生成AIの精度を最大化する「データ駆動型RAG」:正しい参照導線の構築とビジネス活用実践ガイド
生成AIの精度はプロンプトからデータ活用の時代へ。RAGで「正しい参照導線」を構築し、貴社独自のデータ資産を最大限に活用。AIを真のビジネスパートナーに変える実践ノウハウ。
目次 クリックで開く
生成AIの精度を最大化する「データ駆動型RAG」:正しい参照導線の構築とビジネス活用実践ガイド
生成AIの精度はプロンプトからデータ活用の時代へ。RAGで「正しい参照導線」を構築し、貴社独自のデータ資産を最大限に活用。AIを真のビジネスパートナーに変える実践ノウハウ。
生成AIの精度向上は「プロンプト」から「データ」の時代へ
生成AIは、現代ビジネスにおいて革新的なツールとして注目されています。しかし、その真価を引き出すためには、単に「良いプロンプト」を考えるだけでは不十分な時代に突入しています。初期の生成AI活用では、いかに的確な指示(プロンプト)を与えるかが重視されましたが、今やその焦点は、AIに学習・参照させる「データ」そのものへと移行しています。貴社が生成AIを最大限に活用し、競争優位を築くためには、このパラダイムシフトを理解し、適切な戦略を立てることが不可欠です。
プロンプトエンジニアリングの限界と企業データ活用の重要性
生成AIの登場初期、多くの企業や開発者は「プロンプトエンジニアリング」のスキル習得に注力しました。これは、AIモデルから望ましい出力を引き出すために、効果的な指示文や質問文を作成する技術です。確かに、シンプルなタスクや一般的な知識に基づく情報生成においては、プロンプトの質がAIの出力精度を大きく左右しました。
しかし、ビジネスの現場で生成AIを本格的に活用しようとすると、プロンプトエンジニアリングだけでは越えられない壁に直面します。その主な限界は以下の通りです。
- 専門知識の伝達困難性: 貴社固有の業界知識、製品詳細、顧客情報、社内規定といった専門的でニッチな情報は、プロンプトだけで正確かつ網羅的にAIに伝えることは非常に困難です。
- 出力の一貫性・信頼性: プロンプトのわずかな変更や、AIモデルの内部状態によって出力が変動しやすく、常に一貫した高品質な結果を得るのが困難です。特に、ハルシネーション(もっともらしいが事実ではない情報を生成すること)のリスクは、プロンプトだけでは完全には排除できません。
- 拡張性と保守性: 複雑な業務要件に対応するためには、プロンプト自体が非常に長大かつ複雑になりがちです。これにより、プロンプトの作成・管理・更新が属人化し、システム全体の拡張性や保守性が低下します。
- リアルタイム性・鮮度: プロンプトに最新情報を毎回盛り込むのは非現実的であり、AIモデルが学習した時点以降の新しい情報や、貴社内のリアルタイムなデータに基づいて回答させることはできません。
これらの限界を克服し、生成AIを真にビジネスに役立つツールへと進化させるためには、プロンプトだけでなく、貴社が保有する膨大な「企業データ」をAIに活用させることが不可欠です。私たちは、このデータ活用こそが、生成AIの精度向上とビジネス価値創出の鍵であると確信しています。
| 項目 | プロンプトエンジニアリング中心のアプローチ | データ活用(RAGなど)中心のアプローチ |
|---|---|---|
| 主な目的 | AIへの指示を明確化し、望む出力を引き出す | AIに企業固有の知識を与え、より正確で深い出力を実現する |
| 難易度 | 比較的容易に開始できるが、高度な出力には専門知識が必要 | 初期データ整備とシステム構築に手間がかかるが、一度構築すれば安定 |
| 拡張性 | プロンプトの複雑化に伴い管理が困難になる可能性 | データソースの追加・更新で柔軟に拡張可能 |
| 出力品質 | 汎用的だが、専門性や文脈に欠ける場合がある | 企業独自の専門性と文脈を反映し、高品質な出力を実現 |
| 信頼性 | ハルシネーションのリスクが高い | 参照元を明示でき、ハルシネーションを抑制しやすい |
| 競争優位 | 模倣されやすい、差別化が難しい | 独自のデータ資産が差別化要因となり、模倣が難しい |
なぜ「データ」が生成AIの出力品質を左右するのか
生成AIモデルは、インターネット上の膨大なテキストデータから学習しています。これにより、一般的な知識や常識に基づいた多様なテキスト生成が可能ですが、その知識はあくまで「汎用的」であり、特定の企業や業界の「深い専門性」や「最新情報」を網羅しているわけではありません。
ここで重要になるのが、「Retrieval Augmented Generation(RAG:検索拡張生成)」と呼ばれるアプローチです。RAGは、生成AIモデルが回答を生成する前に、外部の信頼できるデータソース(貴社の社内ドキュメント、データベース、CRMなど)から関連情報を「検索(Retrieval)」し、その情報を基に回答を「生成(Generation)」する技術です(出典:Meta AI, 2020年の論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」)。
この仕組みにより、AIは以下の点で出力品質を劇的に向上させます。
- 事実に基づいた正確性: 貴社の内部データや最新の一次情報を参照するため、AIが生成する情報がより正確になり、ハルシネーションのリスクを大幅に低減できます。例えば、顧客からの問い合わせに対して、貴社の最新の製品カタログやFAQを基に回答することで、誤った情報を提供するリスクを回避できます。
- 企業固有の専門性: 貴社が長年蓄積してきた専門知識やノウハウをAIに「与える」ことで、AIは貴社の文脈に完全に合致した、専門性の高い回答やコンテンツを生成できるようになります。これにより、競合他社には真似できない、貴社独自のAI活用が可能になります。
- 情報の鮮度と網羅性: 常に最新の社内データやリアルタイム情報をAIに参照させることで、モデルが学習した時点以降の情報も反映した、鮮度の高い回答を提供できます。これにより、変化の速いビジネス環境においても、常に最適な情報を提供できるようになります。
- 透明性と信頼性: RAGでは、AIがどの情報を参照して回答を生成したのか、その「根拠」を提示できるため、AIの出力に対する信頼性が向上します。これは、特に法務、医療、金融といった高度な正確性が求められる分野で極めて重要です。
要するに、AIの出力品質は、プロンプトの巧みさだけでなく、AIがアクセスできる「データの質と量」に直接的に依存するのです。質の高いデータをAIに「与える」ことで、AIは貴社にとって真の「専門家」となり、事業成長を加速させる強力なパートナーへと進化します。
企業独自の「データ資産」が競争優位の源泉となる理由
貴社が長年ビジネスを続ける中で蓄積してきたデータは、単なる情報ではなく、まさに「データ資産」と呼ぶべきものです。このデータ資産は、顧客との接点、製品開発、業務プロセス、マーケティング活動など、あらゆる側面で貴社独自の価値と競争優位性を生み出す源泉となります。特に生成AIの時代においては、このデータ資産の活用が、他社との差別化を決定づける要素となります。
貴社独自のデータ資産を活用することで、生成AIは以下の点で競争優位をもたらします。
- パーソナライズされた顧客体験の提供: 顧客の購買履歴、問い合わせ履歴、ウェブサイトでの行動データなどをAIに学習させることで、個々の顧客に最適化された提案、サポート、コンテンツを生成できます。これは、顧客満足度の向上とロイヤルティの強化に直結します。
- 業務プロセスの劇的な効率化: 過去の業務記録、プロジェクト管理データ、社内ナレッジベース、契約書テンプレートなどを活用することで、AIは定型業務の自動化、文書作成支援、意思決定支援などを高精度で行うことができます。これにより、従業員はより戦略的で創造的な業務に集中できるようになります。
- 革新的な製品・サービス開発の加速: 研究開発データ、市場調査レポート、顧客からのフィードバック、競合分析データなどをAIに分析させることで、新たな製品アイデアの創出、既存製品の改善点発見、市場トレンドの予測などが可能になります。
- 意思決定の質の向上: 貴社のビジネスデータ(売上データ、マーケティング効果、サプライチェーン情報など)をAIが分析し、洞察を提供することで、データに基づいた迅速かつ正確な意思決定を支援します。
これらのデータ資産は、外部からは容易にアクセスできない、貴社固有のものです。これを生成AIと組み合わせることで、貴社は他社には真似できない、独自の「インテリジェンス」をビジネスのあらゆる側面に埋め込むことができます。この「データ駆動型AI」のアプローチこそが、これからの時代における企業の競争力を決定づける重要な要素となるでしょう。
貴社が持つデータ資産の例としては、以下のようなものが挙げられます。
- 顧客管理システム(CRM)に蓄積された顧客情報、購買履歴、対応履歴
- 営業活動報告書、商談記録
- 製品マニュアル、仕様書、技術文書
- 社内FAQ、ナレッジベース、過去のプロジェクト報告書
- ウェブサイトのアクセスログ、コンテンツ閲覧履歴
- メールやチャットでの顧客とのコミュニケーション履歴
- 契約書、法務文書
- 研究開発の実験データ、論文
- 財務データ、市場調査レポート
これらのデータをいかに整理し、生成AIに「正しい参照導線」として提供できるかが、貴社のAI戦略成功の鍵を握ります。
生成AIの精度を飛躍させる「RAG(検索拡張生成)」とは
生成AIの導入が進む中で、「いかに正確で信頼性の高い情報を生成させるか」は多くの企業にとって喫緊の課題です。特に、社内データに基づいた回答や、常に最新の情報を反映したアウトプットが求められるBtoB領域では、その重要性はさらに高まります。ここでは、生成AIの精度を劇的に向上させる技術「RAG(Retrieval Augmented Generation:検索拡張生成)」について、その仕組みと貴社のビジネスにもたらす価値を詳しく解説します。
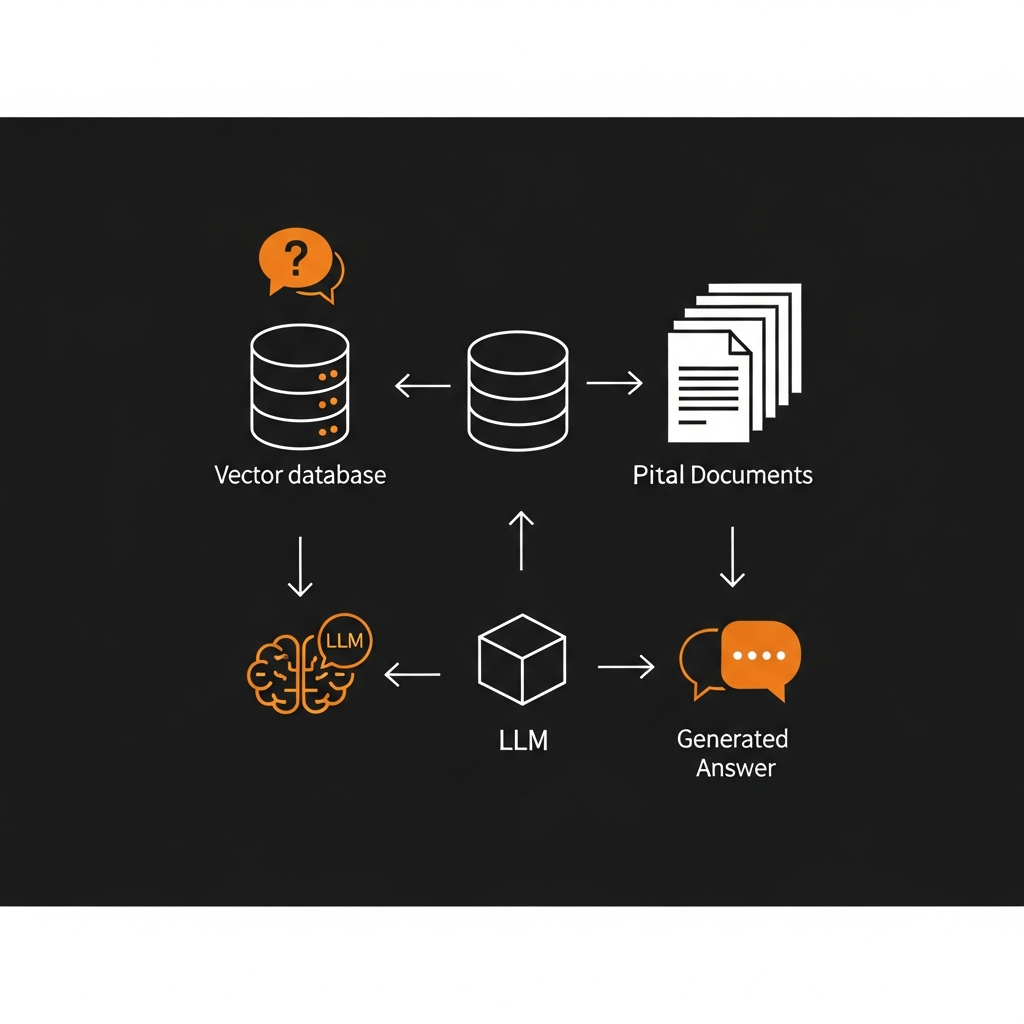
RAGの基本原理と仕組み:生成AIが「参照」するプロセス
RAGは、大規模言語モデル(LLM)が回答を生成する際に、事前に外部の知識ソースから関連情報を「検索」し、その情報を「参照」しながら回答を生成するフレームワークです。これにより、LLMが学習データのみに依存するのではなく、リアルタイムの情報や貴社が保有する内部データに基づいた、より正確で信頼性の高い回答を導き出すことが可能になります。
そのプロセスは大きく2つのフェーズに分かれます。
- 検索(Retrieval)フェーズ: ユーザーからの質問やプロンプトを受け取ると、まず貴社が保有するドキュメント、データベース、Webサイトなどから、質問に関連する情報が検索されます。この検索には、ベクトルデータベースやキーワード検索など、様々な技術が用いられます。
- 生成(Augmentation & Generation)フェーズ: 検索によって得られた関連情報が、プロンプトと合わせてLLMに与えられます。LLMはこの強化されたプロンプトに基づいて、参照情報を根拠とした回答を生成します。これにより、LLMは「知っていること」だけでなく、「参照できること」に基づいて回答を構築できるようになります。
この仕組みは、例えるなら、優秀なコンサルタントが貴社の質問に対し、その場で手持ちの資料やデータベースを調べて、根拠に基づいた回答を作成するプロセスに非常に似ています。
従来の生成AIとRAGを比較すると、その違いは明らかです。
| 項目 | 従来の生成AI(LLM単体) | RAG(検索拡張生成) |
|---|---|---|
| 情報源 | 学習済みデータセットのみ | 学習済みデータセット + 外部知識ソース(リアルタイム情報、社内データなど) |
| 情報鮮度 | 学習時点の情報に限定される | 外部知識ソースを更新することで常に最新情報を反映可能 |
| 回答の根拠 | 内部的な知識(学習データ) | 参照した外部知識ソースを明示可能 |
| ハルシネーション | 発生しやすい | 外部情報に基づき抑制される |
| カスタマイズ性 | 追加学習(ファインチューニング)が必要 | 外部知識ソースの追加・変更で柔軟に対応 |
RAGが解決する生成AIの課題(ハルシネーション、情報鮮度不足)
生成AIの導入を検討する多くの企業が直面する大きな課題が、いわゆる「ハルシネーション(幻覚)」と「情報鮮度不足」です。ハルシネーションとは、AIが事実に基づかない情報をあたかも真実のように生成してしまう現象を指します。例えば、一般的な課題として、ある金融機関が顧客向けFAQシステムに生成AIを導入した際、存在しない金融商品を説明したり、誤った金利情報を提示したりするリスクが懸念されることがあります。これは企業の信頼性を損なう重大な問題です。
また、生成AIの学習データは特定の時点のものであるため、それ以降に発生した最新情報や、貴社独自の社内規定、製品情報などは反映されません。ビジネス環境が常に変化するBtoB領域において、この情報鮮度不足は、営業資料の作成、顧客サポート、市場分析など、多岐にわたる業務で誤った判断や機会損失につながる可能性があります。
RAGはこれらの課題に対し、非常に有効な解決策を提供します。外部の信頼できる情報源を参照することで、LLMは根拠に基づいた回答を生成するようになり、ハルシネーションのリスクを大幅に低減します。実際に、Googleの調査によれば、RAGを適用することでLLMのハルシネーション発生率が最大80%削減されたという報告もあります(出典:Google Research)。さらに、参照する外部データベースを常に最新の状態に保つことで、生成AIはリアルタイムの情報を反映した回答を提供できるようになります。これにより、貴社独自のナレッジや最新の市場動向に基づいた、正確で信頼性の高いアウトプットが期待できます。
RAG導入によるビジネスメリット:信頼性と実用性の向上
RAGの導入は、単に生成AIの精度を高めるだけでなく、貴社のビジネスに多岐にわたる実用的なメリットをもたらします。
- 回答の信頼性向上: 外部情報源を参照することで、AIの回答に具体的な根拠が加わり、顧客や社内ユーザーからの信頼性が向上します。これにより、誤情報の拡散リスクを低減し、ブランドイメージを保護できます。
- 情報鮮度の確保: 最新の社内ドキュメントや公開情報をRAGの参照元として設定することで、常に最新の情報を反映した回答が得られます。特に、法規制の変更が多い業界や、製品アップデートが頻繁な企業にとって重要です。
- 専門知識の活用: 貴社が蓄積してきた専門的な知識やノウハウをRAGの参照データとして組み込むことで、汎用的なLLMでは得られなかった、貴社独自の価値ある情報生成が可能になります。例えば、製造業の企業では、過去の製品開発ドキュメントをRAGに連携させることで、技術的な質問に対してより深い洞察を含む回答を生成できるようになるでしょう。
- 開発・運用コストの最適化: LLM自体をファインチューニングするよりも、RAGの外部知識ベースを更新する方が一般的に容易で、コストも抑えられます。これにより、変化の速いビジネスニーズへの柔軟な対応が可能になります。
- 業務効率化と生産性向上: 営業担当者が顧客からの複雑な製品質問に即座に正確な回答を生成したり、カスタマーサポートがFAQシステムではカバーしきれないニッチな問い合わせに対応したりすることで、業務効率が大幅に向上します。これにより、従業員はより戦略的な業務に集中できるようになります。
これらのメリットは、特に以下のような業務領域で顕著に現れます。
| 業務領域 | RAG導入による具体的なメリット | 期待される効果 |
|---|---|---|
| カスタマーサポート | 最新の製品マニュアルやFAQ、過去の問い合わせ履歴に基づいた正確な回答 | 顧客満足度向上、オペレーターの対応時間短縮、コスト削減 |
| 営業・マーケティング | 最新の製品情報、競合分析、市場トレンドに基づいた提案資料作成、顧客向けQ&A生成 | 商談成功率向上、コンテンツ作成効率化、パーソナライズされた顧客体験提供 |
| 社内ナレッジマネジメント | 社内規定、技術ドキュメント、プロジェクト報告書などに基づいた情報検索・要約 | 従業員の情報アクセス性向上、オンボーディング効率化、ナレッジ共有促進 |
| 研究開発 | 最新の論文、特許情報、社内研究データに基づいた情報収集・分析 | R&Dサイクルの加速、意思決定の質の向上 |
RAGの導入は、生成AIを単なる「便利なツール」から「信頼できるビジネスパートナー」へと昇華させるための重要なステップです。貴社のビジネスにAIを深く組み込み、競争優位性を確立するために、RAGは不可欠な技術と言えるでしょう。
生成AIの「正しい参照導線」を構築するための実践ステップ
生成AIの真価を引き出すには、単に高性能なLLMを導入するだけでは不十分です。最も重要なのは、AIが参照すべき「データ」をいかに正確かつ効率的に提供するか、すなわち「正しい参照導線」を構築することにあります。ここでは、貴社が実践すべき具体的なステップを解説します。
ステップ1:企業内データの棚卸しと品質管理の徹底
生成AIの参照導線の出発点は、貴社が保有する膨大な企業内データです。これらのデータがなければ、AIは一般的な知識しか提供できず、貴社固有の課題解決には繋がりません。まずは、社内にあるあらゆるデータを洗い出し、その品質を徹底的に管理することが不可欠です。
データの棚卸し
- 対象範囲の特定: 顧客情報、製品マニュアル、営業資料、契約書、FAQ、過去の問い合わせ履歴、社内規程、技術文書、研究レポート、議事録、チャットログなど、AIに参照させたいあらゆるドキュメントやデータベースを特定します。
- 現状把握: 各データの保存場所(ファイルサーバー、SharePoint、CRM、ERP、SFA、ナレッジマネジメントシステムなど)、フォーマット(PDF、Word、Excel、HTML、テキスト、データベースレコードなど)、アクセス権限、更新頻度を明確にします。
- 重複・陳腐化データの特定: 同じ内容のデータが複数存在したり、情報が古くなっているデータを特定し、整理の対象とします。
品質管理の徹底
データの品質は、そのままAIの出力精度に直結します。以下の観点から品質管理を徹底します。
- 正確性: 情報が事実に基づいているか、誤りがないかを確認します。特に数値データや固有名詞は重要です。
- 鮮度: 最新の情報が反映されているかを確認します。古い情報はAIの判断を誤らせる原因となります。
- 一貫性: 表現や用語、フォーマットにばらつきがないかを確認します。表記揺れはAIが情報を正しく解釈する妨げとなります。
- 粒度: AIが参照しやすいように、情報が適切な単位で分割されているか、あるいは統合されているかを確認します。長すぎるドキュメントは関連情報を見つけにくくし、短すぎる断片は文脈を失わせます。
- メタデータ付与: 各データに「作成日」「更新日」「作成者」「カテゴリ」「キーワード」「関連部署」などのメタデータを付与します。これにより、検索精度が飛躍的に向上します。
データ品質管理は一度行えば終わりではありません。データは常に変化するため、継続的な運用体制とプロセスを確立することが重要です。私たちは、データガバナンスのフレームワーク構築から支援し、貴社が自律的に高品質なデータを維持できる仕組み作りをサポートします。
| データ品質の項目 | チェックポイント | AI出力への影響 |
|---|---|---|
| 正確性 | 情報に誤りがないか、事実に基づいているか | 誤情報(ハルシネーション)の発生、不正確な回答 |
| 鮮度 | 情報が最新の状態に保たれているか | 古い情報に基づく回答、現状との乖離 |
| 一貫性 | 用語や表現に揺れがないか、フォーマットが統一されているか | AIの誤解釈、検索精度の低下、不自然な回答 |
| 粒度 | 情報が適切な単位でまとめられているか、細かすぎないか | 関連情報の見落とし、不完全な回答、冗長な回答 |
| 網羅性 | 必要な情報が欠落していないか | 「情報がありません」という回答、限定的な回答 |
ステップ2:ナレッジベース(参照データベース)の設計と構築
棚卸しと品質管理を終えたデータは、AIが効率的にアクセスできるよう、体系的に整理されたナレッジベースに格納する必要があります。このナレッジベースの設計が、RAG(Retrieval Augmented Generation)システムの性能を大きく左右します。
ナレッジベースの種類の選定
データの種類や利用目的に応じて、最適なデータベースを選定します。
- ベクトルデータベース: ドキュメントの内容を数値ベクトルに変換し、意味的な類似度に基づいて検索するのに特化しています。非構造化データ(テキスト、画像など)のセマンティック検索に威力を発揮します。(出典:Pinecone, Weaviateなどのドキュメント)
- リレーショナルデータベース(RDB): 構造化されたデータ(顧客情報、製品情報など)の管理に適しています。正確な条件検索や集計処理が必要な場合に有効です。
- ドキュメントデータベース: JSONなどのドキュメント形式でデータを格納し、柔軟なデータモデルが特徴です。半構造化データの管理に適しています。
- グラフデータベース: データ間の関係性を表現するのに優れており、複雑な関連性をたどる検索に適しています。
設計のポイント
- スケーラビリティ: 将来的なデータ量の増加やユーザー数の増加に対応できる設計とします。
- 検索効率: AIが迅速に適切な情報を取得できるよう、インデックス設計やデータ構造を最適化します。
- 更新容易性: データが更新された際に、ナレッジベースも容易に最新の状態に保てる仕組みを構築します。
- セキュリティ: 機密性の高いデータが含まれる場合、厳格なアクセス制御や暗号化を実装します。
- チャンク分割戦略: 長いドキュメントをAIが処理しやすいように、意味のある単位で分割(チャンク化)します。チャンクサイズや重複の有無は、検索精度と生成結果に大きく影響します。
私たちは、貴社のデータ特性と利用シナリオに基づき、最適なナレッジベースのアーキテクチャ設計から構築、運用までを一貫してサポートします。当社の経験では、ある金融機関のケースで、既存のFAQシステムと契約書データベースを統合し、ベクトルデータベースを中核とするハイブリッドなナレッジベースを構築しました。これにより、顧客からの複雑な問い合わせに対して、AIが正確かつ迅速に回答できるようになりました。
ステップ3:効率的な検索・インデックス化技術の選定と実装
生成AIが参照すべき情報をナレッジベースから「いかに素早く、かつ的確に」見つけ出すか。これがRAGの「Retrieval(検索)」部分の中核であり、その成否は検索・インデックス化技術の選定にかかっています。
インデックス化のプロセス
データがナレッジベースに格納されると、AIが検索しやすいようにインデックス化されます。
- テキスト抽出: PDFや画像内のテキストをOCRなどで抽出し、構造化します。
- チャンク分割: 長いドキュメントを意味のある小さな塊(チャンク)に分割します。
- 埋め込みベクトル生成: 各チャンクを、意味を数値化した「埋め込みベクトル」に変換します。この際、Transformerベースのモデル(例:OpenAIのtext-embedding-ada-002、GoogleのPaLM Embeddingsなど)が利用されます。(出典:OpenAI Embeddings APIドキュメント)
- インデックス構築: 生成された埋め込みベクトルをベクトルデータベースに格納し、高速な類似度検索を可能にするインデックス(例:FAISS、HNSWなど)を構築します。
検索技術の選定
ユーザーの質問(クエリ)に対して、ナレッジベースから最も関連性の高い情報を取得するための技術を選定します。
- キーワード検索(Lexical Search): 質問とドキュメントに含まれるキーワードの合致度で検索します。SolrやElasticsearchなどが代表的です。特定の固有名詞やコードなど、完全一致が重要な場合に有効です。
- セマンティック検索(Semantic Search / Vector Search): 質問の「意味」を理解し、意味的に関連性の高いドキュメントを検索します。埋め込みベクトル間の類似度(コサイン類似度など)を計算することで実現します。ユーザーが使用する言葉がナレッジベースの言葉と異なっていても、意味が近ければ関連情報を取得できます。
- ハイブリッド検索: キーワード検索とセマンティック検索の両方を組み合わせることで、それぞれの欠点を補い、より高精度な検索を実現します。例えば、BM25(キーワード検索)とベクトル検索の結果を統合する手法が一般的です。(出典:ElasticsearchのHybrid Search機能)
適切な検索技術の選定と実装は、貴社のAI活用において決定的な差を生み出します。私たちは、貴社のデータ特性、検索要件、利用シーンを詳細に分析し、最も効果的な検索・インデックス化戦略を提案します。当社の経験では、ある製造業の技術サポート部門で、数万件に及ぶ過去の修理履歴や技術マニュアルに対し、ハイブリッド検索を導入することで、技術者が過去の類似事例を瞬時に発見できるようになり、問題解決までの時間が平均で20%短縮されました。
| 検索技術 | 特徴 | 得意なシナリオ | 課題 |
|---|---|---|---|
| キーワード検索 | キーワードの完全一致や部分一致で情報を検索 | 特定の製品名、コード、人名など固有名詞の検索 | 同義語や類義語、言い換えに対応しにくい |
| セマンティック検索 | 質問の「意味」を理解し、関連性の高い情報を検索 | 曖昧な質問、自然言語での質問、概念的な検索 | キーワードの完全一致が必要な場合に不向きなことも |
| ハイブリッド検索 | キーワード検索とセマンティック検索を組み合わせる | 高い検索精度が求められるあらゆるシナリオ | 実装の複雑さ、計算リソースの増加 |
ステップ4:生成AIとの連携とプロンプト設計の最適化
ナレッジベースから関連情報が取得できたら、いよいよそれを生成AIに渡し、ユーザーへの回答を生成させます。この最後のステップで重要なのが、生成AIとの連携方法とプロンプト設計の最適化です。
RAGにおけるプロンプトの構成要素
取得した情報をAIに効果的に伝えるプロンプトは、以下の要素で構成されます。
- 役割指示(System Prompt): AIにどのような役割を演じるか(例:「あなたはプロのカスタマーサポート担当者です」)を指示します。
- 制約条件・出力形式指示: 回答の長さ、トーン、使用言語、出力形式(箇条書き、要約など)を明確に指定します。
- コンテキスト(参照情報): ナレッジベースから取得した関連情報をここに挿入します。これがAIの「参照導線」の中核となります。
- ユーザーの質問: 最終的にAIに回答してほしい具体的な質問です。
あなたはプロのカスタマーサポート担当者です。以下の参照情報を基に、顧客の質問に正確かつ簡潔に回答してください。参照情報にない内容は回答しないでください。
[ここにステップ3で取得した関連ドキュメントのチャンクが挿入されます]
顧客からの質問:[ユーザーの質問]
プロンプト設計の最適化
- 情報源の明示: AIが参照した情報の出典を回答に含めることで、ユーザーは情報の信頼性を確認でき、ハルシネーション(AIが事実に基づかない情報を生成すること)対策にもなります。
- ハルシネーション対策: 「参照情報にない内容は回答しないでください」「不明な場合は『情報が見つかりませんでした』と答えてください」といった指示をプロンプトに含めます。
- 反復と改善: プロンプトは一度作成したら終わりではありません。実際の利用状況やAIの出力結果をモニタリングし、継続的に改善していきます。A/Bテストも有効です。
- Few-shot Learningの活用: 期待する回答の具体例をプロンプトにいくつか含めることで、AIの出力品質を向上させることができます。(出典:Google AI Blog – Few-shot learning for language models)
ユーザーフィードバックループの構築
AIの回答に対するユーザーからのフィードバック(「役に立った」「役に立たなかった」など)を収集し、その情報を基にナレッジベースの改善、検索アルゴリズムの調整、プロンプトの最適化を行う仕組みを構築します。このサイクルを回すことで、AIの精度は継続的に向上します。
私たちは、これらのプロンプト設計のベストプラクティスを提供し、貴社のAIがビジネス価値を最大化できるよう支援します。当社の経験では、ある大手小売業の社内ヘルプデスクで、このRAGとプロンプト設計の最適化により、AIによる一次回答率が65%から88%に向上し、担当者の業務負荷が大幅に軽減されました。
RAG導入で直面する課題と解決策:実務でAIを活用するために
生成AIの参照導線としてRAG(Retrieval Augmented Generation)を導入する際、多くの企業が実務レベルで様々な課題に直面します。単にシステムを構築するだけでなく、その運用、精度維持、そして組織全体での活用を考慮しなければ、期待する効果は得られません。ここでは、RAG導入における主要な課題と、それらを解決するための具体的なアプローチについて解説します。
データ鮮度・更新頻度の管理と自動化
RAGシステムが参照するデータの鮮度は、生成されるAIの回答精度と信頼性に直結します。情報が古ければ、AIは誤った情報や陳腐化した情報を基に回答を生成してしまい、ユーザーの信頼を損ねる原因となります。
課題:
多くの企業では、参照データが複数のシステムに分散しており、手動でのデータ収集や更新は非常に手間がかかります。これにより、データがRAGシステムに反映されるまでにタイムラグが生じ、リアルタイム性に欠ける情報提供となってしまうことがあります。特に、製品情報、顧客サポートFAQ、社内規定など、頻繁に更新される情報源を扱う場合、この課題は顕著です。
解決策:
この課題を解決するためには、データソースとRAGシステムの連携を強化し、データの自動更新パイプラインを構築することが不可欠です。
- リアルタイムに近いデータ同期: 既存のデータベース(DB)、ファイルストレージ、Webサイトなど、参照元となるデータソースからRAGシステムが利用するベクトルデータベースへのデータ同期を自動化します。変更データキャプチャ(CDC)技術やWebフックなどを活用することで、データソースの変更を検知し、即座にRAGシステムに反映させることが可能です。
- 更新頻度の最適化: データの種類や重要度に応じて、更新頻度を適切に設定します。例えば、製品価格や在庫情報は数分〜数時間ごと、一般的なFAQは日次、社内規定や技術文書は週次〜月次といった具合です。
- インデックス再構築の自動化: データが更新された際には、ベクトルデータベースのインデックス(埋め込み表現)も自動的に再構築される仕組みを導入します。これにより、常に最新のデータに基づいて検索が行われるようになります。
- バージョン管理とロールバック機能: データの更新履歴を管理し、問題が発生した場合には過去のバージョンに容易にロールバックできる機能を備えることで、運用上のリスクを低減します。
データ更新頻度とRAGシステムへの影響の例を以下の表にまとめました。
| データ種類 | 推奨更新頻度 | 更新が遅れた場合のリスク | 解決策の例 |
|---|---|---|---|
| 製品価格・在庫情報 | リアルタイム〜数分 | 誤った価格・在庫情報による顧客不満、機会損失 | CDC、API連携による自動同期 |
| 顧客サポートFAQ | 日次〜週次 | 最新の解決策が反映されず、サポート効率低下 | 定期バッチ処理、変更検知によるインデックス更新 |
| 社内規定・人事情報 | 週次〜月次 | 古い規定に基づく誤った判断、コンプライアンス違反 | バージョン管理システム連携、承認フロー後の自動反映 |
| ニュース・市場トレンド | リアルタイム〜日次 | 市場動向への対応遅れ、競争力低下 | RSSフィード、ニュースAPI連携 |
参照データの粒度と関連性の最適化:検索精度の向上
RAGの検索精度は、参照データの「粒度(チャンクサイズ)」と「関連性」に大きく左右されます。この最適化を怠ると、AIが適切な情報を取得できず、期待通りの回答を生成できません。
課題:
参照データのチャンク(分割された情報単位)が粗すぎると、AIは漠然とした情報しか得られず、具体的な質問に答えられません。逆に細かすぎると、文脈が失われたり、無関係な情報がノイズとして混入したりし、ハルシネーション(AIが事実に基づかない情報を生成すること)のリスクが高まります。また、質問と参照データの関連性が低い場合、AIは誤った情報を基に回答を生成してしまいます。
解決策:
検索精度を向上させるためには、チャンク戦略の最適化、メタデータ付与、そしてセマンティック検索の導入が効果的です。
- チャンクサイズとオーバーラップの調整: 質問の性質や参照データの種類に応じて、最適なチャンクサイズとオーバーラップ(チャンク間の重複部分)を試行錯誤して見つけます。例えば、Q&A形式のデータであれば短いチャンク、詳細な技術文書であればある程度の長さを持たせたチャンクが適しています。オーバーラップを設けることで、文脈の途切れを防ぎます。
- 階層的チャンキング: ドキュメント全体を要約したチャンク、セクションごとのチャンク、パラグラフごとのチャンクなど、複数の粒度でデータを分割し、質問に応じて適切な粒度のチャンクを検索するアプローチです。これにより、質問の抽象度に応じた適切な情報を取得できます。
- ベクトルデータベースと埋め込みモデルの選定: 高度なセマンティック検索を実現するために、高性能なベクトルデータベースと、貴社のデータ特性に合った埋め込みモデル(Embedding Model)を選定します。特定の業界用語や専門用語が多い場合は、それらに特化したモデルや、ファインチューニングされたモデルの利用を検討すべきです。
- メタデータによるフィルタリングとランキング: 参照データに作成日、カテゴリ、キーワード、作成者などのメタデータを付与し、検索時にこれらを活用して関連性の高い情報を絞り込んだり、ランキングを調整したりします。例えば、「最新の製品情報」という質問に対しては、作成日のメタデータでフィルタリングを行うことで、より適切な情報を提示できます。
- ハイブリッド検索: キーワード検索(BM25など)とベクトル検索(セマンティック検索)を組み合わせることで、それぞれの長所を活かし、より網羅的かつ高精度な検索を実現します。これにより、キーワードが完全に一致しない場合でも、意味的に関連性の高い情報を取得できるようになります。
チャンク戦略の種類と特徴を以下の表にまとめました。
| チャンク戦略 | 特徴 | メリット | デメリット | 適したデータタイプ |
|---|---|---|---|---|
| 固定サイズチャンク | 一定の文字数や単語数で機械的に分割。 | 実装が容易、処理が高速。 | 文脈の途中で切れる可能性あり、情報の欠落。 | 構造が単純なテキストデータ、ログデータ。 |
| セマンティックチャンク | 文脈や意味のまとまりで分割。 | 文脈を保持しやすい、自然な情報単位。 | 実装が複雑、分割精度がモデルに依存。 | 技術文書、ブログ記事、報告書。 |
| 階層的チャンク | 異なる粒度(全体要約、セクション、パラグラフ)で分割。 | 質問の抽象度に応じた柔軟な検索。 | データの準備と管理が複雑、ストレージ消費増。 | 大規模なドキュメント、マニュアル。 |
| チャンクとメタデータ付与 | チャンクにカテゴリ、日付、キーワードなどの情報を付与。 | フィルタリングやランキングによる検索精度向上。 | メタデータ設計・付与の手間、管理の複雑化。 | あらゆる種類のデータ、特に多様な情報源。 |
当社の経験では、ある金融機関の事例で、顧客からの問い合わせデータ(非構造化データ)に対し、固定サイズチャンクからセマンティックチャンクへ移行し、さらにメタデータ(製品カテゴリ、問い合わせ種別)を付与することで、RAGの回答精度が約15%向上し、オペレーターの回答作成時間が平均で20秒短縮されたと報告されています。
AI生成コンテンツの信頼性と倫理的配慮(著作権、情報源明示)
RAGは参照データに基づいて回答を生成しますが、それでもAIが不正確な情報や著作権に抵触する可能性のあるコンテンツを生成するリスクはゼロではありません。特にBtoBの文脈では、生成される情報の信頼性と倫理的側面は極めて重要です。
課題:
AIが生成したコンテンツが事実と異なる「ハルシネーション」を起こしたり、参照元の情報源が不明確であったりすると、企業の信頼性に関わる問題に発展する可能性があります。また、参照データに著作権保護されたコンテンツが含まれている場合、それを基にAIが生成したコンテンツが著作権侵害となるリスクも考慮しなければなりません。
解決策:
AI生成コンテンツの信頼性を確保し、倫理的なリスクを管理するためには、以下の対策が必要です。
- ファクトチェックプロセスの導入: RAGが生成した回答を、人間が最終的に確認するプロセスを導入します。特に、公開される情報や重要な意思決定に影響を与える情報については、専門家によるレビューを必須とすべきです。
- 情報源の明示: AIが回答を生成する際に参照したドキュメントやデータソースを明確に提示する機能を実装します。これにより、ユーザーはAIの回答の根拠を確認でき、信頼性が向上します。例えば、回答文中に参照元のドキュメント名やページ番号、URLなどを埋め込む形が考えられます。
- 著作権ガイドラインの策定と遵守: 参照データとして利用するコンテンツの著作権を確認し、利用範囲を明確にするガイドラインを策定します。AI生成コンテンツが既存の著作物を模倣したり、無断で引用したりしないよう、生成モデルの調整や出力フィルタリングの仕組みを検討します。
- 倫理的AI利用ガイドラインの確立: 企業としてAIを倫理的に利用するためのガイドラインを策定し、従業員への教育を徹底します。これには、個人情報保護、差別的表現の回避、透明性の確保などが含まれます。
AI生成コンテンツの信頼性確保のためのチェックリストを以下の表に示します。
| 項目 | 確認内容 | 対応策例 | 責任部署 |
|---|---|---|---|
| 事実の正確性 | 生成された情報が客観的事実と一致するか | 人間によるファクトチェック、複数情報源との照合 | コンテンツ管理部門、事業部門 |
| 情報源の明示 | 参照したドキュメントやデータソースが明確か | 参照元リンクの自動挿入機能、引用元表示 | システム開発部門、コンテンツ管理部門 |
| 著作権侵害リスク | 既存の著作物からの無断転載・模倣がないか | 参照データ利用規定の策定、著作権チェックツールの導入 | 法務部門、コンテンツ管理部門 |
| 個人情報保護 | 個人情報や機密情報が含まれていないか | データ匿名化処理、情報フィルタリング | 情報セキュリティ部門、法務部門 |
| 差別・偏見 | 差別的、偏見のある表現が含まれていないか | 倫理ガイドライン策定、モデルのバイアス評価 | 人事部門、倫理委員会 |
業界では、AIが生成したコンテンツの透明性を高めるため、生成AIが利用されたことを示す「AI生成マーク」の義務化を検討する動きもあります(出典:総務省「AIネットワーク社会推進会議」報告書)。貴社においても、このような外部の動きも踏まえ、信頼性確保のための体制を構築することが重要です。
複数システム連携の複雑性とスケーラビリティの確保
RAGシステムは単体で機能するものではなく、既存の基幹システム、データウェアハウス、顧客管理システム(CRM)、Webサイト、社内ポータルなど、様々なシステムと連携して初めて真価を発揮します。この連携が複雑になると、運用負荷が増大し、将来的な拡張性も損なわれる可能性があります。
課題:
異なる技術スタック、データ形式、認証方式を持つ複数のシステムとRAGを連携させることは、技術的な複雑さを伴います。連携部分の設計や開発に多大なリソースを要し、システム全体のパフォーマンスボトルネックとなる可能性もあります。また、利用者の増加やデータ量の拡大に伴い、システムがスケーラブルに対応できるかどうかも重要な課題です。
解決策:
システム連携の複雑性を管理し、将来的なスケーラビリティを確保するためには、以下の点が重要です。
- API連携の標準化と設計: 既存システムとの連携には、RESTful APIなどの標準的なインターフェースを積極的に利用します。APIドキュメントを整備し、データ形式や認証方式を統一することで、連携の複雑性を低減します。
- マイクロサービスアーキテクチャの採用: RAGシステムを、検索モジュール、生成モジュール、データ取り込みモジュールなど、独立したマイクロサービスとして構築することで、各機能の独立性を高め、開発・保守・スケールアップを容易にします。
- クラウドインフラの活用: AWS、Azure、GCPなどのパブリッククラウドサービスを利用することで、必要に応じてコンピューティングリソースやストレージを柔軟に拡張・縮小できます。これにより、初期投資を抑えつつ、利用者の増加やデータ量の増大に合わせたスケーラビリティを確保できます。
- コンテナ技術とオーケストレーション: Dockerなどのコンテナ技術を用いてアプリケーションをパッケージ化し、Kubernetesなどのコンテナオーケストレーションツールでデプロイ・管理することで、異なる環境間での一貫した運用と高い可用性を実現します。
- モニタリングとログ管理の徹底: システム全体のパフォーマンス、エラー発生状況、各サービスの稼働状況などをリアルタイムで監視する仕組みを導入します。統合的なログ管理により、問題発生時の原因特定と迅速な対応が可能になります。
RAGシステム連携における主要な考慮事項を以下の表にまとめました。
| 考慮事項 | 詳細 | 具体例 |
|---|---|---|
| データソース連携 | RAGが参照する多様なデータソースとの接続方法 | DBコネクタ、API連携、ファイル連携(S3, SharePoint)、Webスクレイピング |
| 既存システム連携 | RAGの機能を既存の業務システムやアプリケーションに組み込む方法 | CRMへのRAG回答表示、社内ポータルからの問い合わせ連携 |
| 認証・認可 | RAGシステムおよび連携先システムへのセキュアなアクセス管理 | OAuth2.0、SAML、シングルサインオン(SSO) |
| データ変換・ETL | 異なるデータ形式間での変換、抽出・変換・ロード処理 | データパイプラインツール(Apache Airflow, AWS Glue)、カスタムスクリプト |
| スケーラビリティ | 利用者数やデータ量増大に対応できる拡張性 | クラウドサービス(AWS Lambda, Azure Functions)、Kubernetes |
| 運用・監視 | システム稼働状況の監視、エラー検知、ログ管理 | Prometheus, Grafana, ELK Stack, クラウドネイティブ監視ツール |
当社の支援事例では、ある製造業A社でRAG導入にあたり、既存の製品マニュアル管理システム(オンプレミス)と顧客サポートシステム(クラウドSaaS)の連携が大きな課題でした。私たちは、中間APIレイヤーを構築し、データ変換と認証を一元化するアーキテクチャを提案しました。これにより、各システムの独立性を保ちつつ、RAGからのシームレスな情報参照を実現し、導入後の運用負荷を大幅に削減することができました。
Aurant Technologiesが支援する「データ駆動型AI」の実践
生成AIの導入が加速する中で、その真価を引き出す鍵は、質の高いデータとその適切な「参照導線」にあります。単に高性能なLLMを導入するだけでは、期待する精度や実用性は得られません。私たち Aurant Technologies は、貴社の既存データを最大限に活用し、生成AIのポテンシャルを解き放つ「データ駆動型AI」の実践を支援しています。
ここでは、私たちが提供する具体的なソリューションを通じて、どのようにAIの精度を高め、貴社のビジネスに貢献していくかをご紹介します。
kintoneを活用した企業ナレッジベース構築支援とRAG連携
多くの企業が持つ課題の一つは、社内に散在するナレッジや情報が十分に活用されていないことです。特に、業務マニュアル、FAQ、過去のプロジェクト報告書、顧客対応履歴といった貴重なデータは、担当者個人の経験に依存し、組織全体での共有が難しいケースが少なくありません。
私たちは、サイボウズのkintoneを基盤とした企業ナレッジベースの構築を支援しています。kintoneは、プログラミング知識がなくても業務アプリを柔軟に作成できるため、貴社の業務プロセスに合わせたナレッジの蓄積・管理が容易です。これにより、部門間の情報共有が促進され、業務効率化に貢献します。
さらに、このkintoneで整備されたナレッジベースを、RAG(Retrieval Augmented Generation:検索拡張生成)の参照データとして活用することで、生成AIの回答精度を飛躍的に向上させます。AIは、質問に対して直接回答を生成するのではなく、kintoneから関連情報を検索し、その情報を基に回答を生成するため、事実に基づいた正確かつ最新の情報をユーザーに提供できるようになります。
例えば、顧客からの問い合わせに対し、AIがkintone上のFAQや過去の対応履歴を参照し、具体的な解決策を提示するといった活用が可能です。これにより、顧客対応の品質向上と、担当者の業務負荷軽減を両立させることができます。
| kintoneとRAG連携の主なメリット | 詳細 |
|---|---|
| 情報の一元管理 | 散在する社内情報をkintoneに集約し、検索性を向上させます。 |
| AI回答の精度向上 | 信頼性の高い社内データを参照することで、AIのハルシネーション(誤情報生成)リスクを低減し、より正確な回答を生成します。 |
| 業務効率化 | AIが自動で情報検索・要約を行うことで、従業員の情報探索にかかる時間を削減し、本来業務に集中できる環境を創出します。 |
| ナレッジの属人化解消 | 個人の経験や知識を組織の資産として蓄積し、誰もが必要な情報にアクセスできる環境を整備します。 |
| 継続的な改善 | AIの利用状況や回答フィードバックを分析し、ナレッジベースとAIの双方を継続的に改善するサイクルを構築します。 |
BIツール連携によるデータ品質とAIアウトプットの可視化・評価
生成AIの導入効果を最大化するためには、そのアウトプット(生成された回答やコンテンツ)の品質を継続的に評価し、改善していくプロセスが不可欠です。私たちは、BI(ビジネスインテリジェンス)ツールとの連携を通じて、AIアウトプットの品質を可視化し、データ駆動型の改善サイクルを構築する支援を行っています。
具体的には、AIが参照したデータソース、回答の正確性、関連性、ユーザーからの評価(高評価/低評価)、解決率などの指標をBIツールでダッシュボード化します。これにより、どのデータがAIのパフォーマンスに影響を与えているのか、どのタイプの質問でAIの精度が低いのか、といった傾向を視覚的に把握できます。
例えば、AIが生成した回答がユーザーによって「不正確」と評価された場合、BIダッシュボード上でその原因(参照データの古さ、情報の欠落など)を深掘りし、ナレッジベースの更新やAIモデルのチューニングに繋げることができます。このプロセスを通じて、AIの精度だけでなく、参照元となるデータの品質自体も向上させることが可能です。
このような可視化と評価の仕組みは、AIの「ブラックボックス化」を防ぎ、貴社がAIを信頼して業務に組み込むための重要な基盤となります。データに基づいた客観的な評価は、AI活用における意思決定を支援し、継続的なROI(投資対効果)の向上に貢献します。
業界特化型RAGソリューション(会計DX、医療系データ分析など)
RAGの真価は、特定の業界や業務領域に特化した専門性の高いデータセットと組み合わせることで発揮されます。一般的な情報に加えて、業界固有の専門用語、規制、慣習、過去の事例などをRAGの参照データとして組み込むことで、生成AIはより高度で実用的なアウトプットを提供できるようになります。
私たちは、貴社の業界に深く根差した課題を理解し、それに特化したRAGソリューションの構築を支援しています。例えば、会計DXの分野では、複雑な税法、会計基準、過去の監査報告書、社内規定などをRAGの参照データとして活用します。これにより、AIは経費精算の自動チェック、財務報告書の作成支援、監査対応に関する情報提供など、高度な業務支援が可能になります。
また、医療系データ分析では、膨大な医学論文、臨床ガイドライン、患者の匿名化された診療記録、医薬品情報などをRAGで連携させます。これにより、AIは医師の診断支援、新薬の研究開発における情報収集、患者への説明資料作成など、多岐にわたる医療現場のDXを加速させます。業界特有の専門性をAIに付与することで、一般的なAIでは対応できないような、高度な意思決定支援を実現します。
| 業界特化型RAGソリューションの適用分野と期待効果(参考) | 適用分野例 | 期待される具体的な効果 |
|---|---|---|
| 会計・財務 | 税務相談、会計基準解釈、監査対応、内部統制文書作成 | 法規制順守の強化、経理業務の効率化、監査工数の削減、専門知識へのアクセス容易化 |
| 医療・製薬 | 診断支援、治療方針の策定支援、医学論文検索、新薬開発情報収集、患者向け説明資料作成 | 診断精度の向上、研究開発の加速、医療従事者の情報収集負荷軽減、患者エンゲージメント向上 |
| 法務 | 契約書レビュー、判例検索、法規制調査、コンプライアンスチェック | 契約リスクの低減、法務業務の効率化、コンプライアンス違反リスクの軽減 |
| 製造業 | 製品マニュアル、トラブルシューティング、設計仕様書、品質管理基準、過去の不具合事例 | 製品開発期間の短縮、品質問題解決の迅速化、技術伝承の効率化、メンテナンスコスト削減 |
| 金融 | 金融商品情報、市場分析レポート、規制対応、顧客対応FAQ、リスク管理 | 顧客対応品質の向上、リスク分析の高度化、規制順守支援、新商品開発の加速 |
(業界の動向や当社の知見に基づけば、これらの効果が期待されます。)
LINE連携による顧客対応AIの高度化と業務効率化
顧客との接点として、LINEは日本において非常に重要なプラットフォームとなっています。私たちは、このLINEと生成AI、特にRAGを連携させることで、顧客対応の高度化と業務効率化を同時に実現するソリューションを提供しています。
従来のチャットボットは、FAQデータに基づいた定型的な回答しかできないことが多く、複雑な問い合わせには対応できませんでした。しかし、RAGを活用することで、AIは貴社の持つあらゆるナレッジベース(kintone、CRM、製品データベースなど)を参照し、顧客からの多様な質問に対して、よりパーソナライズされた、かつ正確な回答をリアルタイムで生成できるようになります。
例えば、顧客が製品のトラブルについて問い合わせた際、AIは製品マニュアル、過去の修理履歴、FAQなどを参照し、具体的な解決手順や関連情報を提供します。これにより、顧客は迅速に問題を解決でき、顧客満足度が向上します。同時に、オペレーターは定型的な問い合わせ対応から解放され、より複雑で付加価値の高い業務に集中できるようになります。
さらに、AIが解決できなかった問い合わせについては、スムーズにオペレーターに引き継ぐ仕組みを構築し、AIと人間のハイブリッドな顧客対応を実現します。AIが事前に情報を収集・整理しておくことで、オペレーターは顧客対応の初期段階から本質的な問題解決に集中でき、対応時間の短縮と効率化に繋がります。
| LINE連携AIチャットボットの導入効果 | 詳細 |
|---|---|
| 顧客満足度向上 | 24時間365日対応、迅速かつ正確な情報提供により、顧客の利便性と満足度が高まります。 |
| 業務効率化 | 定型的な問い合わせの自動対応により、コールセンターやサポート部門の業務負荷を大幅に軽減します。 |
| コスト削減 | オペレーターの増員を抑えつつ、対応件数を増やすことが可能になり、人件費などの運用コストを削減します。 |
| データ活用促進 | AIとの対話履歴を分析することで、顧客ニーズや課題を深く理解し、サービス改善や新商品開発に活かせます。 |
| 従業員の生産性向上 | オペレーターはより専門的な業務や複雑な課題解決に集中できるようになり、生産性が向上します。 |
成功事例から学ぶ「正しい参照導線」がもたらすビジネスインパクト
生成AIの導入がビジネスに与える影響は計り知れませんが、その真価は「正しい参照導線」の設計によって最大限に引き出されます。ここでは、参照導線を最適化することで、実際にどのようなビジネスインパクトが生まれたのか、具体的な成功事例を通して見ていきましょう。
顧客サポートの効率化と回答精度の飛躍的向上
多くの企業が顧客サポートの効率化を目指し、AIチャットボットを導入しています。しかし、導入当初は「質問と異なる回答が返ってくる」「情報が古くて役に立たない」といった課題に直面し、顧客満足度を低下させてしまうケースも少なくありませんでした。これは、AIが参照するデータが整理されていなかったり、検索ロジックが不十分だったりすることが主な原因です。
ある大手通信企業では、AIチャットボット導入後も顧客からの再問い合わせ率が改善しないという課題を抱えていました。そこで私たちが行ったのは、既存のFAQや製品マニュアル、過去の問い合わせ履歴といった膨大な顧客サポートデータを徹底的に構造化し、最新の状態に保つための参照導線設計です。具体的には、文書ごとに適切なタグ付けを行い、関連性の高い情報を紐づけるだけでなく、顧客の質問意図を正確に解釈するためのセマンティック検索機能を強化しました。
この取り組みの結果、AIチャットボットの回答精度は飛躍的に向上しました。例えば、特定の製品のトラブルシューティングに関する質問に対し、以前は一般的な回答しかできなかったAIが、参照導線の改善後は具体的な解決手順や関連動画へのリンクまで提示できるようになりました。これにより、顧客の自己解決率が向上し、オペレーターへのエスカレーションが大幅に減少しました。
業界の調査によれば、AIチャットボット導入企業のうち、ナレッジベースの最適化と参照導線の改善に取り組んだ企業は、平均して顧客満足度が15%向上し、オペレーターの対応時間が20%短縮されたと報告されています(出典:Zendesk「顧客体験トレンドレポート2023」)。
以下は、参照導線改善前後の顧客サポート指標の比較例です。
| 指標 | 改善前(AI導入初期) | 改善後(参照導線最適化後) | 改善率 |
|---|---|---|---|
| 顧客自己解決率 | 40% | 70% | +75% |
| オペレーターへのエスカレーション率 | 60% | 30% | -50% |
| 平均応答時間(チャットボット) | 10秒 | 3秒 | -70% |
| 顧客満足度(CSAT) | 3.5/5点 | 4.2/5点 | +20% |
| 月間サポートコスト | XX万円 | YY万円 | -15% |
このように、単にAIを導入するだけでなく、AIが参照する「データ」とその「導線」を最適化することで、顧客サポートは単なるコストセンターから、顧客体験を向上させる重要なタッチポイントへと変貌を遂げます。
社内ナレッジ活用の促進と業務効率化・意思決定の迅速化
多くの企業では、部門ごとに情報がサイロ化し、必要な情報を見つけるまでに時間がかかったり、同じような業務が重複して行われたりする「ナレッジの非効率性」という課題を抱えています。特に、新入社員のオンボーディング期間や、異なる部門間の連携が必要なプロジェクトにおいて、この問題は顕著になります。
当社の支援事例では、ある製造業A社で、製品開発から販売までのプロセスにおいて、各部門が個別にドキュメントを管理しており、全体最適化が難しい状況でした。私たちは、この問題を解決するために、生成AIを活用した社内ナレッジ検索システムを構築。特に、RAG(Retrieval Augmented Generation:検索拡張生成)の考え方を応用し、社内の膨大な文書群(設計図、技術仕様書、営業資料、会議議事録など)を参照データとして統合しました。
このシステムの肝となったのは、参照導線の設計です。具体的には、各文書に対して「製品名」「プロジェクト名」「担当者」「フェーズ」といったメタデータを付与し、さらに文書内のキーワードや概念を抽出し、それらを関連付けるための知識グラフを構築しました。これにより、社員は自然言語で質問するだけで、関連性の高い情報を複数の文書から横断的に検索し、AIが要約した形で素早く回答を得られるようになりました。
結果として、情報検索にかかる時間は平均30%短縮され、新入社員のオンボーディング期間は2ヶ月から1ヶ月半に短縮されました。また、異なる部門間の情報共有がスムーズになったことで、製品開発サイクルの短縮にも貢献。意思決定のスピードも向上し、市場への投入タイミングを最適化できるようになりました。
社内ナレッジ活用における参照導線設計のポイントは以下の通りです。
| 要素 | 具体的な設計ポイント | 期待される効果 |
|---|---|---|
| データの統合と標準化 |
|
|
| メタデータとタグ付け |
|
|
| セマンティック検索の導入 |
|
|
| アクセス権限とセキュリティ |
|
|
| 継続的な更新とメンテナンス |
|
|
社内ナレッジの「正しい参照導線」は、単なる情報共有ツールを超え、組織全体の生産性向上と競争力強化に直結する戦略的な資産となります。
新規事業開発・マーケティング施策への応用とデータドリブンな戦略立案
新規事業開発やマーケティング戦略の立案において、市場トレンドの把握、競合分析、顧客インサイトの抽出は不可欠です。しかし、これらの情報は多岐にわたり、散在しているため、網羅的かつ迅速に収集・分析することは容易ではありません。生成AIは、このプロセスを劇的に加速させる可能性を秘めていますが、そのためには「どこから、どのような情報を、どのように参照するか」という導線が極めて重要になります。
当社の支援事例では、ある消費財メーカーB社が、新製品開発のリードタイム短縮と、ターゲット顧客へのパーソナライズされたマーケティング施策の強化を目指していました。彼らは、社内の顧客購買データ、Webサイトのアクセスログ、SNSの投稿データ、そして外部の市場調査レポートやトレンド分析データといった、多種多様なデータソースを生成AIに連携させるための参照導線を構築しました。
この参照導線は、各データソースの特性(リアルタイム性、構造化の有無、信頼性など)を考慮し、AIが適切な情報源からデータを取得できるよう設計されました。例えば、市場トレンドの分析には外部の調査機関のレポートを優先的に参照させ、顧客の購買行動に関するインサイト抽出には社内のCRMデータを深く掘り下げるといった具合です。また、データの鮮度を保つために、リアルタイムデータ連携の仕組みも導入しました。
この取り組みにより、B社は以下のような成果を上げました。
- 新製品アイデアの創出: AIが市場の未充足ニーズや潜在的なトレンドを分析し、これまでにない製品コンセプトを提案。新製品開発の企画フェーズが約20%短縮されました。
- パーソナライズされたコンテンツ生成: 顧客の購買履歴やWeb行動データに基づき、AIが個別の顧客に最適化された広告コピーやメールコンテンツを自動生成。マーケティングキャンペーンのROIが平均15%向上しました。
- データドリブンな意思決定: 経営層は、AIが生成した市場分析レポートや競合比較レポートを基に、より迅速かつ客観的な意思決定が可能になりました。
ハーバード・ビジネス・レビューの調査によれば、データドリブンな意思決定を行う企業は、そうでない企業に比べて生産性が5〜6%高いと報告されています(出典:Harvard Business Review「The Value of Data-Driven Decision Making」)。生成AIと正しい参照導線は、このデータドリブン経営をさらに加速させる強力なツールとなるのです。
貴社が生成AIを導入する際も、単にツールを導入するだけでなく、その「参照導線」に徹底的にこだわり、ビジネスの各領域で具体的な成果を生み出すことを目指してください。私たち Aurant Technologies は、貴社の状況に合わせた最適な参照導線の設計から運用まで、一貫してサポートいたします。
まとめ:貴社のデータ資産を最大化し、AIを真のビジネスパートナーへ
生成AIの真価を引き出すデータ戦略の重要性
本記事を通じて、生成AIの出力精度がプロンプトの巧みさだけでなく、参照するデータの品質と構造に大きく依存することをご理解いただけたかと思います。特に、Retrieval Augmented Generation(RAG)のアーキテクチャが、まさにその真髄を突いています。RAGは、貴社が保有する膨大なデータ資産の中から、質問に最適な情報を検索・抽出し、それを基にAIが回答を生成する仕組みです(出典:一文读懂:大模型RAG(检索增强生成)含高级方法)。これにより、AIは常に最新かつ正確な情報に基づいて応答できるようになり、ハルシネーション(AIが事実に基づかない情報を生成すること)のリスクを大幅に低減できます。
しかし、このRAGの真価を引き出すためには、単にデータを集めるだけでは不十分です。データの品質、鮮度、そして適切な構造化が極めて重要になります。例えば、不正確なデータや古いデータが参照されれば、AIも誤った情報を出力してしまいます。また、データがばらばらの形式で保存されていたり、関連性が不明瞭であったりすれば、AIは必要な情報を効率的に見つけ出すことができません。
したがって、生成AIを真のビジネスパートナーとして活用するためには、以下のデータ戦略が不可欠です。
- データガバナンスの確立: データの定義、所有者、アクセス権限、品質基準などを明確にし、一元的に管理する体制を構築します。
- データの品質向上: 定期的なデータクレンジング、重複排除、整合性チェックを行い、データの正確性と信頼性を維持します。
- データの構造化と標準化: 非構造化データをAIが理解しやすい形式(例:ナレッジグラフ、ベクトルデータベース)に変換し、検索性を高めます。
- データの鮮度維持: リアルタイムに近い形でデータを更新し、AIが常に最新の情報にアクセスできる環境を整備します。
- 倫理的・法的側面への配慮: AIが生成するコンテンツの信頼性を確保するため、参照データの出所を明確にし、必要に応じてAI生成物であることを識別する仕組みを導入します。実際、多くの国でAI生成コンテンツの識別表示が義務化されつつあります(出典:我国出台新规,要求 AI 生成合成内容必须添加标识)。
これらの取り組みは、単にAIの精度を高めるだけでなく、貴社全体のデータ資産価値を向上させ、データドリブンな意思決定を加速させる基盤となります。データは貴社のビジネスにおける新たな「石油」であり、その精製と活用こそが、これからの競争優位性を確立する鍵となるでしょう。
Aurant Technologiesが提供する伴走型DX支援
生成AIの導入は、単なるツールの導入では終わりません。それは貴社の業務プロセス、データ活用文化、そしてビジネスモデルそのものに変革をもたらすDX(デジタルトランスフォーメーション)の一環です。私たち Aurant Technologies は、このような複雑なAI導入プロセスにおいて、貴社に寄り添い、具体的な成果へと導く伴走型DX支援を提供しています。
私たちの支援は、単に技術的なソリューションを提供するだけでなく、貴社のビジネス目標と現状の課題を深く理解することから始まります。データ戦略の策定、データ整備、RAGシステム構築、AIモデル選定、プロンプトエンジニアリング支援、そして効果測定と改善サイクルの確立まで、一貫してサポートします。当社の専門家チームは、データエンジニアリング、機械学習エンジニアリング、ビジネスコンサルティングの知見を融合させ、貴社に最適なオーダーメイドのソリューションを設計・実装します。
具体的な支援フェーズは以下の通りです。

| フェーズ | 主な内容 | 期待される成果 |
|---|---|---|
| 1. 戦略策定・要件定義 |
|
|
| 2. データ整備・基盤構築 |
|
|
| 3. RAGシステム構築・AIモデル選定 |
|
|
| 4. 運用・改善・定着化 |
|
|
私たちは、貴社が生成AIを単なるツールとしてではなく、持続的な競争優位性を生み出すための戦略的な資産として活用できるよう、全面的に支援いたします。貴社のデータ資産を最大限に活かし、AIを貴社のビジネス成長の強力なエンジンへと変えるお手伝いをさせてください。
次の一歩:無料相談で貴社のAI活用を具体化
生成AIの可能性は無限大ですが、その導入には専門的な知識と経験が求められます。貴社が抱える具体的な課題や、AIを活用して実現したい目標は、それぞれ異なるはずです。Aurant Technologies では、貴社の状況を深く理解し、最適なAI導入戦略をご提案するために、無料の個別相談会を実施しております。
この無料相談では、貴社の業務内容、既存のデータ資産、そしてAI活用に関するご期待を詳細にお伺いします。その上で、私たちが持つ豊富な知見と経験に基づき、貴社にとって最も効果的な生成AIの活用方法、RAGシステム構築のロードマップ、データ整備の具体的なステップなどについて、実践的なアドバイスを提供させていただきます。
「どこから手をつけて良いか分からない」「データが散在していてAI活用は難しいと考えている」「他社の成功事例を知りたい」といった疑問や不安をお持ちでしたら、ぜひ一度ご相談ください。貴社のデータ資産を最大化し、生成AIを真のビジネスパートナーへと育てるための一歩を、私たち Aurant Technologies と共に踏み出しましょう。お問い合わせフォームより、お気軽にご連絡ください。