自然言語データ分析 ガイド 2026:SQL不要のAI分析フロー・主要ツール・3箇条で失敗回避
SQL依頼のボトルネックをAIが解消。自然言語で指標定義、クエリ生成、分析、解釈まで一気通貫。データ分析の民主化でビジネスを加速させます。
目次 クリックで開く
SQL依頼はもう不要!AIが自然言語でデータ分析を完結させる「脱・専門家依存」の究極ガイド
「このデータ、抽出して」という一言がデータアナリストの時間を奪い、ビジネスの意思決定を停滞させる時代は終わりました。本稿では、100社以上のBI・CRM導入を支援してきた現場視点から、生成AI(LLM)とデータ基盤を統合し、SQLを書かずに深いインサイトを得るための「次世代データ分析アーキテクチャ」を徹底解説します。
1. なぜ「SQL依頼」が企業のDXを停滞させるのか
多くの企業がデータドリブン経営を標榜しながら、現場では「SQLを書ける社員への依存」という構造的欠陥に苦しんでいます。私がこれまで見てきた現場では、マーケティング担当者がキャンペーンのROIを確認したいと思ってから、実際にデータが手元に届くまでに平均3〜5営業日を要していました。この「待機時間」こそが、ビジネス機会の損失そのものです。
専門知識の壁と「データアナリストの疲弊」
SQLは習得に時間がかかるだけでなく、データベースの物理構造(テーブル設計)を熟知していなければ正しいクエリは書けません。その結果、特定のエンジニアやアナリストに依頼が集中し、彼らは「価値を生む分析」ではなく「単純なデータ抽出作業」に追われることになります。
現場でよくある失敗は、「SQLが書ける」ことと「正しい数字が出せる」ことを混同することです。例えば、CRMから退会者を除外するフラグや、テストアカウントを弾くロジックをSQL担当者が把握していない場合、技術的に完璧なクエリでも、経営判断を誤らせる「汚れた数字」が算出されます。AIによるデータ分析の真の価値は、こうした「業務上の定義」をプロンプトとして組み込める点にあります。
2. AIが実現する「SQL不要」のデータ分析フロー
生成AI(特にGPT-4oやClaude Sonnet 4.6など)の進化により、人間が普段話す言葉(自然言語)を直接SQLに変換し、実行まで完結させる「Text-to-SQL」技術が実用レベルに達しています。
自然言語からクエリ生成・実行までの4ステップ
- 質問の入力:「先月の関東エリアにおける、商品カテゴリ別のリピート率推移を教えて」
- セマンティック理解:AIが「関東エリア」「リピート率」の定義をマスタデータと照合。
- SQL自動生成:データベースのスキーマ情報を参照し、最適なJOINと集計クエリを生成。
- 可視化・解釈:抽出されたデータをグラフ化し、「なぜその数字になったか」をAIが解説。
【図解】SFA・CRM・MA・Webの違いを解説。高額ツールに依存しない『データ連携の全体設計図』
3. 主要な国内外ツールの紹介とコスト感
現在、自然言語でのデータ分析を可能にするツールは急速に増えています。実務で選定候補に上がる代表的なツールを比較します。
| ツール名 | 特徴 | 公式サイトURL | コスト目安(初期/月額) |
|---|---|---|---|
| ThoughtSpot | 「検索」特化型BIの世界的リーダー。AI(Sage)による自然言語検索が極めて強力。 | https://www.thoughtspot.com/jp | 初期:要問合せ 月額:約$2,500〜(利用量課金) |
| Looker (Google Cloud) | セマンティックモデル(LookML)により、AIが「正しい定義」でSQLを書く基盤を提供。 | https://cloud.google.com/looker | 初期:無料(設定代行別) 月額:約$5,000〜(プラットフォーム料) |
| Domo | データ統合からAI分析まで一貫。直感的なUIで非エンジニアの定着率が高い。 | https://www.domo.com/jp | 初期:要問合せ 月額:従量課金制(要見積) |
ツール導入時に見落としがちなのが、「メタデータの整備コスト」です。AIに「売上」と聞いた時、それが「税込」か「税別」か、あるいは「キャンセルを含む」のかを教えてあげなければ、AIは適当なカラムを推測して集計してしまいます。この「辞書作り」こそが、導入成功の8割を決定します。
4. 【実践事例】SQL不要の分析基盤がもたらした成果
実際に、私が支援した製造業B社(売上高500億円規模)の事例を紹介します。
導入前の課題
- 営業企画部が「製品ごとの在庫回転率」を知りたい場合、情報システム部にSQL依頼を出す必要があった。
- 情シス側のリソース不足により、回答まで平均1週間。結局、古いデータで判断を下していた。
構築したソリューション
BigQuery上にデータウェアハウス(DWH)を構築し、フロントにLookerを配置。営業担当者が自然言語で「今週の欠品リスクが高い製品リスト」と入力するだけで、即座にリストが表示される環境を構築しました。
【出典URL】Google Cloud 導入事例:Lookerによるデータ主導型組織への変革(リファレンス)
成果
- 意思決定スピード: 1週間 → 数秒に短縮。
- 工数削減: 情シスへのデータ抽出依頼が月間80%減少。
- 付加価値: 空いた時間で、アナリストが「将来の需要予測モデル」の構築に注力可能になった。
【完全版・第5回】freee会計の「経営可視化・高度連携」フェーズ。会計データを羅針盤に変えるBIとAPI連携術
5. 実務上の落とし穴:AIデータ分析を失敗させないための3箇条
最後に、これまで数々の失敗プロジェクトを救済してきた経験から、絶対に守るべきポイントを伝えます。
① ガバナンスなき自由は「数字の混乱」を招く
誰でも自由に質問できる環境は素晴らしいですが、人によって「粗利」の定義が異なれば、会議で出てくる数字がバラバラになります。必ずツール側で「標準指標(Canonical Metrics)」を定義し、それをAIに参照させてください。
② セキュリティとプライバシーの設計
自然言語で何でも聞けるということは、権限設定を誤ると「役員の給与」や「機密性の高い原価」まで平社員が抽出できてしまうリスクがあります。データベース側の行レベルセキュリティ(Row-Level Security)との連動が必須です。
③ 最終的な「解釈」は人間が責任を持つ
AIは相関関係を見つけるのは得意ですが、因果関係を断定することはできません。AIが出した「広告を増やしたから売上が上がった」という回答が、単なる季節要因(ボーナス時期)を無視していないか、最後はプロフェッショナルの目が必要です。
高度な分析ツールは高価です。もしライセンス費用が経営を圧迫しているなら、既存のSaaS構成を見直すことで、分析基盤への投資予算を捻出できるかもしれません。特にアカウントの削除漏れや重複機能の排除は、即効性のあるコスト削減策です。
SaaS増えすぎ問題と退職者のアカウント削除漏れを防ぐ。自動化アーキテクチャ
まとめ:データは「依頼するもの」から「会話するもの」へ
SQL依頼という儀式を廃止し、AIとの対話によってデータを手なずけることが、これからのコンサルタントやビジネスリーダーに求められる必須スキルです。初期のメタデータ設計には苦労が伴いますが、一度構築してしまえば、組織のスピードは劇的に向上します。
もし貴社で「データはあるが、活用するまでに時間がかかる」という課題をお持ちであれば、まずは小規模なDWHとText-to-SQLのPoCから始めることをお勧めします。その一歩が、貴社を真のデータドリブン組織へと変貌させるはずです。
6. 導入前に確認すべき「AIデータ分析」の最新仕様と注意点
記事本編で触れたツール群は進化が非常に速く、特にGoogleエコシステムにおいては、BigQueryとGemini(LLM)の直接連携により、BIツールを介さない「SQLレス分析」の選択肢も広がっています。実務に投入する前に、以下の最新動向とチェックリストを確認してください。
公式情報に基づく最新のシステム選定チェック
| 確認項目 | 実務上の注意点と最新仕様 | 参照・裏取り用URL |
|---|---|---|
| Lookerの料金体系 | 2024年以降、従来の定額制に加え、Google Cloudのコンソールから直接起動できる「Looker (Google Cloud core)」が登場しています。エディションにより利用可能な機能が異なるため、旧来の月額$5,000〜という目安は構成により変動します。 | Looker 公式料金ドキュメント |
| Gemini in BigQuery | SQLを書かずにチャット形式でデータ操作を行う機能は、現在「Gemini in BigQuery」として提供されています。プレビュー版やリージョン制限がある機能も多いため、本番導入前に組織のプロジェクト環境での有効化可否を確認してください。 | Gemini in BigQuery 概要 |
| データ鮮度の定義 | AIは「最新のデータ」を抽出しますが、そもそもDWHへのデータ転送(ELT/ETL)がバッチ処理(日次など)の場合、リアルタイムな数字は出せません。意思決定に秒単位の鮮度が必要な場合は、ストリーミング挿入の検討が必要です。 | 公式サイトで要確認 |
Text-to-SQLの多くは「行と列」で整理された構造化データが対象ですが、最近ではPDFの契約書や議事録といった「非構造化データ」をBigQueryのオブジェクトテーブルに格納し、AIで直接分析する手法も一般化しています。データの種類に応じたアーキテクチャの使い分けについては、以下のガイドも参考になります。
よくある誤解:AIを導入すれば「データクレンジング」は不要か?
結論から言えば、AI導入後こそデータクレンジングの重要性は増します。AIは「表記揺れ」や「論理的な矛盾(例:売上がマイナスの返品処理が考慮されていない等)」を含んだまま計算を実行してしまうリスクがあるためです。
特に複数のSaaSを横断して分析する場合、IDの名寄せ(ユニークユーザーの特定)が不十分だと、AIは誤った顧客インサイトを出力します。このあたりの「名寄せの落とし穴」については、以下の実践ガイドが役立ちます。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
自然言語データ分析 主要ツール
| ツール | 特徴 |
|---|---|
| Snowflake Cortex Analyst | SQL不要・Snowflake内 |
| BigQuery Gemini連携 | SQL自動生成 |
| Tableau Pulse | 自然言語インサイト |
| Sigma AI | Sheets文化+AI |
| ChatGPT/Claude + 内製 | Custom GPT で社内データ分析 |
構築ステップ
- セマンティック層定義(YAMLでテーブル/メトリクス/同義語)
- 権限制御(ロール別マスキング)
- UI連携(Slack / Teams / 専用Webアプリ)
- フィードバックループ(誤回答の継続改善)
FAQ
- Q1. 精度はどこまで信頼できる?
- A. 「セマンティック層が整備されていれば 90%超」。
- Q2. データアナリスト不要になる?
- A. 「定型分析は自動化、深い洞察は人」の役割分担。
関連記事
- 【Snowflake×Looker Studio】(ID 210)
- 【Cursorデータ分析活用】(ID 424)
- 【LLM業務活用ロードマップ】(ID 280)
- 【顧客データ分析の最終稿】
※ 2026年5月時点の市場動向を反映。
業界別 基幹システム刷新【完全ガイド】
本記事に関連する業界の基幹システム刷新ガイドはこちらです。業界特有の業務要件・主要プレイヤー・移行アプローチを解説しています。
AIエージェント / RAG 設計の完全ガイド
AIエージェント・RAG・LLMの導入と運用設計を深掘りした記事一覧です。
関連ピラー:【ピラー】データガバナンス完全ガイド:データカタログ・メタデータ管理・品質モニタリング・アクセス権限の統合設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
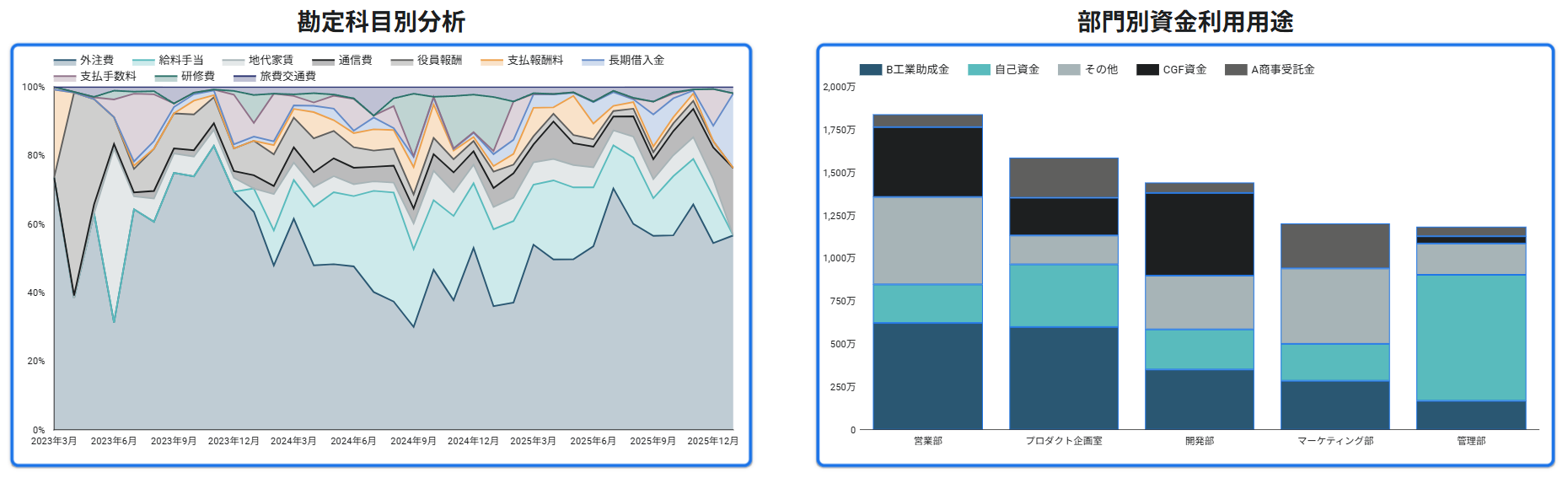
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。