データ活用×個人情報保護 ガイド 2026:匿名加工/仮名加工の使い分け・3ツール選定
データ活用と個人情報保護の両立は可能。匿名化・仮名化、アクセス制御の具体的な設計・運用で、法的リスクを回避しつつビジネスを加速するDX戦略を解説します。
目次 クリックで開く
データ活用と個人情報保護を両立!匿名化・アクセス制御で実現する安全なDX戦略
「データを使いたいが、法務のNGが出る」「漏洩リスクが怖くて一歩踏み出せない」。100社以上のデータ活用を支援してきた現場から、技術と法規制を橋渡しする「実務の正解」を徹底解説します。
DX(デジタルトランスフォーメーション)の成否は「データの民主化」にかかっています。しかし、多くの日本企業において、この民主化を阻む最大の壁は、ITスキル不足ではなく「個人情報保護への過度な懸念」です。
本稿では、BI研修やCRM導入の現場で私(近藤)が目撃してきた「失敗する典型パターン」を反面教師に、匿名化技術、ガバナンス設計、そして最新のツール選定までを網羅した、実務者のための「究極のガイドブック」をお届けします。
1. データ活用と個人情報保護:なぜ「両立」が絶対条件なのか
現代ビジネスにおいて、データは石油ではなく「血液」です。止まれば組織は機能不全に陥ります。しかし、不適切な取り扱いは企業の社会的生命を絶つ猛毒にもなり得ます。
企業におけるデータ活用の重要性とメリット
データを活用することで、勘と経験に頼った経営から、確実なデータに基づいた科学的経営へとシフトできます。
- LTVの最大化: 顧客の行動ログを分析し、離脱兆候を捉えた適切なタイミングでのアプローチ。
- 業務効率の劇的改善: 現場のボトルネックを可視化し、リソース配置を最適化。
- 新規事業の創出: 既存顧客の未充足ニーズをデータから発見。
個人情報保護法改正がもたらす「重い責任」
2022年の法改正以降、漏洩時の報告義務化や罰則の強化(法人に対して最大1億円の罰金)がなされました。
【出典:個人情報保護委員会 – 法令・指針等】
特に注目すべきは、単なる「守り」だけでなく、「仮名加工情報」という新しいデータ区分が新設され、社内分析においては利活用の柔軟性が高まった点です。
多くの企業が陥る罠は、「法務部門が技術を知らず、IT部門が法律を知らない」という分断です。結果として、最も安全な「データを一切共有しない」という結論になり、高額なBIツールが「自分専用のExcel集計機」と化します。データ活用は、最初から「活用すること」を前提としたデータ設計(Data-by-Design)が不可欠です。
2. 匿名加工情報と仮名加工情報の「使い分け」実務
個人データをそのまま扱うリスクを避けるため、2つの加工手法を正しく理解する必要があります。
匿名加工情報:オープンデータ・第三者提供向け
特定の個人を二度と復元できないように加工したものです。
- メリット: 本人の同意なしに第三者提供が可能。
- デメリット: 加工プロセスが極めて厳格であり、分析の精度(粒度)が落ちやすい。
仮名加工情報:社内分析・PDCAサイクル向け
他の情報と照合しない限り個人を特定できない状態にしたものです(氏名をIDに変換するなど)。
- メリット: 利用目的の変更が柔軟になり、AIの学習データなどに適している。
- デメリット: 第三者提供は原則禁止。
比較表:匿名加工 vs 仮名加工 vs 個人データ
| 項目 | 個人データ | 仮名加工情報 | 匿名加工情報 |
|---|---|---|---|
| 本人特定 | 可能 | 照合により可能 | 不可能 |
| 利用目的の変更 | 原則同意が必要 | 相当の関連性でOK | 自由 |
| 第三者提供 | 同意が必要 | 原則不可 | 可能(公表要) |
| 漏洩報告義務 | あり | あり | なし(推奨) |
3. 主なツール選定:安全なデータ基盤を構築する
現場で実際に導入し、セキュリティと利便性のバランスが優れていると感じるツールを紹介します。
① Google BigQuery (Google Cloud)
圧倒的なスケーラビリティと、詳細なアクセス制御(IAM)が特徴です。カラムレベルの暗号化や動的データマスキングが可能で、特定のユーザーにはメールアドレスを見せず、分析担当にはハッシュ化した値を表示するといった運用が容易です。
【公式URL】https://cloud.google.com/bigquery
② trocco (株式会社primeNumber)
日本発のデータエンジニアリングプラットフォーム。ETL/ELTの過程で個人情報をマスキング・ハッシュ化する機能が充実しており、エンジニアでなくても「安全なデータ転送」を自動化できます。
【公式URL】https://trocco.io/
③ dbt (dbt Labs)
データウェアハウス内でのデータ変換を管理するツール。データの出自(リネージ)を可視化できるため、「どのカラムが個人情報に由来しているか」を完全に追跡・管理できます。
【公式URL】https://www.getdbt.com/
初期費用: 0円〜100万円(troccoなどのSaaS利用時)。月額費用: スモールスタートで月10万円〜。中堅企業で分析を本格化させるなら月30万〜50万円が目安です。隠れたコスト: 「データクレンジング」の工数です。マスタが汚いと、匿名化する前にデータが使い物になりません。ここを軽視すると、ライセンス料の数倍の人件費が溶けます。
4. 導入事例と成功シナリオ
【小売業 A社】会員データ活用の壁を突破
課題: CRM導入後、店舗スタッフが顧客の購入履歴を見たいが、個人情報(電話番号等)の全公開はリスクが高すぎると法務が反対。解決策: BigQueryの「動的データマスキング」を採用。権限レベルに応じて、上位管理職はフル表示、現場スタッフは「090-****-1234」のように加工されたデータを参照する仕組みを構築。成果: 接客時のレコメンド精度が向上。個人情報保護と売上向上の両立を実現。
【出典URL:Google Cloud 導入事例 – メルカリ(参考)】
【製造業 B社】AIによる故障予測の学習データ作成
課題: 外部のAI開発会社に機械稼働データと担当者のログを渡したいが、担当者の氏名やスキルレベルが個人情報に該当。解決策: 「仮名加工情報」としてID化し、特異な値を丸める(一般化)処理を実施。外部ベンダーには「誰か」はわからないが「傾向」はわかる状態で提供。成果: 外部知見を活用し、故障予測AIの精度が20%向上。
データ基盤を構築する際、広告媒体との連携を考えるなら、CAPI(コンバージョンAPI)の活用もセットで検討すべきです。
内部リンク:広告×AIの真価を引き出す。CAPIとBigQueryで構築する「自動最適化」データアーキテクチャ
また、SFAやCRMとの全体設計については、こちらの図解が参考になります。
5. 結論:安全なデータ活用への4ステップ
最後に、明日から取り組むべきアクションをまとめます。
- データ棚卸し: どのデータが「個人データ」で、どれが「要配慮個人情報」かを定義する。
- 目的の再定義: 「分析」のためなら仮名加工、「共有」のためなら匿名加工を選択する。
- ツールの責務分解: 収集はSaaS、匿名化はETL、保持・制御はDWH(BigQuery等)と役割を分ける。
- 運用ルールの明文化: 誰が、いつ、何の目的でデータに触れるかをIAM(アクセス制御)で縛る。
データ活用は「魔法」ではありません。地道な設計とガバナンスの上にのみ、ビジネスを加速させる強力な武器となります。リスクを恐れて足を止めるのではなく、適切な「防具(技術と知識)」を整えて、データの海へ漕ぎ出しましょう。
貴社のデータ活用を「安全」に加速させませんか?
現場を知るコンサルタントが、法規制対応と技術実装の両面からサポートします。
実務担当者が押さえるべき「データ活用の安全性」チェックリスト
既存の本文で解説した「匿名化・仮名化」を確実に運用するためには、技術的な実装だけでなく、組織的なガバナンスが欠かせません。特に「仮名加工情報」を社内分析で利用する場合、個人情報保護法に基づき、特定の個人を再識別するための「照合」が厳格に禁止されています。
導入前に確認したい「安全管理措置」の3要件
- 識別行為の禁止: 仮名加工情報を他の情報と照合し、本人を特定しようとしない運用フローが構築されているか。
- 削除情報の適切な管理: 氏名やIDの対応表など、加工前の状態に戻せる情報を「特権管理者」のみがアクセスできる別環境に隔離しているか。
- 内部規定の整備: データの取り扱いに関する社内マニュアルを整備し、定期的な監査を実施しているか。
データ利活用の精度を左右する「前処理」の重要性
本文でも触れた通り、匿名化の前に不可欠なのが「データクレンジング」です。特に、複数のSaaSからデータを統合する場合、同一人物が異なるIDで登録されている「名寄せ(アイデンティティ・レゾリューション)」が不十分だと、分析精度が著しく低下します。この設計を誤ると、後に大きな手戻りが発生するため、初期段階での「データモデル設計」が肝要です。
【比較】データエンジニアリングとセキュリティ機能の相関
| 機能カテゴリ | 主要な実装手段 | 実務上のメリット |
|---|---|---|
| アクセス制御 | Google BigQuery (IAM) | 列・行レベルでの参照権限を細かく分離できる。 |
| 動的マスキング | Cloud Data Masking | 実データを書き換えずに、権限に応じて「表示」を加工できる。 |
| リネージ管理 | dbt (Data Lineage) | 個人情報がどのテーブルを通り、どこで加工されたか追跡できる。 |
公式リファレンスとさらなる学び
各ツールの具体的な実装仕様や、法的な定義については、必ず以下の一次情報を参照してください。
安全なデータ活用環境を整えた後、次に課題となるのは「いかに効率よくデータをビジネス価値に変えるか」というツール選定です。高額なCDPを導入する前に、以下の記事で「モダンデータスタック」の構成を検討することをお勧めします。
内部リンク:高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
また、Webサイト上の行動データと個人情報をシームレス、かつ安全に統合する具体的なアーキテクチャについては、こちらのガイドが役立ちます。
内部リンク:WebトラッキングとID連携の実践ガイド。ITP対策・LINEログインを用いたセキュアな名寄せアーキテクチャ
業務システム・DX全般のご相談
業務の課題整理からツール選定、システム導入・連携・運用までを幅広く支援します。何から手をつけるべきか迷う段階でも、貴社の状況に合わせて最適な進め方をご提案します。
個人情報保護 必須対応チェックリスト
- ☑ 改正電気通信事業法(外部送信規律)
- ☑ 個人情報保護法(越境移転規制)
- ☑ Cookie同意(Consent Mode v2)
- ☑ GDPR / CCPA / LGPD(海外展開時)
- ☑ マイナンバー保管(アクセス権限分離)
匿名化技術
| 技術 | 用途 |
|---|---|
| 仮名化 | ID置換・分析時用 |
| k-匿名化 | 統計データ匿名化 |
| 差分プライバシー | 高度な統計分析 |
| Dynamic Masking(DWH) | ロール別表示制御 |
FAQ
- Q1. CMP(同意管理)の主要ツールは?
- A. OneTrust / TrustArc / Usercentrics。
- Q2. データクリーンルームの活用は?
- A. 個人情報を出さずに集合データで分析。Snowflake / Meta / Google が対応。
関連記事
- 【データガバナンス】(ID 396)
- 【顧客データ分析の最終稿】
- エンタープライズ生成AIセキュリティ実践
※ 2026年5月時点の制度を反映。
関連ピラー:【ピラー】データガバナンス完全ガイド:データカタログ・メタデータ管理・品質モニタリング・アクセス権限の統合設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
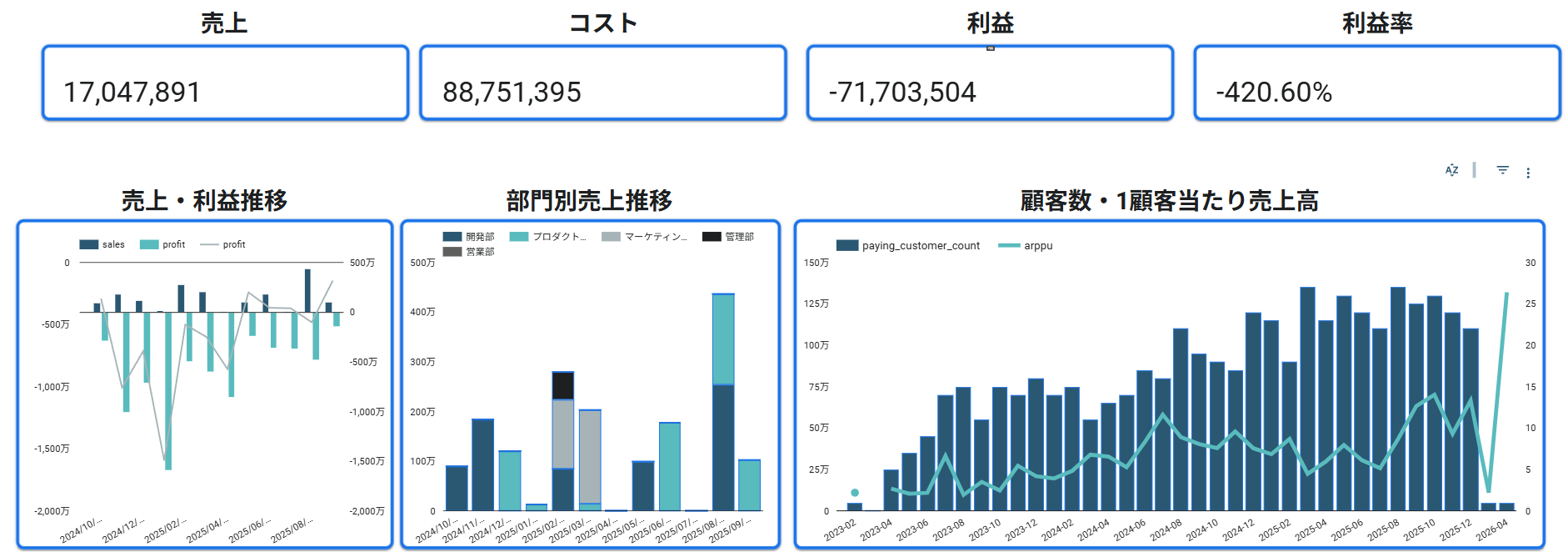
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
CRM・営業支援
Salesforce・HubSpot・kintoneの選定から導入・カスタマイズ・定着まで一貫対応。営業生産性を高め、商談化率を改善します。



