高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
目次 クリックで開く
高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」ツール選定と公式事例
最終更新日:2026年4月7日 ※本記事は、WebトラッキングデータをSalesforce(CRM)等に同期させるデータ基盤を、高額なパッケージ製品に依存せず、安価かつスケーラブルに構築するためのアーキテクチャの裏側を網羅的に解説しています。
こんにちは。Aurant Technologiesの近藤義仁です。
前回の記事では、Webトラッキングと「CookieとCRM IDの紐付け(名寄せ)」のシステムの裏側を解説しました。これを実装しようとした時、多くの企業がTreasure DataやSalesforce Data Cloud、KARTE Datahubといった「オールインワンのCDP(カスタマーデータプラットフォーム)」の導入をベンダーから提案されます。
確かに多機能ですが、初期費用や月額数百万円のランニングコストがかかり、自社のデータ量や運用体制と見合わない(ROIが合わない)ケースが後を絶ちません。
本日は、巨大なパッケージ製品にシステムを丸投げするのではなく、GCPやAWSを中心とした専門ツール群をAPIで繋ぎ合わせ、自社専用のデータ統合基盤を安価に構築する「コンポーザブルCDP(モダンデータスタック)」の設計思想と、実務的なツール選定の基準を解説します。
1. 徹底比較:「オールインワン」vs「コンポーザブル(MDS)」
データを収集し、名寄せを行い、SalesforceやMAツールへ同期する。このパイプラインを構築するアプローチは、現在大きく2つの陣営に分かれています。オールインワンCDP陣営の構造的課題
代表的なツール:Treasure Data、Tealium、Salesforce Data Cloud など
これらは「すべての機能が一つの箱に入っている」製品です。大規模なグローバル企業等には向いていますが、「高額なランニングコスト」「ベンダーロックイン」「独自のクエリ仕様による学習コスト」といった課題を抱えています。
最大のデメリットは「データグラビティ(データの重力)」です。一度CDP内にデータを貯め込み、独自のモデリングを構築してしまうと、他のシステムへの移行が極めて困難になります。また、既に社内でGCP等を利用している場合、CDP側にも同じデータをコピーすることになり、二重管理(二重課金)が発生します。
コンポーザブルCDP(モダンデータスタック:MDS)の優位性
現代のデータエンジニアリングの世界的標準です。自社のクラウド(BigQuery等)をハブとし、そこに「収集」「変換」「同期」に特化したSaaSをブロックのように組み合わせて構築します。
| 比較項目 | オールインワンCDP | コンポーザブルCDP(MDS)※推奨 |
|---|---|---|
| データの保存場所 | SaaSベンダー側のサーバー(ロックインされる) | 自社のクラウド環境(完全なコントロール権) |
| コスト構造 | 初期費用 + 高額な固定月額(機能・レコード数に応じる) | クラウドのストレージと計算リソースに応じた従量課金(安価) |
| データ処理の柔軟性 | ベンダー独自のクエリ仕様や画面操作に依存する | 標準的なSQL(dbt等)で自由にデータモデルを構築可能 |
| 拡張・リプレイス | システム全体の入れ替えが必要でリスク大 | 特定の要件が変わっても、該当ツールの差し替えだけで済む |
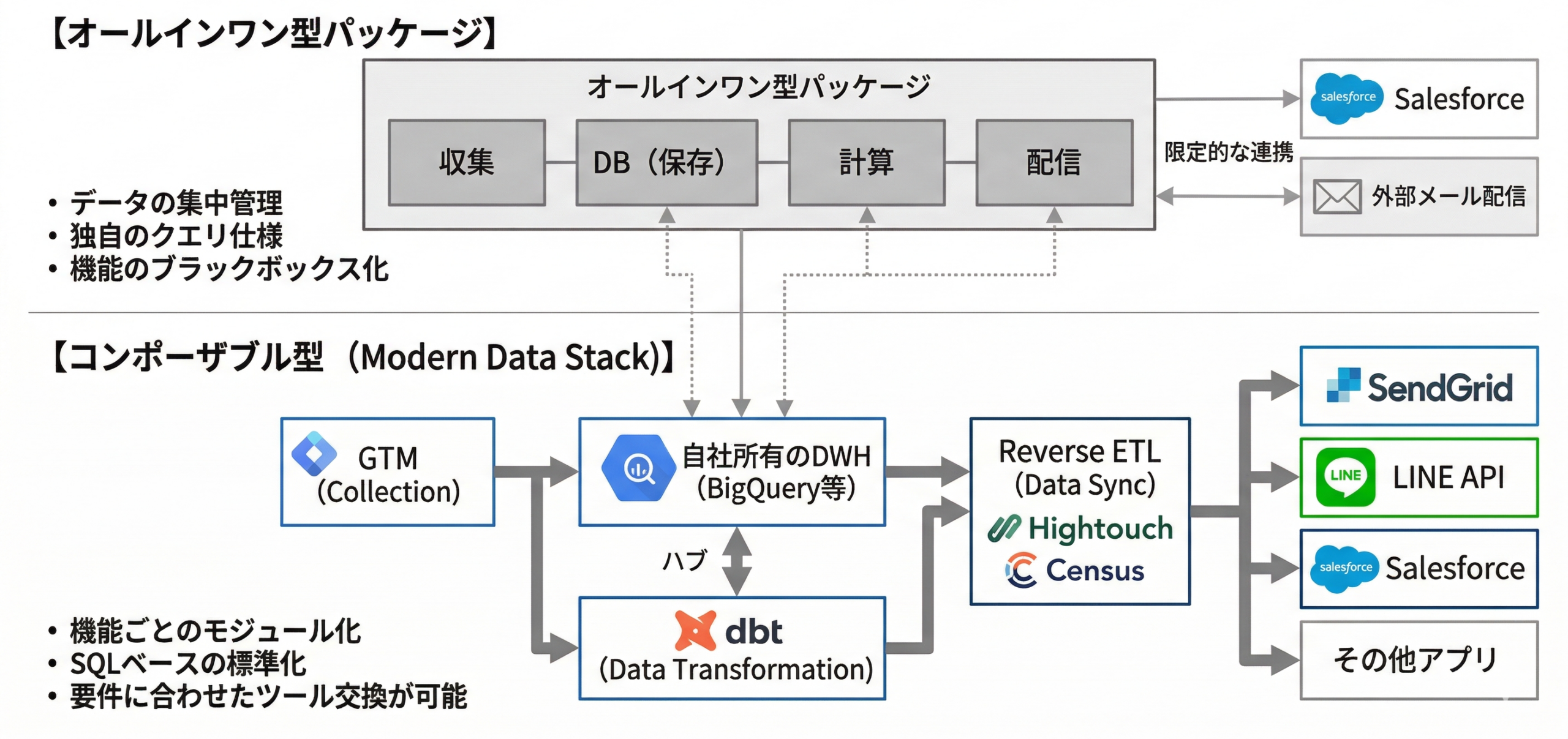
2. プロが選定するデータパイプラインの構成ツール(全4工程)
それでは、Web行動ログの収集からSalesforceへの同期までを、実務において何のツールを使って構築するのか、工程別に明確な選定基準を解説します。工程①:データ収集(トラッキング)
Web上のユーザー行動を検知し、裏側のデータベースへ送信する工程です。
- GTM / サーバーサイドGTM
- GA4 (Google Analytics 4)
【設計の詳細】
GA4の「BigQueryへの無料エクスポート機能」を活用するのが業界のベストプラクティスです。サーバーサイドGTM(sGTM)を併用してHTTPヘッダ経由のCookieを発行し、ITP規制を回避するセキュアなトラッキングを実現します。
工程②:データ蓄積(DWH・データレイク)
数千万〜数億件の行動ログを安価に保存し、高速にSQL集計できる「ハブ」となる工程です。
- Google Cloud BigQuery (圧倒的推奨)
- Snowflake / Amazon Redshift
【設計の詳細】
BigQueryはサーバーのインフラ管理が不要(サーバーレス)であり、使った分だけの従量課金です。テラバイト級のデータを保存しても月額数千円〜数万円に収まることが多く、Salesforceに全ログを保存するのに比べ圧倒的に安価です。
工程③:データ変換(名寄せ・モデリング)
BigQuery内に溜まった「匿名のCookie」と「CRMの実名ID」を結合(JOIN)し、「過去7日のログイン回数」などのスコアを計算する工程です。
- dbt (data build tool)
【設計の詳細】
BigQueryのスケジュールクエリ単体で運用すると、SQLの依存関係が複雑化し「スパゲッティ化」します。dbtを導入することで、SQLコードのバージョン管理(Git連携)、テストの自動化、データリネージの可視化が可能になり、データモデルの品質を担保できます。
工程④:データ同期(リバースETL)
計算されたスコアやフラグを、Salesforce等のCRMへ自動的に書き戻す工程です。
- Hightouch / Census (大規模向け)
- Make (Integromat) (小〜中規模向け・iPaaS)
【設計の詳細】
自前でPython等を使ってSalesforceのAPIを叩くバッチ処理を開発すると、APIの制限(Rate Limit)やエラーハンドリングの保守工数が甚大になります。Hightouchなどの「リバースETLツール」を利用すれば、BigQueryのテーブルとSalesforceの項目をUI上でマッピングするだけで、差分同期をノーコードで安全に実行してくれます。
💡 アーキテクトのインサイト:なぜ「リバースETL」が画期的なのか?
これまでのシステム構築では、計算結果をSalesforceに反映させるために「自前で連携プログラムを書く」必要がありました。Hightouch等のリバースETLツールは、DWHとSaaSの間に立ち、SQLを書くだけで「どのデータを、SaaSのどの項目に同期するか」を管理してくれます。このツールの台頭により、高額なCDPを買わずとも、データ基盤からCRMへの「ラストワンマイル」が容易に開通するようになりました。
公式リファレンス:リバースETLの概念(Hightouch)
Hightouchは、データウェアハウス(BigQueryやSnowflake)を組織の中心的なデータソース(Single Source of Truth)として扱い、そこからSalesforceやMarketoなどのビジネスツールへデータを同期する「リバースETL」のパイオニアです。
(出典:Hightouch Blog – What is Reverse ETL?)
3. モダンデータスタック(MDS)導入の公式成功事例
実際にコンポーザブルな構成を採用し、ビジネス成果を上げている企業の事例をご紹介します。米国 Lucid社:Salesforceへの営業インサイト提供
課題: 営業部門が、顧客の製品利用状況(誰がどの機能をどれくらい使っているか)を把握できず、アップセルの機会を逃していた。
解決策(MDSの導入): DWH(Snowflake)に集約された製品の利用ログを、リバースETL(Hightouch)を用いてSalesforceへ直接同期するアーキテクチャを構築。自前でのAPI連携開発を廃止した。
成果: 営業担当者はSalesforceの画面を見るだけで「製品をアクティブに利用している顧客(PQL)」を瞬時に把握できるようになり、営業効率が劇的に向上。開発チームはAPI連携の保守業務から解放された。
国内の潮流:データ基盤のコンポーザブル化
動向: 日本国内においても、株式会社10Xなどのデータ活用を推進するテック企業を中心に「BigQuery + dbt + リバースETL」の構成が標準化しつつあります。高額なCDPの導入を見送り、自社のGCPインフラを拡張することで、マーケティング部門だけでなく、経営企画・カスタマーサクセスといった全社横断的なデータ統合基盤として運用するケースが増加しています。
🔗 参考:dbt Labs Case Studies (Global & Japan)4. トラッキングからSalesforce連携までの全体データフロー
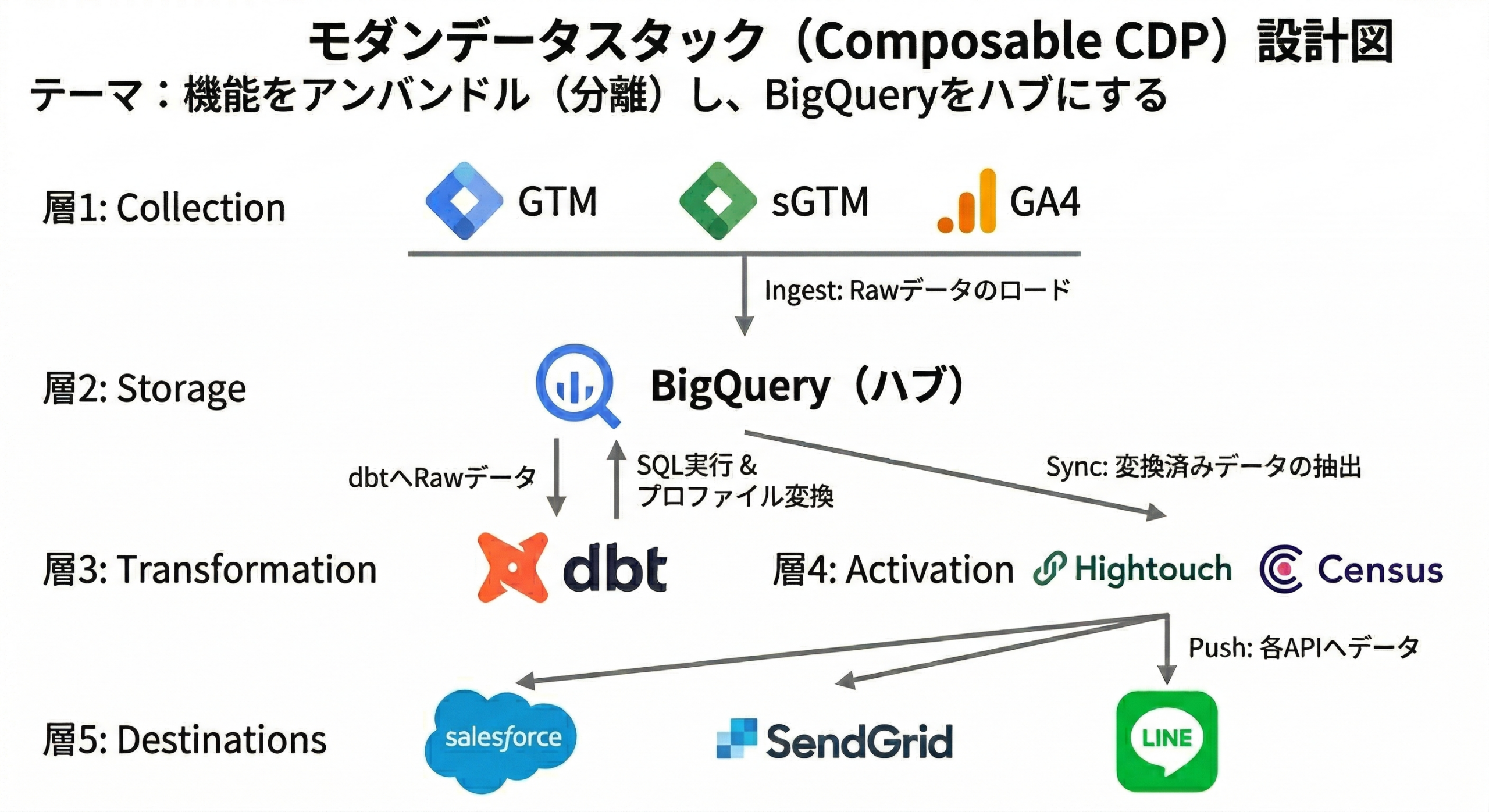
上記のツール群を組み合わせた、Web行動ログの取得からCRM連携に至るデータフローの全貌は以下のようになります。ユーザーがWebサイトで行動を起こした際、GTMがデータレイヤーの値を拾います。
GA4の標準エクスポート機能を利用します。
BigQuery内でSQLがスケジュール実行されます。
スコアの高いユーザーの情報を、現場の営業が使うシステムへ返します。
まとめ:システムの「機能」ではなく、データの「主導権」を握る
「顧客の行動を可視化するために、とりあえず有名なCDPを入れよう」とツール名から入るプロジェクトは、高い確率で運用が行き詰まります。巨大な箱の中身を使いこなせず、データの移行もできなくなるからです。 重要なのは、**「自社のトラッキング要件において、どこにデータを貯め、どうやってCRMに返すのか」**というデータパイプラインの設計図を自社でコントロールすることです。BigQueryを中心としたコンポーザブルな構成であれば、スモールスタートで構築を始め、事業の拡大に合わせて連携ツール(ブロック)を柔軟に差し替えていく運用が可能です。
- 「オールインワンCDPの更新見積もりが高すぎて、リプレイスを検討している」
- 「BigQueryにログは溜まっているが、名寄せができずSalesforceへ還元できていない」
- 「dbtやリバースETLを用いた、安価なデータ基盤の構築手法を知りたい」
【無料相談】貴社のデータ基盤、コストに見合っていますか?
既存のクラウドインフラを活かしたトラッキングとCRM連携を診断する「CX to Backoffice 構造診断」を実施中です。お問い合わせはこちら