dbt×BigQuery データ変換・品質管理ガイド 2026:dbt Cloud vs Core・落とし穴対策
dbtとBigQueryの組み合わせでデータ変換の自動化と品質管理を実現し、データ活用を加速。ビジネス価値を最大化する具体的な進め方を詳解します。
目次 クリックで開く
dbt × BigQueryで実現するデータ信頼性の極致。変換自動化と品質管理を「ソフトウェア開発」へ昇華させる設計指針
「データはあるが、使い物にならない」という構造的欠陥を打破する。モダンデータスタックの核心であるdbtとBigQueryの統合アーキテクチャを、実務者の視点から徹底解説します。
1. なぜ「分析が進まない」のか?従来のデータ変換が抱える致命的課題
多くの企業がBigQueryにデータを集約(EL:Extract & Load)することには成功していますが、その後の「T(Transform:変換)」で挫折しています。Excelや手動のSQLスクリプト、あるいはブラックボックス化した高額なETLツールに頼った運用は、以下のリスクを内包しています。
- 属人化の極致: 複雑なビジネスロジックが特定の担当者のSQL内にのみ存在し、退職と共に解読不能になる。
- 品質の不透明性: 集計された「売上」の定義がダッシュボードごとに異なり、経営会議で数字の正当性論争が始まる。
- 変更コストの増大: 基幹システムのテーブル定義が変わった際の影響範囲が特定できず、修正が「当てずっぽう」になる。
これらの課題を解決するのが、データ変換を「ソフトウェア開発」の作法で管理するdbt(data build tool)です。
【図解】SFA・CRM・MA・Webの違いを解説。高額ツールに依存しない『データ連携の全体設計図』をご覧ください。
2. dbt × BigQuery:モダンデータスタックの最適解
dbtは単なる「SQL実行ツール」ではありません。BigQueryという強力な計算資源をエンジンとし、その上で動作する「オーケストレーター」兼「品質保証フレームワーク」です。
JinjaテンプレートによるSQLの動的制御
dbtでは、純粋なSQLに加えて「Jinja」というテンプレートエンジンを使用できます。これにより、SELECT * FROM {{ ref('stg_orders') }} のように記述するだけで、テーブル間の依存関係をdbtが自動認識します。
データテストによる自動品質保証
dbtの真価は、変換プロセスそのものに「テスト」を組み込める点にあります。
「このカラムにNULLは許容されない」「このIDはユニークであるべき」といった制約をYAML形式で定義するだけで、BigQuery側で自動的に検証クエリが走り、異常値を本番環境に流す前にブロックします。
| 機能 | 従来のデータ管理 | dbt × BigQuery |
|---|---|---|
| 開発言語 | ツール独自のUI / 複雑なPython | 汎用的なSQL (+ Jinja) |
| バージョン管理 | 困難(スクリプトのコピペ管理) | Gitによる完全な履歴管理 |
| 品質確認 | BIツールを見てから気づく | デプロイ前の自動テスト |
| ドキュメント | 手動メンテ(即座に陳腐化) | コードから自動生成されるリネージ図 |
3. 導入フェーズにおける具体的なアーキテクチャ設計
導入を成功させるには、以下の3つのステップを意識した設計が重要です。
Step 1:Source / Staging層の隔離
生データ(Raw Data)を直接加工してはいけません。まずはdbtのStaging層で、型変換やカラム名の標準化といった最低限のクレンジングのみを行い、物理的なテーブルとして分離します。
Step 2:Mart層へのビジネスロジック集約
Staging層を結合し、特定のビジネスドメイン(「顧客」「注文」など)ごとに整理されたMart層を構築します。ここに全ての計算ロジックを集約することで、BIツール側での計算(メジャーの定義)を最小化し、数値の揺れを防ぎます。
このデータ基盤から、LINEなどのフロントエンドへデータを戻す(リバースETL)ことで、より高度なアクションが可能になります。
「行動トリガー型LINE配信」の完全アーキテクチャはその好例です。
Step 3:CI/CDパイプラインの構築
GitHubと連携し、プルリクエストが作成された際に「dbt build」を自動実行する仕組みを構築します。これにより、「テストが通っていないコードは本番に反映されない」という厳格なガバナンスが実現します。
4. 結論:データ基盤は「資産」か「負債」か
データ量が増えるほど、管理されていないデータ変換は負債となります。dbtとBigQueryを導入することは、単なるツールの追加ではなく、「データの品質に責任を持つ体制」へのシフトを意味します。
Aurant Technologiesでは、100社以上のBI研修、50件以上のCRM導入支援を通じて培った「現場で機能するロジック」をベースに、dbtを用いたデータパイプラインの構築・自動化を支援しています。ツールを入れることがゴールではありません。その先の意思決定の精度を最大化するために、私たちはアーキテクチャから見直します。
4. 実務導入で突き当たる「dbt Cloud」か「dbt Core」かの選択
dbtを導入する際、最初に直面するのが商用SaaS版の「dbt Cloud」を使うか、オープンソース版の「dbt Core」を自前で運用するかという選択です。結論から言えば、社内にインフラ専任のエンジニアがいない場合は、dbt Cloudの利用を強く推奨します。
dbt Coreを選択した場合、GitHub Actionsなどを用いたCI/CDパイプラインの構築や、実行ログの管理、メタデータ(ドキュメント)のホスティング環境をすべて自前で用意する必要があります。一方で、dbt Cloudはこれらをパッケージ化しており、IDE(開発環境)もブラウザ上で完結します。
| 項目 | dbt Cloud (Teamプラン以上) | dbt Core (セルフホスト) |
|---|---|---|
| 導入コスト | 月額100ドル/1ユーザー〜(要確認) | ライセンス無料 |
| 運用負荷 | 低い(マネージド環境) | 高い(サーバー、CI/CD自作) |
| 開発環境 | 専用のブラウザIDEが提供 | VS Code等のローカル環境が必要 |
| セキュリティ | 公式のSSO連携等が利用可能 | 自社のインフラ設計に依存 |
※2024年以降、dbt Cloudの価格体系は「開発ユーザー数」と「実行成功数」に基づいたモデルに変更されています。最新の料金詳細は、dbt Labs公式価格ページにて必ずご確認ください。
5. BigQuery連携時の技術的落とし穴とベストプラクティス
dbtとBigQueryを接続する際、パフォーマンスとコストの両面で注意すべきポイントが3つあります。
- パーティションとクラスターの設定: 大規模なMart層を構築する場合、dbtの
configブロックでpartition_byやcluster_byを明示してください。これを怠ると、dbtの実行(ビルド)のたびに全スキャン走り、BigQueryのクエリ課金が急増します。 - リージョンの一致: ソースデータのデータセットと、dbtが書き出すターゲットのデータセットは、同じリージョン(例:
asia-northeast1)である必要があります。 - サービスアカウントの権限管理: dbtには「データの読み取り(Viewer)」「データの書き込み(Editor)」「ジョブの実行(User)」の権限が必要です。過剰な権限付与を避け、最小権限の原則で運用しましょう。
dbtが推奨する「プロジェクト構成(Project Structure)」のベストプラクティスは、公式ドキュメントに詳細にまとめられています。導入前に一読することをお勧めします。
How we structure our dbt projects (dbt Official)
また、データ基盤を構築した後の出口戦略として、高額なCDPを導入せずとも、分析結果をマーケティングに活用する方法があります。詳細は、BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定の記事も併せて参照してください。
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
dbt 主要機能と推奨運用
| 機能 | 役割 | 推奨設定 |
|---|---|---|
| Models | SQL変換 | 3層(Raw/Staging/Mart) |
| Tests | データ品質保証 | ユニーク・NotNull・関連 |
| Documentation | 自動生成 | 公開リポジトリ管理 |
| Lineage | 依存関係可視化 | DAG表示 |
| Snapshots | SCD Type 2履歴管理 | マスタ変更追跡 |
dbt Cloud vs Core 選定
- dbt Core(OSS / 無料):自前で CI/CD構築可能なチーム
- dbt Cloud(月100 USD〜):マネージド・スケジューリング・Web IDE
FAQ
- Q1. dbt 導入の最小構成は?
- A. BigQuery + dbt Core + GitHub Actionsで月額数千円から開始可能。
- Q2. SQL以外のスキルは必要?
- A. YAML + Git の基礎のみ。SQLが書ければ十分。
関連記事
- 【BigQuery vs Snowflake】(ID 244)
- 【BigQuery×BI連携】(ID 243)
- 【DWH構築実践ガイド】(ID 276)
- 【Snowflake×Looker Studio】(ID 210)
※ 2026年5月時点の市場動向を反映。
CDP・顧客データ基盤の関連完全ガイド
本記事のテーマに関連するCDP/顧客データ基盤の徹底解説記事を以下にまとめています。ツール選定・アーキテクチャ設計の参考にどうぞ。
- 【完全ガイド】Treasure Data 徹底解説 2026:Treasure AI / Engage Studio 進化、機能・コスト・他社CDPとの比較
- 【完全ガイド】Braze 徹底解説 2026:CEPからBraze Data Platformへ、設計思想・機能・TCO・他社比較
- 【完全ガイド】KARTE Datahub 徹底解説:BigQuery基盤Web接客CDPの活用パターン・コスト・他社比較
- 【完全ガイド】Twilio Segment 徹底解説 2026:4モジュール構成・MTU課金・他社CDPとの比較
- 【完全ガイド】Adobe Real-Time CDP 徹底解説:3エディション・Identity Graph・Adobe Experience Cloud統合・TCO
- 【完全ガイド】Composable CDP vs パッケージCDP 徹底比較:Snowflake+dbt+Hightouch型と統合パッケージ型の判断軸
- 【完全ガイド】Reverse ETL 徹底解説 2026:Hightouch・Census・Polytomic・RudderStack を比較
- 【完全ガイド】CDP × Claude Code / MCP 活用パターン 2026:自然言語でCDPを運用する実装事例
関連ピラー:【ピラー】データガバナンス完全ガイド:データカタログ・メタデータ管理・品質モニタリング・アクセス権限の統合設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
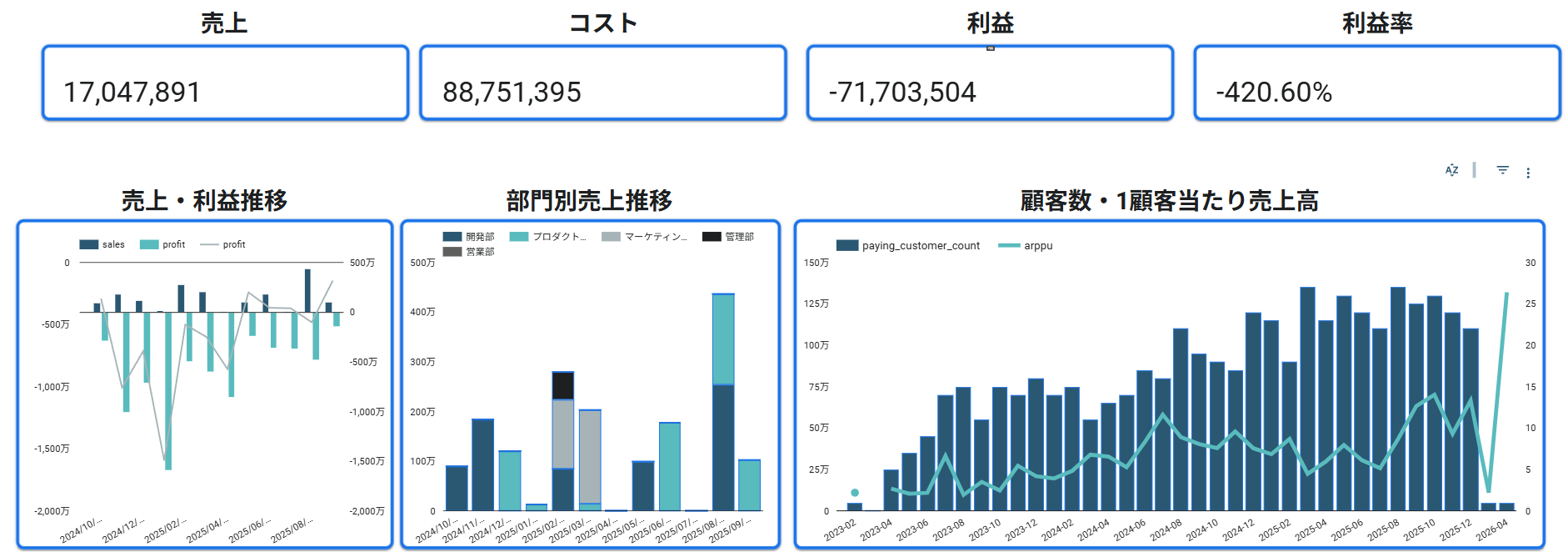
データ分析・BI
Looker Studio・Tableau・BigQueryを活用したBIダッシュボード構築から、データ基盤整備・KPI設計まで対応。経営判断をデータで支援します。