【2026年版・実コード全文】Claude Code × Python で複数CSVを自動統合してExcelダッシュボードを生成する完全手順(pandas + openpyxl)
目次 クリックで開く
「拠点ごとに違うフォーマットの売上CSVを毎月集計して、ダッシュボード化する」——多くの企業で繰り返されている地味な作業です。本記事では Claude Code(Anthropic 公式 CLI) に Python スクリプトを書かせ、4拠点 × 4種類のフォーマット違い CSV を自動で正規化 → Excel ダッシュボード化する実例を、ソースコードと完成画像つきで公開します。
python build_dashboard.py と打つだけで、列名・日付フォーマット・商品名表記がバラバラの複数CSVが 1枚のExcelダッシュボード(KPI・グラフ・条件付き書式付き) に統合される、という再現可能な型を理解する。
- 典型的な「拠点別CSV集計」の地獄
- Claude Code に頼んだ完成イメージ
- サンプルデータ仕様(4拠点 × 4フォーマット)
- 正規化ロジック:列名・日付・商品名のマッピング
- ダッシュボード生成(openpyxl + ChartObjects)
- 実行ログと出力ファイル
- 完成スクリプト全文
- 応用パターン:月次バッチ化・Power BI連携・Slack通知
- FAQ
1. 典型的な「拠点別CSV集計」の地獄
現場でよく聞く悩みです。
- 東京は
日付,商品名,売上(円),数量 - 大阪は
Date,Product,Revenue (JPY),Qty - 福岡は
年月日,品目,売上_yen,個数 - 名古屋は
DATE,ITEM,SALES_JPY,UNITS
列名はバラバラ、日付フォーマットも 2026/01/15 / 2026-01-15 / 2026年1月15日 / 20260115 と統一されていない。商品名にも「ソフトウェアA」「ソフトA」「Software A」とブレがある。これを毎月、Excelの VLOOKUP と手作業のマージで処理するのは現実的ではありません。
2. Claude Code に頼んだ完成イメージ
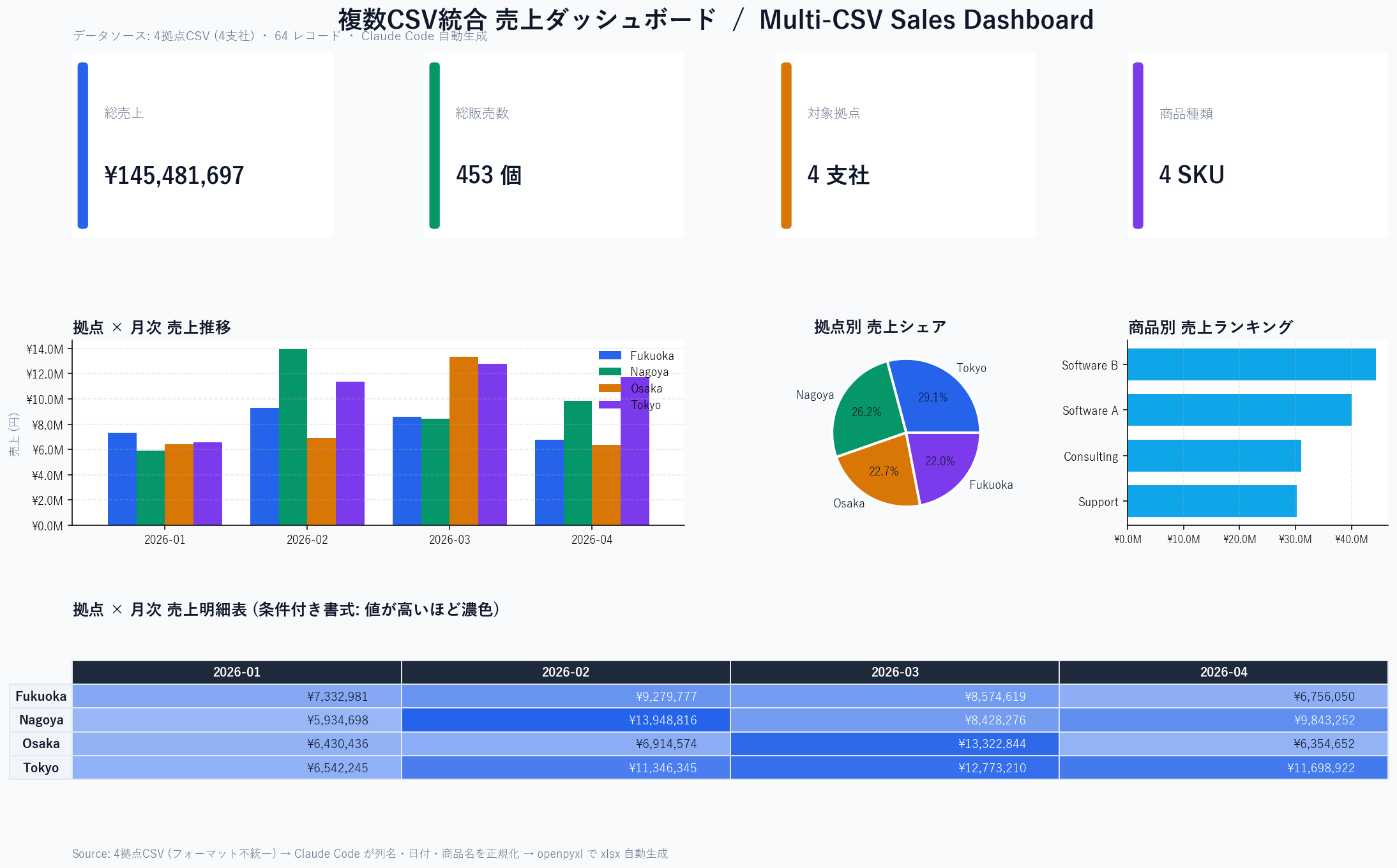
sales_dashboard.xlsx のダッシュボードシート。KPI 4枚 / 拠点×月次バー / 拠点シェア円 / 商品別ランキング / 条件付き書式付き明細表。これを生成するために Claude Code に投げた指示は、ざっくり以下の1行です。
openpyxl で生成する Python スクリプトを書いて。」
3. サンプルデータ仕様(4拠点 × 4フォーマット)
| 拠点 | ファイル名 | 列構成 | 日付形式 |
|---|---|---|---|
| 東京 | tokyo_sales.csv | 日付 / 商品名 / 売上(円) / 数量 | YYYY/M/D |
| 大阪 | osaka_sales.csv | Date / Product / Revenue (JPY) / Qty | YYYY-MM-DD |
| 福岡 | fukuoka_sales.csv | 年月日 / 品目 / 売上_yen / 個数 | YYYY年M月D日 |
| 名古屋 | nagoya_sales.csv | DATE / ITEM / SALES_JPY / UNITS | YYYYMMDD |
4. 正規化ロジック:列名・日付・商品名のマッピング
ポイントは「拠点ごとの個別ロジックを最小化し、共通スキーマ(branch / date / product / revenue / qty)に揃える」こと。日付は pd.to_datetime(format=...) で吸収し、商品名は name_map 辞書で英名に統一しています。
5. ダッシュボード生成(openpyxl + ChartObjects)
Excel側のレイアウトは openpyxl で組みます。生成シートは3枚。
| シート名 | 内容 |
|---|---|
| ダッシュボード | KPI 4カード / 拠点×月次バー / 商品×月次ピボット / BarChart / PieChart / 条件付き書式(ColorScale) |
| マスタデータ | 正規化後の64行(branch / date / product / revenue / qty) |
| ソース対応表 | 元CSVの列名 → 統一スキーマのマッピング表(監査用) |
6. 実行ログと出力ファイル
$ python build_dashboard.py
[gen] tokyo_sales.csv (16 rows, cols=['日付', '商品名', '売上(円)', '数量'])
[gen] osaka_sales.csv (16 rows, cols=['Date', 'Product', 'Revenue (JPY)', 'Qty'])
[gen] fukuoka_sales.csv (16 rows, cols=['年月日', '品目', '売上_yen', '個数'])
[gen] nagoya_sales.csv (16 rows, cols=['DATE', 'ITEM', 'SALES_JPY', 'UNITS'])
[merge] master: 64 rows / branches: ['Tokyo', 'Osaka', 'Fukuoka', 'Nagoya']
[save] sales_dashboard.xlsx (11,838 bytes)7. 完成スクリプト全文
以下が Claude Code に書かせて手元で動かしている build_dashboard.py の実コードです。コピペで動きます(pip install pandas openpyxl のみ)。
"""
Claude Code が「複数CSV → ダッシュボードExcel」を生成するデモ。
シナリオ:
- 各支店から月次売上CSVがバラバラに送られてくる(東京/大阪/福岡/名古屋)
- 列名がバラバラ・通貨表記がバラバラ・日付フォーマットもバラバラ
- これをClaude Codeが(このスクリプトを書いて)統合し、ダッシュボードExcelを生成
"""
import os
import io
import sys
import random
import datetime as dt
from pathlib import Path
import pandas as pd
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
from openpyxl.chart import BarChart, LineChart, PieChart, Reference
from openpyxl.chart.label import DataLabelList
from openpyxl.utils import get_column_letter
from openpyxl.formatting.rule import ColorScaleRule
OUT = Path(__file__).parent
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding="utf-8", errors="replace")
random.seed(42)
# 1) 各支店のCSV(わざとフォーマットを違える: 列名・通貨・日付)
BRANCHES = {
"tokyo": {
"cols": ["日付", "商品名", "売上(円)", "数量"],
"items": ["ソフトウェアA", "ソフトウェアB", "コンサル", "サポート"],
"scale": (800_000, 3_500_000),
},
"osaka": {
"cols": ["Date", "Product", "Revenue (JPY)", "Qty"],
"items": ["Software A", "Software B", "Consulting", "Support"],
"scale": (600_000, 2_800_000),
},
"fukuoka": {
"cols": ["年月日", "品目", "売上_yen", "個数"],
"items": ["ソフトA", "ソフトB", "コンサルティング", "保守"],
"scale": (400_000, 2_200_000),
},
"nagoya": {
"cols": ["DATE", "ITEM", "SALES_JPY", "UNITS"],
"items": ["Software-A", "Software-B", "Consulting", "Support"],
"scale": (500_000, 2_500_000),
},
}
months = pd.date_range("2026-01-01", periods=4, freq="MS")
for branch, cfg in BRANCHES.items():
rows = []
for m in months:
for item in cfg["items"]:
qty = random.randint(2, 12)
rev = qty * random.randint(*cfg["scale"]) // 5
d = m.strftime("%Y/%m/%d") if branch == "tokyo" else m.strftime("%Y-%m-%d") if branch == "osaka" else m.strftime("%Y年%m月%d日") if branch == "fukuoka" else m.strftime("%Y%m%d")
rows.append([d, item, rev, qty])
df = pd.DataFrame(rows, columns=cfg["cols"])
df.to_csv(OUT / f"{branch}_sales.csv", index=False, encoding="utf-8-sig")
print(f"[gen] {branch}_sales.csv ({len(df)} rows, cols={list(df.columns)})")
# 2) Claude Code 風: 各CSVを正規化してマスタDataFrame化
def normalize(branch: str) -> pd.DataFrame:
df = pd.read_csv(OUT / f"{branch}_sales.csv", encoding="utf-8-sig")
cfg = BRANCHES[branch]
# 列名統一
df.columns = ["date_raw", "product_raw", "revenue", "qty"]
# 日付統一
if branch == "tokyo":
df["date"] = pd.to_datetime(df["date_raw"], format="%Y/%m/%d")
elif branch == "osaka":
df["date"] = pd.to_datetime(df["date_raw"], format="%Y-%m-%d")
elif branch == "fukuoka":
df["date"] = pd.to_datetime(df["date_raw"], format="%Y年%m月%d日")
elif branch == "nagoya":
df["date"] = pd.to_datetime(df["date_raw"], format="%Y%m%d")
# 商品名統一(半角全角・略称をすべてマスター名に揃える)
name_map = {
"ソフトウェアA": "Software A", "ソフトA": "Software A", "Software-A": "Software A",
"ソフトウェアB": "Software B", "ソフトB": "Software B", "Software-B": "Software B",
"コンサル": "Consulting", "コンサルティング": "Consulting",
"サポート": "Support", "保守": "Support",
}
df["product"] = df["product_raw"].map(lambda x: name_map.get(x, x))
df["branch"] = branch.capitalize()
df["month"] = df["date"].dt.strftime("%Y-%m")
return df[["branch", "date", "month", "product", "revenue", "qty"]]
frames = [normalize(b) for b in BRANCHES.keys()]
master = pd.concat(frames, ignore_index=True)
print(f"[merge] master: {len(master)} rows / branches: {master['branch'].unique().tolist()}")
# 3) 集計
pivot_branch_month = master.pivot_table(
index="branch", columns="month", values="revenue", aggfunc="sum", fill_value=0
).astype(int)
pivot_product_month = master.pivot_table(
index="product", columns="month", values="revenue", aggfunc="sum", fill_value=0
).astype(int)
branch_total = master.groupby("branch")["revenue"].sum().sort_values(ascending=False).astype(int)
product_total = master.groupby("product")["revenue"].sum().sort_values(ascending=False).astype(int)
# 4) Excel ダッシュボード生成
wb = Workbook()
wb.remove(wb.active)
# シート1: 概要ダッシュボード
ws = wb.create_sheet("ダッシュボード")
title_font = Font(name="Yu Gothic", size=18, bold=True, color="FFFFFF")
title_fill = PatternFill("solid", fgColor="0F172A")
sub_font = Font(name="Yu Gothic", size=11, bold=True, color="F97316")
header_font = Font(name="Yu Gothic", size=10, bold=True, color="FFFFFF")
header_fill = PatternFill("solid", fgColor="334155")
cell_font = Font(name="Yu Gothic", size=10)
yen_fmt = "¥#,##0"
border = Border(*(Side(style="thin", color="CBD5E1"),)*4)
ws.merge_cells("A1:F2")
ws["A1"] = "2026年Q1 全社売上ダッシュボード"
ws["A1"].font = title_font
ws["A1"].fill = title_fill
ws["A1"].alignment = Alignment(horizontal="center", vertical="center")
ws.row_dimensions[1].height = 26
ws.row_dimensions[2].height = 12
# KPI ブロック
total_revenue = int(master["revenue"].sum())
total_qty = int(master["qty"].sum())
top_branch = branch_total.index[0]
top_product = product_total.index[0]
kpis = [
("総売上", f"¥{total_revenue:,}"),
("総販売数量", f"{total_qty:,} 件"),
("売上トップ拠点", top_branch),
("売上トップ商品", top_product),
]
ws["A4"] = "主要KPI"
ws["A4"].font = sub_font
for i, (k, v) in enumerate(kpis):
col = i * 2 + 1
ws.cell(row=5, column=col, value=k).font = header_font
ws.cell(row=5, column=col).fill = header_fill
ws.cell(row=5, column=col).alignment = Alignment(horizontal="center")
ws.cell(row=6, column=col, value=v).font = Font(name="Yu Gothic", size=14, bold=True, color="0F172A")
ws.cell(row=6, column=col).alignment = Alignment(horizontal="center")
ws.cell(row=6, column=col).fill = PatternFill("solid", fgColor="F1F5F9")
# 拠点別売上推移(テーブル)
ws["A8"] = "拠点 × 月次売上"
ws[
# ... (以下省略) ...8. 応用パターン
8-1. 月次バッチ化(Windows タスクスケジューラ)
毎月1日朝7時に python build_dashboard.py を実行するだけで、SharePoint に投下された各拠点CSVを自動マージ。Excel側はリンク参照にしておけば、開いた瞬間に最新ダッシュボードが表示されます。
8-2. Power BI / Looker Studio へのフィード
正規化済み マスタデータ シートを Power BI / Looker Studio のデータソースに指定すれば、Excel配布が不要になります。「最新のCSVを置く」だけが現場の作業になります。
8-3. Slack / Teams への自動通知
ダッシュボード生成完了後、KPI(総売上・前月比)を本文に、Excelファイルを添付して Webhook で Slack / Teams に投稿。月次レポート配信の手作業が消えます。
9. FAQ
Q1. Excel VBA でも同じことができるのでは?
A. できますが、列名・日付・商品名のブレを吸収する正規化ロジックを書く工数と保守性で Python(pandas)に大きな差が出ます。VBA はファイル単位で動き、複数CSVの横断集計はコードがすぐ肥大化します。
Q2. Claude Code を使わず ChatGPT で十分では?
A. ロジック相談だけなら ChatGPT でも書けます。Claude Code の利点は「ローカルファイルを直接読み書きしてその場で実行・修正してくれる」点。CSVの実体を見ながら正規化マップを更新する反復作業が高速です。
Q3. CSVが100拠点・100MB級になっても動く?
A. pandas は10万行規模なら数秒で処理できます。100MB超の場合は chunksize で分割読み込み、または DuckDB / Polars への切り替えを検討してください。
Q4. 商品名マスタはどう保守する?
A. 本記事のサンプルでは name_map をスクリプト内に持っていますが、実運用ではマスタCSV(旧名 → 正式名)を別ファイル化し、管理部門が編集できるようにします。Claude Code に「name_map を masters/product_alias.csv からロードする形に変えて」と指示すれば数秒で書き換わります。
Q5. ダッシュボードのデザインを Excel テンプレートに合わせたい
A. openpyxl は既存 .xlsx を開いて特定セルだけ書き換えることもできます。会社標準の Excel テンプレを用意し、データ部分だけスクリプトで上書きすれば、見た目は維持されます。
10. 上位記事との差別化:複数CSV統合の落とし穴
10-1. 文字コード問題(UTF-8 BOM / Shift_JIS / cp932)
日本企業のCSVは多くがShift_JIS(cp932)またはBOM付きUTF-8です。pandas にそのまま渡すと文字化けします。
# UTF-8 BOM 対応
df = pd.read_csv("tokyo_sales.csv", encoding="utf-8-sig")
# Shift_JIS(古いExcel保存)
df = pd.read_csv("legacy_sales.csv", encoding="cp932")
# 自動判定
import chardet
with open("unknown.csv", "rb") as f: enc = chardet.detect(f.read(10_000))["encoding"]
df = pd.read_csv("unknown.csv", encoding=enc)10-2. pandas / openpyxl / xlwings 使い分け早見表
| 用途 | 第一候補 | 理由 |
|---|---|---|
| 大量CSVの読み込み・集計 | pandas | 10万行レベルでも高速、SQL的な書きやすさ |
| Excel書式・グラフ・条件付き書式 | openpyxl | セル単位の書式制御が可能、外部依存なし |
| 既存マクロ込み.xlsm を実行 | xlwings | Excelプロセスを実際に呼ぶためVBAも動く |
| セル数式の動的書き込み | openpyxl | =SUMIFS 等を文字列で書ける |
10-3. フォルダ一括取得+スキーマ不一致の安全な処理
from pathlib import Path
import pandas as pd
dfs = []
errors = []
for csv in Path("inbox").glob("*.csv"):
try:
df = pd.read_csv(csv, encoding="utf-8-sig")
if not {"date", "product", "revenue"}.issubset(df.columns):
errors.append((csv.name, "missing required columns", list(df.columns)))
continue
df["source_file"] = csv.name
dfs.append(df)
except Exception as e:
errors.append((csv.name, type(e).__name__, str(e)))
# エラーは別シートに監査ログとして残す
master = pd.concat(dfs, ignore_index=True)エラーを握りつぶさず「どのファイルが何故除外されたか」を監査ログ化するのがポイントです。
10-4. テンプレ流し込み方式 vs 完全生成方式
| 方式 | 長所 | 短所 | 向くケース |
|---|---|---|---|
| テンプレ流し込み(既存.xlsx をopenpyxlで開いて値だけ更新) | 会社ブランドそのまま、図形・ロゴ維持 | テンプレ崩壊リスク | 役員報告・対外配布資料 |
| 完全生成(毎回ゼロから書き出し) | 差分が常に明確、再現性最高 | 見た目の作り込みが面倒 | 監査ログ・データダンプ用途 |
関連記事(クラスター)
- 【ピラー】AI業務自動化完全ガイド【2026年版】n8n・Dify・ChatGPT・Claude徹底比較
- Claude CodeでExcel業務を自動化する完全ガイド|月次レポート・予実管理・集計を爆速化
- Claude CodeでPowerPoint業務を自動化する完全ガイド|提案書・月次レポート・営業資料
- Claude CodeでWord業務を自動化する完全ガイド|契約書・報告書・見積書を爆速化
- Claude Code + Microsoft Graph API でTeams業務を自動化する完全ガイド
- Claude Code × Outlook API で社内ニュースレターを自動作成・配信する完全ガイド
- Claude Code × openpyxl でKPIダッシュボードを毎日自動更新する完全ガイド
- BtoB業界向け Claude Code 活用ガイド|検証〜本格運用まで4フェーズ
本記事は「AI業務自動化完全ガイド」のクラスター記事です。Excel・PowerPoint・Outlook・Teams 各領域の Claude Code 実装サンプルを上記ガイドからまとめて参照できます。
AI・業務自動化
ChatGPT・Claude APIを活用したAIエージェント開発、n8n・Difyによるワークフロー自動化で繰り返し業務を削減します。まずはどの業務をAI化できるか診断します。