Airbyte×BigQuery データ連携構築ガイド 2026:OSS活用・運用コスト最適化・属人化回避
AirbyteとBigQueryでデータ連携を構築し、DX・業務効率化・マーケティングを加速する方法を解説。オープンソースETL/ELTの導入から活用事例まで、実務経験に基づいた具体的助言を提供します。
目次 クリックで開く
企業が抱えるデータは、SaaSの普及により分散化の一途を辿っています。CRM、会計ソフト、広告プラットフォーム——それぞれの管理画面からCSVをダウンロードし、手作業でExcelに集計する運用は、もはや限界です。
本稿では、オープンソースのデータ統合プラットフォーム「Airbyte」と、Google Cloudの強力なデータウェアハウス(DWH)「BigQuery」を組み合わせ、データパイプラインを自動化・高度化する実務ガイドを公開します。
データ連携の要諦は「ツールの導入」ではなく「責務の分離」にあります。Airbyteを単なる転送ツールとして使い倒し、加工はDWH側に寄せる。このモダンデータスタックの思想が、将来の拡張性と保守性を担保します。
1. なぜ「Airbyte × BigQuery」なのか
データ基盤構築において、Airbyteが選ばれる理由は「コネクタの豊富さ」と「透明性の高いコスト構造」にあります。
| 比較項目 | Airbyte (OSS / Cloud) | 他社商用ETL / Fivetran等 |
|---|---|---|
| コネクタ数 | 600以上(OSSコミュニティが随時追加) | 限定的だが安定性が極めて高い |
| 課金体系 | OSSは無料、Cloudはクレジット制 | 同期レコード数(MAR)や行数に応じた高額課金 |
| データ加工 | EL(抽出・ロード)に特化 | ツール内でのGUI変換機能が豊富 |
特に、広告データやCRMデータの蓄積において、BigQueryとの親和性は抜群です。集約したデータを基に、AIを活用した予測モデルや自動入札の最適化へ繋げるための「一丁目一番地」と言えます。
💡 関連:広告×AIの真価を引き出す。CAPIとBigQueryで構築する「自動最適化」データアーキテクチャ
2. データアーキテクチャの全体像
構築するパイプラインは、以下の「ELT(Extract, Load, Transform)」モデルを採用します。
この構成のメリットは、「データの再現性」です。元データをそのままBigQueryにロードしておくことで、後から集計ロジックが変わっても、過去に遡ってデータを再定義することが可能です。
3. 実務者向け:構築時のチェックポイント
認証とセキュリティ
BigQueryをDestination(出力先)とする場合、サービスアカウントの発行と権限設定が必須です。最小権限の原則に基づき、以下のロールを付与したJSONキーを用意してください。
- BigQuery Data Editor
- BigQuery Job User
同期モードの選定
データの特性に合わせて、以下のモードを使い分ける必要があります。
- Full Refresh | Overwrite: 毎回全データを入れ替える。マスタデータ等に。
- Incremental | Append: 差分のみを追記する。ログやトランザクション等に。
- Incremental | Deduped History: 差分を追記しつつ、最新のユニーク値を保持する。
データソース側(SaaS側)のAPI制限には注意が必要です。同期頻度を上げすぎると、業務で利用しているSaaS側が制限に掛かり、システムが停止するリスクがあります。
4. 運用コストとリソースの最適化
Airbyte OSSを自社サーバー(GCP Compute Engine等)で運用する場合、ソフトウェア費用は無料ですが、インフラの維持管理リソースが発生します。一方で、非エンジニア部門が主導する場合は、マネージド版であるAirbyte Cloudの利用が、トータルコスト(TCO)の観点から合理的です。
データがBigQueryに集約されれば、次は「いかにアクションに繋げるか」のフェーズです。例えば、集約した顧客行動データをLINE公式アカウントのパーソナライズ配信に活用する構成などが考えられます。
💡 関連:高額MAツールは不要。BigQueryとリバースETLで構築する「行動トリガー型LINE配信」
まとめ:データ活用を「属人化」から「資産化」へ
AirbyteとBigQueryの組み合わせは、エンジニアリングの難易度を下げつつ、プロフェッショナルな分析基盤を構築するための最短距離です。手作業のCSV連携から脱却し、データが自動で集まり、価値を生み続ける状態を構築しましょう。
さらに踏み込んだデータ基盤の全体設計については、以下のガイドも参考にしてください。
データ基盤を安定稼働させるための実務補足
AirbyteとBigQueryを連携させ、実運用に乗せる段階で直面しやすい「コスト」と「設計」の最適化について、公式の最新情報をベースに解説します。
Airbyte OSS版とCloud版の選定基準
既存本文でも触れた通り、Airbyteにはセルフホスト(OSS)とマネージド(Cloud)の選択肢があります。2024年以降、Airbyte Cloudは「クレジット制」の料金体系を採用しており、同期する行数(Records)ではなく、データの転送ボリュームや計算リソースに基づく課金へとシフトしています。大規模なデータ同期を行う場合、OSS版ではメンテナンスコストが増大するため、以下の比較を参考にしてください。
| 検討要素 | Airbyte OSS (セルフホスト) | Airbyte Cloud (マネージド) |
|---|---|---|
| サーバー管理 | 自社(Docker/K8s)での構築・更新が必要 | 不要(Airbyte社が運用) |
| 初期費用 | 0円(インフラ代のみ) | 14日間のフリートライアルあり |
| API連携制限 | 自社サーバーのIP制限等に依存 | 固定IP(Egress IP)の利用が可能 |
| 最新ドキュメント | Airbyte Documentation (Official) | |
BigQuery側のコストとパフォーマンス最適化
AirbyteからBigQueryへロードする際、何も設定せずにデータを流し込むと、クエリコストの増大やスキャン効率の低下を招きます。構築時には必ず以下の2点を確認してください。
- リージョンの一致: Airbyteのコネクタ設定で指定するデータセットのロケーションと、他の分析ツールが参照するリージョン(例:
asia-northeast1)を必ず一致させてください。 - パーティショニング: 大量のログデータを扱う場合、BigQuery側で「取り込み時間パーティション」や「日付カラムによるパーティション」を設定することで、フルスキャンを回避し、分析コストを劇的に抑えられます。
Airbyteでロードされたデータは、多くの場合「JSON形式のrawデータ」として格納されます。これをSQLで分析可能なテーブルに変換するために、dbt(data build tool)との連携が推奨されます。Airbyte Cloudではdbt Cloudとの統合機能も提供されており、EL(抽出・ロード)後のT(変換)までをシームレスに自動化することが可能です。
データ基盤の構築は、単なるツールの接続ではなく「ビジネス要件に合わせたデータの整形」がゴールです。例えば、モダンなデータ基盤を構築し、高額な専用ツールに頼らずにCRMを運用する設計については、以下の記事が参考になります。
💡 関連:高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
AirbyteおよびGoogle Cloudの仕様、料金プランは頻繁にアップデートされます。導入時には必ず BigQuery 料金表 および Airbyte Pricing をご確認ください。
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
Airbyte × BigQuery 推奨運用
| 項目 | 推奨設定 |
|---|---|
| デプロイ | Airbyte Cloud(マネージド) / セルフホスト |
| ロード方式 | Incremental + CDC |
| 同期頻度 | 業務クリティカル= hourly / その他= daily |
| 変換 | dbt Cloud / Core |
| 監視 | Slack通知 + Cloud Monitoring |
Airbyte vs Fivetran vs trocco
- Airbyte: OSSで自社拡張可能・コネクタ自作可能
- Fivetran: マネージド最強・運用負荷ゼロだが高価
- trocco: 国産・日本語サポート・国内SaaS強い
FAQ
- Q1. セルフホストの最低スペックは?
- A. 4vCPU / 8GB メモリ / 100GBストレージから開始可能。
- Q2. 中小企業に Airbyte は早い?
- A. エンジニア在籍なら有用。それ以外は trocco / Fivetran 推奨。
関連記事
- 【BigQuery×BI連携】(ID 243)
- 【dbt×BigQueryデータ信頼性】(ID 372)
- 【Fivetran×Snowflake DXロードマップ】(ID 376)
- 【DWH構築実践ガイド】(ID 276)
※ 2026年5月時点の市場動向を反映。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
業界別 基幹システム刷新【完全ガイド】
本記事に関連する業界の基幹システム刷新ガイドはこちらです。業界特有の業務要件・主要プレイヤー・移行アプローチを解説しています。
Salesforce Agentforce 完全攻略シリーズ
Salesforce Agentforce の事前準備・データ接続・KPI・プロンプト設計までフェーズ別に深掘りした完全ガイドです。
- Agentforce導入成功の鍵!決めるべき5つの事前準備(ユースケース・データ・権限・ガバナンス・体制)
- AgentforceでCSATを最大化する戦略:ナレッジ検索、AI回答、シームレスなエスカレーション設計
- Agentforce×ナレッジベース整備:RAG精度を最大化するコンテンツ設計チェックリスト【Aurant Technologies独自】
- Agentforce導入企業の必読!情報漏洩を防ぐ権限・監査ログ設計とガバナンス実装
- Agentforceで失敗しない!自動化できる業務・できない業務の見極め方と導入戦略
- Agentforceの品質KPI:正答率を超え、有用性・安全性・工数削減でビジネス成果を最大化する評価戦略
- Agentforceの真価を引き出すデータ接続設計:Salesforceレコード・ナレッジ・DWHの使い分けと連携パターンを徹底解説
- Agentforceプロンプト設計入門:トーン&マナー・禁止事項・引き継ぎ文でAIエージェントをビジネスの力に変える
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】Salesforce 完全ガイド:CRM/SFA/MA/CDP/Agentforce の使い分けと統合設計、業界別実装パターン
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
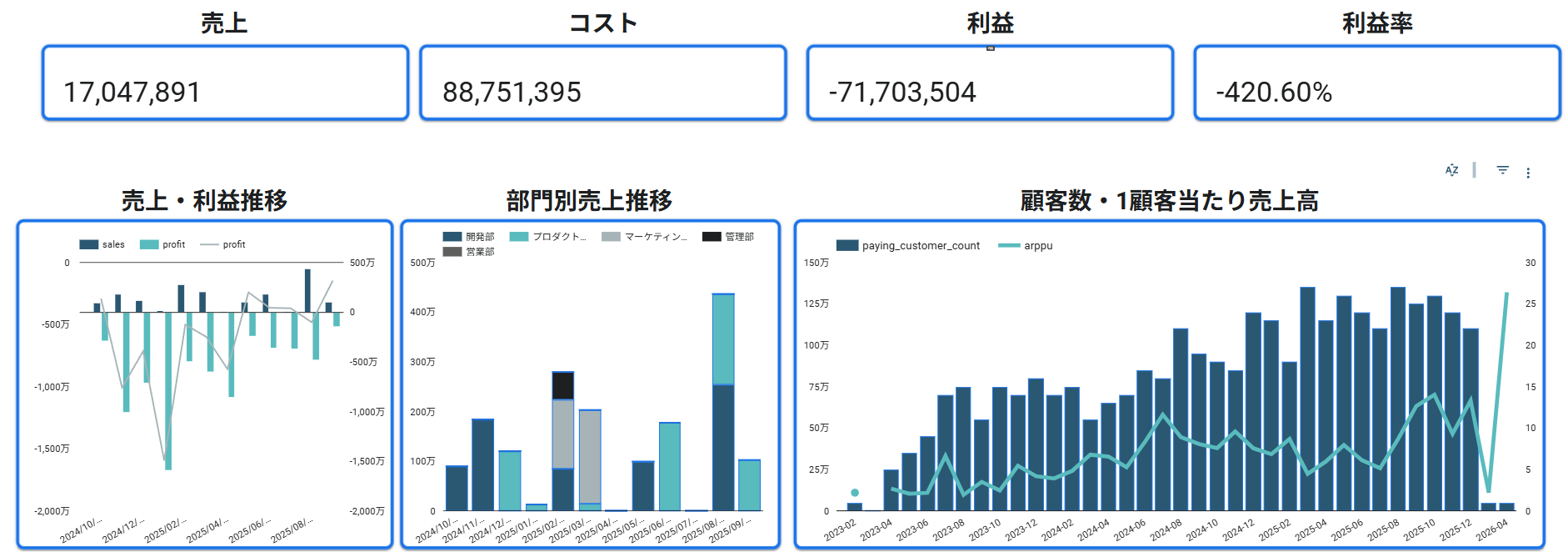
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。