを作ろうとしても、基幹システムの「入金遅延情報」や「返品履歴」を考慮できず、不適切なアプローチをしてしまうリスクがあります。
③ セグメントの「粒度」が粗すぎる
「製造業・従業員100名以上」といった属性情報だけのセグメントは、もはや意味をなしません。現場が求めているのは、「過去にA製品を購入し、かつ最近B製品の導入事例を3回読み、直近のウェビナーに参加しなかったがアンケートには回答した」といった、行動に基づくマイクロセグメントです。
—
2. BigQueryによる「動的セグメント基盤」のアーキテクチャ
この課題を解決するのが、モダンデータスタック(MDS)を活用したアーキテクチャです。中心にBigQueryを据え、あらゆるデータを統合。そして「リバースETL」という手法で、分析結果を現場のツール(Salesforce、Slack、LINEなど)へ押し戻します。
高額なCDPを導入せずとも、既存の資産を活用して「動的セグメント」を実現する具体的な設計図は、こちらの記事で詳しく解説しています。
高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」
主要ツールの比較と選定
動的セグメントを構築するために必須となる、国内外の主要ツールを紹介します。
| ツール名 | 役割 | 特徴 | コスト感(目安) |
|---|---|---|---|
| Google BigQuery | データウェアハウス(DWH) | 圧倒的な高速処理。Google広告やGA4との連携が最強。 | 従量課金。初期費用0円、月額数千円〜(データ量による) |
| Census / Hightouch | リバースETL | BigQueryのデータをSalesforceやHubSpotへ同期。 | 月額$500〜(一部無料枠あり) |
| trocco | ETL/ELT(データ統合) | 日本発のツール。国内SaaS(楽楽精算、KING OF TIME等)との連携に強い。 | 初期費用+月額10万円〜 |
—
3. 実践:更新され続けるセグメントを作る4ステップ
ステップ1:データの集約とクリーニング(名寄せ)
まず、troccoやFivetranを使い、Salesforce、GA4、基幹システム(DB)のデータをBigQueryにロードします。ここで最大の難関となるのが「名寄せ」です。メールアドレスをキーにするのが定石ですが、B2Bの場合は「会社名」の表記ゆれ((株)と株式会社など)の補正が必要になります。
ステップ2:SQLによるセグメントロジックの記述
BigQuery上で、SQLを用いてセグメントを定義します。
例えば「ホットリード・セグメント」を以下のように定義します。
- 直近7日間にWebサイトを3回以上訪問
- かつ、製品紹介PDFをダウンロード済み
- かつ、現在「失注」以外の商談が動いていない
これをビュー(View)として保存しておくことで、データが更新されるたびにリストが自動で再計算されます。
単純な「累計購入金額」でセグメントを作ると、5年以上前の休眠顧客が「優良顧客」として上位に来てしまいます。B2Bでは「直近12ヶ月の取引額」や「アクティブユーザー率」を重く見た加重スコアリングをSQLに組み込むのが鉄則です。
ステップ3:リバースETLによる「現場ツール」への配送
BigQueryで生成された最新のセグメント情報を、CensusなどのリバースETLツールを使い、Salesforceの「リード客属性」や「取引先責任者タグ」へ1時間おきに同期します。
ステップ4:Slackによる「即時通知」の設定
特定の超重要セグメント(例:競合サービスからの乗り換えを検討していそうな動きを見せた既存顧客)に変化があった場合、担当営業のSlackに直接通知が飛ぶように設計します。
高額なMAツール(MarketoやPardot)に頼りすぎず、データ基盤側でロジックを持つ「コンポーザブルCDP」の考え方が、今のトレンドです。詳細は以下のガイドをご参照ください。
高額MAツールは不要。BigQueryとリバースETLで構築する「行動トリガー型配信」
—
4. 具体的な導入事例:製造業A社のケース
【課題】
数千社の顧客リストがあるが、営業担当者が「今日、どこに電話すべきか」を勘に頼って判断しており、成約率が低迷。
【解決策】
BigQueryを導入し、GA4のWeb行動ログとSalesforceの商談履歴を統合。以下の3つの動的セグメントを構築。
- 検討再燃セグメント:過去に失注したが、直近3日以内に導入事例ページを閲覧した企業。
- アップセル予備軍:特定パーツを購入済みで、かつ上位機種のスペック表をダウンロードした企業。
- 解約リスク警報:サポートへの問い合わせが急増し、かつ製品管理画面へのログイン頻度が低下した企業。
【成果URL(出典元)】
Google Cloud公式事例(製造業でのデータ活用):いすゞ自動車のデータ基盤構築事例
【結果】
営業の架電から商談化する率が3.5倍に向上。解約率(チャーンレート)は前年比15%削減。
—
5. 導入コストとプロジェクトの進め方
動的セグメント基盤の構築には、ツール費用と構築コンサル費用の両面を見る必要があります。
コスト目安
- 初期費用:300万円〜800万円(データソース数やクレンジングの難易度に依存)
- 月額ツール費用:15万円〜50万円(BigQuery, trocco, Census等の合計)
- 保守・運用支援:月額20万円〜
最初から全データを統合しようとすると、100%挫折します。まずは「GA4(Web行動)」と「CRM(顧客基本情報)」の2つだけに絞ってセグメントを1つ作り、現場の営業に「このリスト、役に立つね」と言わせること。そこから予算を拡大していくのが、成功率を上げる唯一の道です。
—
まとめ:データは現場の武器であって、重荷ではない
「顧客セグメント」は、経営層のレポートのためにあるのではありません。現場の営業やマーケターが、自信を持って「今日、このお客様にこの話をしよう」と思えるための武器です。
BigQueryを核とした動的セグメント基盤は、一度構築すれば、貴社のビジネスにおける「自動追尾システム」となります。古いExcelリストを捨て、データが自動で現場を動かすアーキテクチャへのシフトを、今こそ検討してください。
顧客データを統合した後は、それをどう具体的に「LINE」などの接点に活かすべきか。実戦的なアーキテクチャをこちらで紹介しています。
LIFF・LINEミニアプリ活用の本質。Web行動とIDを統合する次世代データ基盤
実務実装を成功させるための「技術的チェックリスト」
BigQueryを核とした動的セグメント運用を具体的に進める際、アーキテクチャ設計図には現れにくい「実務上の障壁」がいくつか存在します。プロジェクトを停滞させないために、以下の3点を事前に確認してください。
1. API制限とレートリミットの把握
リバースETL(CensusやHightouch)を用いてSalesforceなどのSaaSへデータを書き戻す際、各SaaS側が設けている「APIコール数上限」に注意が必要です。高頻度で全件更新をかけると、他の業務アプリの連携が停止するリスクがあります。差分更新(Incremental Sync)の設定が正しく機能するか、PoC段階での検証が必須です。
2. BigQueryのリージョンとデータガバナンス
日本のB2B企業において、顧客個人情報を扱う場合は「東京リージョン(asia-northeast1)」を選択するのが定石です。GA4からBigQueryへのエクスポート設定時にデフォルトの「US」を選択してしまうと、後からの変更は困難であり、コンプライアンス審査で指摘を受ける可能性があります。
3. ツール間の認証・権限管理(IAM)
troccoやリバースETLツールがBigQueryにアクセスするためのサービスアカウントには、必要最小限の権限(BigQueryデータ編集者など)を付与してください。
| 確認項目 | チェックすべきポイント | 参照ドキュメント(公式) |
|---|---|---|
| データの保存場所 | 東京リージョンが指定されているか | BigQuery のロケーション |
| SaaS側のAPI枠 | リバースETLの同期頻度と整合しているか | 各SaaS(Salesforce等)のAPI制限仕様 |
| コネクタの対応状況 | 利用中の国内SaaSがサポートされているか | trocco® 連携サービス一覧 |
単にツールを繋ぐだけでなく、組織の「負債」をいかに剥がしてクリーンな基盤を作るかについては、以下の記事が参考になります。
SaaSコストとオンプレ負債を断つ。バックオフィス&インフラの「標的」と現実的剥がし方
よくある誤解:CDPを導入すれば「名寄せ」は自動で終わる?
「高額なCDPを入れれば、魔法のようにデータが整理される」というのは代表的な誤解です。実際には、ソースデータ側の入力ルール(住所や電話番号の全角・半角混在など)がバラバラであれば、BigQuery上でSQLによるクレンジングロジックを書く手間は避けられません。ツールを導入する前に、まずは自社のデータの「汚れ」具合を可視化することが、失敗しない第一歩となります。
データ連携の全体像や、SFA・CRM・MAの正しい責務分解については、こちらの図解ガイドも併せてご活用ください。
【図解】SFA・CRM・MA・Webの違いを解説。高額ツールに依存しない『データ連携の全体設計図』
データ基盤の構築・セグメント設計に関するご相談
Aurant Technologiesでは、BigQueryを用いたデータ分析基盤の構築から、現場が動くCRM運用設計まで、実務に即したコンサルティングを提供しています。貴社のデータ活用を「絵に描いた餅」で終わらせません。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
【2026年実務版】BigQuery セグメント自動更新 標準アーキテクチャ
| 層 | 推奨ツール | 役割 |
|---|---|---|
| ①データ取込 | Fivetran / trocco | CRM・GA4・広告等を BQに集約 |
| ②セグメント定義 | dbt models(SQLで明文化) | 「優良顧客」「離反予兆」等を SQL で定義 |
| ③スケジュール実行 | Cloud Scheduler / Composer | 日次/時間バッチで自動更新 |
| ④Reverse ETL | Hightouch / Census | Salesforce/HubSpot/Brazeへ自動配布 |
| ⑤可視化・通知 | Looker Studio + Slack | セグメント変動の可視化 |
セグメント定義 標準テンプレ(SQL例)
-- 「離反予兆」セグメント SELECT customer_id FROM mart.customers WHERE last_login_days_ago BETWEEN 30 AND 60 AND total_orders_last_90d = 0 AND nps_score <= 6;
- 命名規則:
seg_{業務}_{条件}_v{バージョン} - レビュー:四半期で定義見直し
- テスト:dbt Tests で抽出件数の異常検知
配布先別 推奨セグメント設計
| 配布先 | セグメント例 | 更新頻度 |
|---|---|---|
| Salesforce(営業) | 優先フォロー対象 | 日次 |
| HubSpot/Marketo(MA) | 業種・スコア別ナーチャ | 日次 |
| Braze/Customer.io(CX) | 離反予兆・誕生日 | 時間バッチ |
| Google/Meta 広告 | 類似オーディエンス・除外 | 日次 |
| Slack(CSチーム) | 高優先度アラート | 即時 |
よくある質問(FAQ)
- Q1. パッケージCDPと比較したコストメリット?
- A. Treasure Data 100万円/月 → BigQuery+Hightouch 30万円/月に圧縮可能(中堅規模)。詳細は 顧客データ分析の最終稿。
- Q2. SQL書ける人がいないと無理?
- A. Hightouch/Census のノーコード Audience Builderで SQL不要のセグメント定義可能。
- Q3. リアルタイムセグメントは可能?
- A. 大半の業務は日次バッチで十分。即時性が必要なら Cloud Pub/Sub + Cloud Functions のストリーミング構成。
- Q4. 個人情報を Salesforce に書き戻す際の注意点は?
- A. 「同意取得済の顧客のみ」「機密属性のマスキング」「監査ログ保存」の3点必須。
- Q5. 構築期間は?
- A. 初期2-3ヶ月、運用安定化までさらに1-2ヶ月。
関連記事
- 【Reverse ETL】(ID 441)
- 【モダンデータスタック】(ID 12398)
- 【BigQuery×BI連携】(ID 243)
- 【dbt×BigQuery】(ID 372)
- 【顧客データ分析の最終稿】
※ 2026年5月時点の市場動向を反映。料金・機能仕様は各社公式情報をご確認ください。
CDP・顧客データ基盤の関連完全ガイド
本記事のテーマに関連するCDP/顧客データ基盤の徹底解説記事を以下にまとめています。ツール選定・アーキテクチャ設計の参考にどうぞ。
- 【完全ガイド】Treasure Data 徹底解説 2026:Treasure AI / Engage Studio 進化、機能・コスト・他社CDPとの比較
- 【完全ガイド】Braze 徹底解説 2026:CEPからBraze Data Platformへ、設計思想・機能・TCO・他社比較
- 【完全ガイド】KARTE Datahub 徹底解説:BigQuery基盤Web接客CDPの活用パターン・コスト・他社比較
- 【完全ガイド】Twilio Segment 徹底解説 2026:4モジュール構成・MTU課金・他社CDPとの比較
- 【完全ガイド】Adobe Real-Time CDP 徹底解説:3エディション・Identity Graph・Adobe Experience Cloud統合・TCO
- 【完全ガイド】Composable CDP vs パッケージCDP 徹底比較:Snowflake+dbt+Hightouch型と統合パッケージ型の判断軸
- 【完全ガイド】Reverse ETL 徹底解説 2026:Hightouch・Census・Polytomic・RudderStack を比較
- 【完全ガイド】CDP × Claude Code / MCP 活用パターン 2026:自然言語でCDPを運用する実装事例
freee会計 導入・運用 完全版シリーズ(全5回 + 旧会計ソフト移行ガイド)
freee会計の導入手順から経営可視化まで、フェーズ別の完全版ガイド一覧です。旧会計ソフトからの移行ガイドも併載。
- 【完全版・第1回】freee会計の導入手順と移行プラン。失敗しない「タグ設計」と準備フェーズの極意
- 【完全版・第2回】freee会計の初期設定フェーズ。開始残高のズレを防ぎ、マスタを連携させる絶対ルール
- 【完全版・第3回】freee会計の「日次業務」フェーズ。手入力をゼロにする「自動で経理」と自動登録ルールの極意
- 【完全版・第4回】freee会計の「月次業務」フェーズ。給与連携・月次締めを爆速化し、決算の精度を高める手順
- 【完全版・第5回】freee会計の「経営可視化・高度連携」フェーズ。会計データを羅針盤に変えるBIとAPI連携術
- 【完全版】PCA会計からfreee会計への移行ガイド:強固なコード体系の解体と移行実務
- 【完全版】ミロク(MJS)からfreeeへの移行ガイド。特殊な「単一行CSV」のAI変換と移行実務
- 【完全版】弥生会計からfreee会計への移行ガイド:専用ツールとタグ変換の実務
- 【完全版】勘定奉行からfreee会計への移行ガイド:機能・費用比較とデータ移行手順の実務
Salesforce Agentforce 完全攻略シリーズ
Salesforce Agentforce の事前準備・データ接続・KPI・プロンプト設計までフェーズ別に深掘りした完全ガイドです。
- Agentforce導入成功の鍵!決めるべき5つの事前準備(ユースケース・データ・権限・ガバナンス・体制)
- AgentforceでCSATを最大化する戦略:ナレッジ検索、AI回答、シームレスなエスカレーション設計
- Agentforce×ナレッジベース整備:RAG精度を最大化するコンテンツ設計チェックリスト【Aurant Technologies独自】
- Agentforce導入企業の必読!情報漏洩を防ぐ権限・監査ログ設計とガバナンス実装
- Agentforceで失敗しない!自動化できる業務・できない業務の見極め方と導入戦略
- Agentforceの品質KPI:正答率を超え、有用性・安全性・工数削減でビジネス成果を最大化する評価戦略
- Agentforceの真価を引き出すデータ接続設計:Salesforceレコード・ナレッジ・DWHの使い分けと連携パターンを徹底解説
- Agentforceプロンプト設計入門:トーン&マナー・禁止事項・引き継ぎ文でAIエージェントをビジネスの力に変える
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】Salesforce 完全ガイド:CRM/SFA/MA/CDP/Agentforce の使い分けと統合設計、業界別実装パターン
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】広告運用統合 完全ガイド:Google/Meta/LINE/TikTok の CAPI 設計と BigQuery 統合分析でROAS最大化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
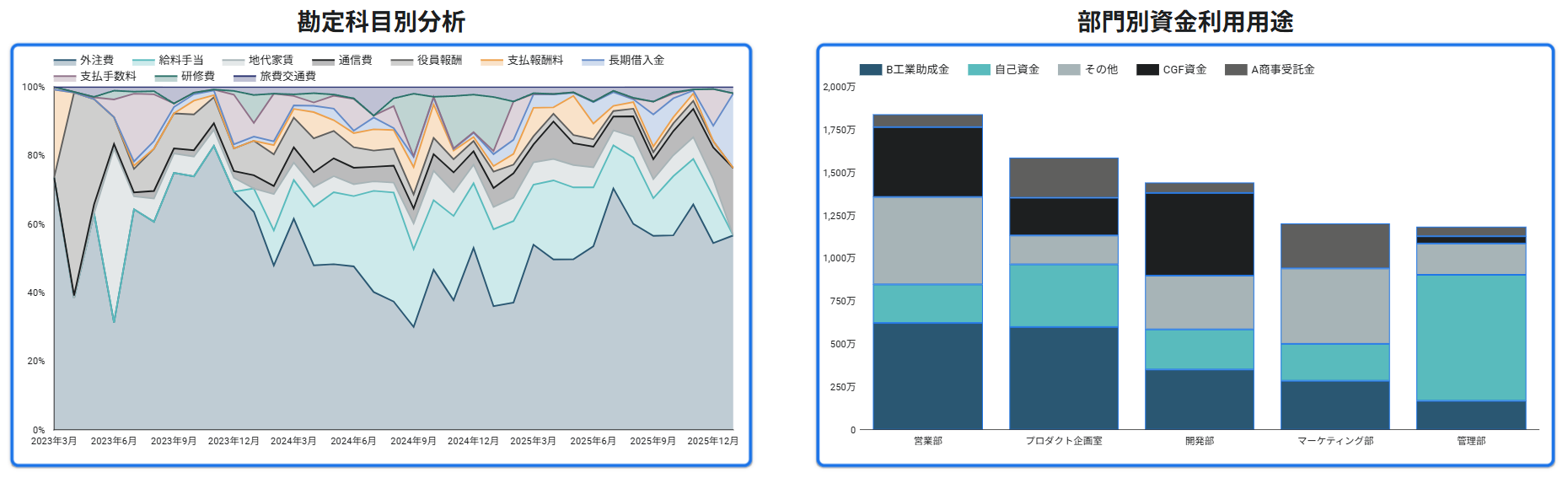
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
データ分析・BI
Looker Studio・Tableau・BigQueryを活用したBIダッシュボード構築から、データ基盤整備・KPI設計まで対応。経営判断をデータで支援します。