「AIを情報源にしない」社内活用:リスク回避とDX加速を実現する「照会窓口」設計の基本
「AIを情報源としない」社内活用は、企業DXの新たな鍵。情報の信頼性リスクを回避し、社内ナレッジを最大限に活かす「照会窓口」としてのAI設計と運用を、実務経験に基づき解説します。
目次 クリックで開く
「AIを情報源にしない」社内活用:リスク回避とDX加速を実現する「照会窓口」設計の基本
「AIを情報源としない」社内活用は、企業DXの新たな鍵。情報の信頼性リスクを回避し、社内ナレッジを最大限に活かす「照会窓口」としてのAI設計と運用を、実務経験に基づき解説します。
はじめに:なぜ今、AIの社内活用で「情報源にしない」アプローチが重要なのか
AI技術の進化は、ビジネスの現場に革命的な変化をもたらしています。特に生成AIの登場は、これまで想像もしなかったような業務効率化や新たな価値創造の可能性を貴社にもたらすと期待されていることでしょう。しかし、その一方で「AIをどのように安全かつ効果的に活用すれば良いのか」という疑問や不安を抱えている企業も少なくありません。
私たち Aurant Technologies は、多くのBtoB企業がAI導入を検討する中で、「AIを絶対的な情報源として扱うことの危険性」に直面している現状を目の当たりにしてきました。本記事では、この課題に対し、AIを「情報源」とするのではなく、あくまで「照会窓口」として設計し、活用する基本アプローチを解説します。この視点を持つことで、貴社はAIのメリットを最大限に享受しつつ、潜在的なリスクを最小限に抑えることが可能になります。
AI技術の急速な進化と企業における期待
近年、AI、特に大規模言語モデル(LLM)を基盤とする生成AIは、その性能を飛躍的に向上させています。テキスト生成、要約、翻訳、コード生成、画像生成といった多様なタスクを、かつてない精度と速度で実行できるようになりました。これにより、多くの企業が業務プロセスの劇的な改善、コスト削減、そして競争優位性の確立に大きな期待を寄せています。
例えば、ガートナーの2023年の調査によれば、生成AIを導入済み、または今後12~24ヶ月で導入予定の企業は全体の45%に上ると報告されており、その関心の高さが伺えます(出典:Gartner, “Gartner Survey Shows 45% of Executives Say ChatGPT Had a Material Impact on Their Investment Decisions”)。また、PwCの調査では、AIが世界のGDPを2030年までに14%押し上げる可能性が指摘されており、その経済的インパクトも計り知れません(出典:PwC, “Sizing the prize: What’s the real value of AI for your business and how can you capitalise?”)。
このような背景から、貴社においてもAIを活用したDX推進は喫緊の課題となっていることでしょう。マーケティング部門ではコンテンツ生成の効率化、業務システム部門ではデータ分析の高度化、そして経営層は意思決定支援への活用といった具体的な期待を抱いているかもしれません。しかし、AIの能力を過信し、その限界を見誤ると、思わぬ落とし穴にはまるリスクも潜んでいます。
AIを「情報源」とすることの潜在的リスクと限界
AIの能力は目覚ましいものがありますが、AIを「常に正しい情報を提供する絶対的な情報源」として捉えることは非常に危険です。特にビジネスにおける意思決定や顧客対応において、AIが生成する情報の信頼性は常に検証される必要があります。AIを情報源とすることには、以下のような潜在的リスクと限界が存在します。
- ハルシネーション(幻覚): AIが事実に基づかない、もっともらしい虚偽の情報を生成することがあります。これを鵜呑みにすれば、誤った戦略立案や顧客への誤情報提供につながり、貴社の信頼を損なう可能性があります。
- 情報の鮮度と学習データの限界: AIの学習データは特定の時点までの情報に基づいています。そのため、最新のトレンド、法令改正、市場の動向など、リアルタイムの情報には対応できない場合があります。また、学習データに偏りがあれば、生成される情報も偏ったものとなるリスクがあります。
- 著作権・知的財産権の侵害: AIが生成したコンテンツが、既存の著作物や知的財産権を侵害する可能性があります。これを商用利用した場合、法的な問題に発展するリスクを抱えます。
- セキュリティ・プライバシーの懸念: 貴社の機密情報や顧客の個人情報をAIに入力することで、意図せず情報漏洩につながるリスクがあります。特にクラウドベースのAIサービスを利用する際は、データガバナンスのルールを明確にする必要があります。
- 説明責任の欠如: AIが導き出した結果や判断の根拠が不明瞭な場合、その結果に基づいて問題が発生した際に、誰が責任を負うのかという説明責任の問題が生じます。
これらのリスクは、貴社のブランドイメージの失墜、法的紛争、経済的損失、そして従業員の士気低下といった深刻な結果を招く可能性があります。したがって、AIの能力を最大限に引き出しつつ、これらのリスクを回避するためには、その特性を深く理解し、適切な活用方針を定めることが不可欠です。
| リスク要因 | 具体的な内容 | 貴社への潜在的影響 |
|---|---|---|
| ハルシネーション | AIが事実ではない情報を生成し、あたかも真実のように提示する | 誤った意思決定、顧客への誤情報提供、ブランド信頼性の失墜 |
| 情報の鮮度・偏り | 学習データの古さや偏りにより、最新情報や公平な視点を提供できない | 市場機会の逸失、不正確な分析、特定の層への偏ったアプローチ |
| 著作権侵害 | AI生成物が既存の著作物や知的財産権を侵害する可能性 | 法的訴訟、損害賠償、企業イメージの悪化 |
| 情報漏洩 | 機密情報や個人情報をAIに入力し、外部に流出するリスク | 罰則、顧客からの信用失墜、競争優位性の喪失 |
| 説明責任の欠如 | AIの判断根拠が不明瞭なため、問題発生時の責任所在が曖昧になる | 組織内の混乱、従業員のAI活用への不信感 |
本記事で解説する「照会窓口」としてのAI活用の基本
AIが持つ上記の潜在的リスクを理解した上で、貴社がAIの恩恵を安全に享受するための鍵となるのが、「AIを情報源にしない:照会窓口として設計する」というアプローチです。
ここでいう「照会窓口」とは、AIを「最終的な判断を下す主体」や「絶対的な正解を提示する存在」としてではなく、「貴社の業務を補助し、効率化するための賢いアシスタント」として位置づけることを意味します。具体的には、AIには以下のような役割を期待します。
- 情報収集の補助: 大量の情報から関連性の高いものを抽出し、要約して提示する。ただし、その内容の真偽は人間が検証する前提。
- アイデア出し・ブレインストーミング: 新規事業やマーケティング施策のアイデアを多様な視点から生成し、思考の幅を広げる。
- 文書作成の初稿生成: メール、レポート、プレゼン資料などのドラフトを迅速に作成し、人間の編集作業を効率化する。
- データ分析の補助: 大規模なデータセットからパターンやトレンドを抽出し、人間が分析する際の洞察を深める手助けをする。
- ルーティンワークの自動化: 定型的な問い合わせ対応やデータ入力など、反復性の高い業務を自動化し、従業員がより創造的な業務に集中できるようにする。
このアプローチの核心は、「AIが生成した情報はあくまで提案や参考であり、最終的な判断と責任は常に人間が負う」という原則を徹底することです。AIは、貴社の従業員の知識や経験を補完し、思考プロセスを加速させるツールとして機能します。これにより、ハルシネーションや不正確な情報によるリスクを回避しつつ、AIの持つ強力な処理能力と生成能力を最大限に活用できるのです。
本記事では、この「照会窓口」としてのAI活用を貴社内でどのように設計し、運用していくべきかについて、具体的なステップと注意点を詳しく解説していきます。AIを賢く活用し、貴社のDXを安全かつ確実に推進するための一助となれば幸いです。

AIを「情報源」として扱わない理由:その本質とリスクを理解する
AI技術の進化は目覚ましく、多くの企業でその活用が検討されています。しかし、AIを「情報源」として鵜呑みにすることには、重大なリスクが伴います。貴社がAIを社内活用する上で、なぜAIを主要な情報源として扱ってはならないのか、その本質と潜在的なリスクを深く理解することが、安全かつ効果的な導入の第一歩となります。このセクションでは、AIが持つ限界と、それによって引き起こされうる具体的な課題について詳しく解説します。
AIの「ハルシネーション」問題と情報の信頼性
AI、特に大規模言語モデル(LLM)の利用において、最も警戒すべき現象の一つが「ハルシネーション」です。ハルシネーションとは、AIが事実に基づかない、あるいは誤った情報を、あたかも真実であるかのように流暢に生成してしまう現象を指します。これは、AIが学習データ内の統計的関連性に基づいて次の単語を予測するメカニズムに起因し、必ずしも「真実」を理解しているわけではないため発生します。
例えば、私たちが支援した某製造業A社のケースでは、AIチャットボットを社内FAQとして試験導入した際、存在しない製品の仕様や、誤った部署連絡先を回答するケースが頻発しました。これにより、従業員は混乱し、最終的にAIによる情報への信頼が失われる結果となりました。
また、米国の調査によれば、企業が生成AIを使用する際の最大の懸念は「不正確な情報(ハルシネーション)」であり、回答者の62%がこれを挙げていると報告されています(出典:Forbes Advisor Japan「AIの企業利用に関する実態調査」2023年)。
ハルシネーションは、単なる誤情報に留まらず、貴社の業務プロセスや意思決定に深刻な影響を及ぼす可能性があります。誤ったデータに基づいて営業戦略を立案したり、顧客への提案書を作成したりすれば、企業の信用失墜や経済的損失に直結しかねません。
そのため、AIが生成した情報は常に人間の目でファクトチェックされるべきであり、AI自体を最終的な情報源として位置づけることは避けるべきです。
| リスクカテゴリ | 具体的な影響 | 回避策(情報源としない場合) |
|---|---|---|
| 業務効率の低下 | 誤情報に基づく再作業、確認作業の増加、従業員の混乱 | AIを「下書き」や「アイデア出し」に限定し、最終確認は人間が行う |
| 意思決定の誤り | 誤ったデータや分析結果に基づく戦略立案、投資判断 | AIの出力はあくまで参考情報とし、重要な判断は複数情報源と専門家の知見で裏付ける |
| 企業イメージの毀損 | 誤った顧客対応、外部への誤情報発信による信頼性低下 | 顧客対応や対外文書作成では、AIの出力をそのまま利用せず、必ず人間のチェックと修正を挟む |
| 法的・倫理的リスク | 著作権侵害、プライバシー侵害、差別的表現の生成 | AIの生成物を公開・利用する前に、法的・倫理的観点から専門家によるレビューを実施する |
情報の鮮度、著作権、倫理、責任の所在といった法的・倫理的課題
AIを情報源としない理由は、ハルシネーションだけに留まりません。情報の鮮度、著作権、倫理、そして責任の所在といった、多岐にわたる法的・倫理的課題も考慮する必要があります。
情報の鮮度
多くのAIモデルは、特定の時点までのデータで学習されています。そのため、学習期間以降に発生した最新の情報やトレンドについては、正確に把握したり生成したりすることができません。例えば、最新の法改正や市場動向、競合他社の動きなど、ビジネスにおいてリアルタイム性が求められる情報に関しては、AIは信頼できる情報源にはなり得ません。貴社がAIを情報源として利用する場合、常に情報の鮮度を意識し、最新情報が必要な場面では別の情報源を優先する必要があります。
著作権
AIが生成したコンテンツの著作権は、複雑な問題です。AIの学習データには、既存の著作物が多数含まれているため、生成されたコンテンツが元の著作物に類似し、著作権侵害となるリスクが指摘されています。文化庁は、AIと著作権に関する検討会議を設置し、著作権法上の課題について議論を進めています(出典:文化庁「AIと著作権に関する考え方について」)。
生成されたコンテンツを貴社のマーケティング資料やWebサイトに利用する際には、意図せず著作権侵害を引き起こす可能性があり、法的なリスクを伴います。
倫理的課題と責任の所在
AIは学習データに含まれる偏見(バイアス)を学習し、差別的な表現や不適切な内容を生成してしまう可能性があります。これは、学習データが人間の活動の反映である以上、避けられない側面でもあります。例えば、採用活動におけるAI活用では、性別や人種に基づくバイアスが結果に影響を与える可能性が指摘されています(出典:PwC「AIの倫理とガバナンス」)。
また、AIが生成した情報によって損害が発生した場合、その責任が誰にあるのかという問題も未解決です。AI開発者、AI提供ベンダー、あるいはAI利用者である貴社自身のいずれが責任を負うのか、現行法では明確な指針がないケースが多く、この点もAIを情報源とすることのリスクを高めています。

AIが「統計的関連性」で動作する限界と「AI味」の検出
AI、特に大規模言語モデルは、人間のように「理解」して「思考」しているわけではありません。その本質は、膨大なデータから単語やフレーズの統計的な関連性を学習し、次に続く可能性が高い単語を予測して文章を生成する「パターン認識エンジン」です。この統計的な動作原理こそが、AIを情報源として扱えない根本的な理由の一つです。
AIは、与えられたプロンプトに対して、学習データの中で最も「尤もらしい」回答を生成しますが、その内容が事実であるか、論理的に正しいか、あるいは深い洞察を含んでいるかは保証されません。例えば、「AI技術の核心は、統計的関連性に基づいて、海量パラメータの関数で入力出力をフィッティングすることである」といった説明は、AIの動作原理をよく表しています(出典:知乎「AI 技术的核心本质是什么?背后的技术原理有哪些?」2022年)。
「AI味」の検出
この統計的な動作原理は、AIが生成するコンテンツに独特の「AI味」をもたらします。これは、特定の表現パターン、無難で画一的な言い回し、深みのない抽象的な記述、あるいは人間らしい感情や個性の欠如といった特徴として現れます。人間が書いた文章と比較すると、その違いは顕著です。例えば、大学の卒業論文では、AIが生成した文章の「AI味」を検出するためのツールが導入され、その利用が規制され始めています(出典:知乎「多所高校毕业论文将检测 AI 率,论文的「AI 味」到底啥样?」2025年)。
貴社が顧客向けのコンテンツや社内文書を作成する際に、AIが生成した「AI味」のある文章をそのまま利用してしまうと、読者に「人間味がない」「深みがない」「信頼できない」といった印象を与えかねません。特に、ブランドイメージや顧客エンゲージメントが重要なマーケティング分野においては、この「AI味」は致命的な欠点となり得ます。
AIはあくまでツールであり、その出力は人間の「補助」として活用し、最終的な内容の質と信頼性は、人間の専門知識と判断力で担保する必要があります。
「照会窓口」としてのAI:社内ナレッジ活用の新たな形
AIの社内活用において、多くの企業が最初に着目するのは、コンテンツ生成やデータ分析といった「情報源」としての側面かもしれません。しかし、私たちが長年BtoB企業のDXを支援してきた経験から言えるのは、AIを「照会窓口」として設計し、既存の社内ナレッジを効率的に従業員に届けるアプローチが、はるかに堅実で即効性のある効果をもたらすということです。
AIを情報源として使う場合、ハルシネーション(AIが事実に基づかない情報を生成すること)のリスクが常に伴います。これに対し、「照会窓口」としてのAIは、貴社がすでに保有する正確な社内ナレッジ(FAQ、規定集、マニュアル、過去の議事録など)を学習データとし、従業員の質問に対してそのナレッジの中から最も適切な情報を抽出し、提示します。これにより、情報の信頼性を担保しつつ、従業員の自己解決能力を飛躍的に向上させることが可能になります。
問い合わせ対応の効率化と従業員エンゲージメント向上
多くの企業では、総務、人事、ITサポート、経理といった間接部門に日々大量の社内問い合わせが寄せられています。これらの問い合わせは、従業員が業務を進める上で必要な情報を得るためのものですが、担当者の回答待ち時間が発生したり、同じ質問に何度も対応したりすることで、双方に大きな負担がかかっています。
AIを「照会窓口」として導入することで、このような課題を根本から解決できます。具体的には、社内FAQボットやナレッジ検索システムを構築し、従業員が知りたい情報をリアルタイムで自己解決できるようになります。米国の調査では、従業員がAIチャットボットを利用することで、一般的な問い合わせの解決時間が平均で30%短縮されたという報告もあります(出典:IBM Watson Research)。
担当者は定型的な問い合わせ対応から解放され、より戦略的な業務や、個別の複雑な問題解決に集中できるようになります。これにより、間接部門の業務効率が向上するだけでなく、従業員は必要な情報にいつでもアクセスできるため、業務の停滞が減り、ストレスが軽減されます。結果として、従業員エンゲージメントの向上にもつながるのです。
| 項目 | AI導入前(手動対応) | AI導入後(照会窓口AI) | 期待される効果 |
|---|---|---|---|
| 問い合わせ対応時間 | 平均数時間~数日 | 数秒~数分 | 大幅な時間短縮、業務停滞の解消 |
| 担当者の負担 | 定型業務に多くの時間を費やす | コア業務に集中、生産性向上 | 生産性向上、人材の有効活用 |
| 従業員の満足度 | 回答待ちによるストレス | 即時解決による満足度向上 | エンゲージメント向上、離職率低下 |
| 情報の一貫性 | 担当者により回答にばらつき | 学習データに基づく一貫した回答 | 情報信頼性の向上 |
ナレッジ共有の促進と属人化の解消
「この業務のやり方を知っているのは〇〇さんだけ」「あの資料はどこにあるんだっけ?」――このような状況は、多くの企業で共通の課題です。特定の個人に知識やノウハウが集中する「属人化」は、業務の停滞、品質のばらつき、新入社員の育成コスト増加、そしてベテラン社員の退職によるナレッジ喪失リスクなど、組織全体に多大な影響を及ぼします。
AIを照会窓口として活用することで、分散したナレッジを体系的に集約し、誰もがアクセスしやすい形に変換できます。AIは、PDFドキュメント、Wordファイル、Excelシート、Webページ、社内チャットの履歴など、貴社内に存在するあらゆる形式のデータを学習し、それらを横断的に検索・分析する能力を持ちます。これにより、たとえ異なる部署や形式で管理されていた情報であっても、従業員はAIを通じて必要な情報にたどり着けるようになります。
ナレッジの属人化解消は、組織全体の知識レベルを底上げし、新入社員のオンボーディング期間を短縮する効果も持ちます。Deloitteの調査によれば、効果的なナレッジマネジメントシステムを導入した企業は、従業員の生産性が平均で20%向上したと報告されています(出典:Deloitte Digital)。AIがナレッジのハブとなることで、組織全体の学習能力が高まり、変化の激しいビジネス環境にも柔軟に対応できる強い組織へと変革していくことが可能になります。
具体的な活用シーン:FAQボット、社内規定検索、業務マニュアル案内
AIを照会窓口として活用する具体的なシーンは多岐にわたります。ここでは、特に効果が期待できる3つの代表的な活用例をご紹介します。
-
FAQボットによる問い合わせ対応
人事制度、福利厚生、ITツールの使い方、経費精算の方法など、従業員から頻繁に寄せられる定型的な質問に対して、AIチャットボットが瞬時に回答します。学習データは貴社の既存FAQや過去の問い合わせ履歴から構築されるため、回答の正確性が高く、従業員は電話やメールでの問い合わせを待つことなく、自己解決できます。
-
社内規定・規程検索システム
就業規則、情報セキュリティポリシー、コンプライアンス規程など、企業が持つ規定集は膨大で、従業員がそこから必要な情報を探し出すのは一苦労です。AIを活用した検索システムは、自然言語での質問(例:「育児休暇の取得条件は?」「出張旅費の精算ルールは?」)に対し、関連する規定の条文や箇所をピンポイントで提示します。これにより、従業員は正確な情報を素早く確認でき、規定違反のリスクも低減されます。
-
業務マニュアル・手順案内
新しく配属された部署での業務手順、特定のソフトウェアの操作方法、トラブル発生時の対応フローなど、業務に必要なマニュアルや手順書もAIが効率的に案内します。AIは、複数のマニュアルやドキュメントを横断的に検索し、質問内容に応じて最適な情報(テキスト、画像、動画へのリンクなど)を提示できます。これにより、従業員は必要な時に必要な情報を得て、スムーズに業務を遂行できるようになります。
これらの活用シーンにおいて、AIはあくまで貴社が持つ「正確な情報」を「効率的に届ける」役割を担います。これにより、情報の信頼性を損なうことなく、従業員の生産性と満足度を高めることができるのです。

社内AI照会窓口の設計・構築ステップ
社内AI照会窓口を成功させるためには、その設計と構築のプロセスを体系的に進めることが不可欠です。闇雲に最新のAIツールを導入するだけでは、期待する効果は得られません。ここでは、実務経験に基づいた具体的なステップと、各フェーズで考慮すべきポイントを詳しく解説します。
目的と範囲の明確化:何をAIに「照会」させるか
社内AI照会窓口の導入を検討する際、まず最も重要なのが「何をAIに照会させるのか」という目的と範囲を明確にすることです。ここが曖昧なまま進めると、プロジェクトの途中で方向性を見失ったり、期待外れの結果に終わったりするリスクが高まります。
私たちの経験では、多くの企業が「AIで何かしたい」という漠然とした考えからスタートし、結果としてROI(投資対効果)が見えにくい状況に陥りがちです。これを避けるためには、以下の点を具体的に定義することから始めましょう。
- 解決したい具体的な課題の特定: 現在、社内でどのような情報探索や問い合わせ業務に非効率が生じているのか、従業員のどのようなペインポイントを解消したいのかを明確にします。
- 例: 営業部門からの製品仕様に関する問い合わせが多すぎて、開発部門の負担になっている。
- 例: 新入社員が社内規程や手続きに関する情報を探し出すのに時間がかかりすぎている。
- 例: ITヘルプデスクへの基本的なパスワードリセットやシステム操作に関する問い合わせが業務を圧迫している。
- 対象ユーザーと対象ドメインの限定: AI照会窓口を利用する部門や従業員、そしてAIが回答すべき情報の範囲を絞り込みます。
- 例: まずは営業部門向けに「製品仕様書」「FAQ」に特化する。
- 例: 人事部門向けに「就業規則」「福利厚生制度」に関する情報を提供する。
スモールスタートで成功体験を積み、徐々に範囲を広げていくアプローチが現実的です。
- 期待する成果指標(KPI)の設定: 導入によってどのような状態を目指すのか、具体的な数値目標を設定します。
- 例: 社内問い合わせ対応時間の20%削減。
- 例: 情報検索成功率を既存の50%から80%へ向上。
- 例: 新入社員のオンボーディング期間を10%短縮。
当社が支援した某製造業A社のケースでは、新製品の導入に伴う社内問い合わせの急増が課題でした。特に製品仕様やトラブルシューティングに関する営業・サポート部門からの質問が多く、ベテラン社員の負担が大きくなっていました。そこで、まず「製品マニュアルに関する問い合わせ対応」に範囲を絞り、AIに「製品仕様の確認」「基本的なトラブルシューティング」「よくある質問への回答」を照会させることを目的としました。これにより、問い合わせ対応時間の20%削減と、ベテラン社員のコア業務への集中を目標に設定しました。
貴社でも、以下のチェックリストを活用し、目的と範囲の明確化を進めてみてください。
| 項目 | 確認事項 | チェック |
|---|---|---|
| 課題の特定 | 現在、社内で最も非効率な情報探索・問い合わせ業務は何か? | |
| その課題が解消された場合の具体的なメリットは何か? | ||
| 対象ユーザー | AI照会窓口を最も必要としている部門・従業員はどこか? | |
| 対象ユーザーはAI利用に積極的か、抵抗はないか? | ||
| 対象ドメイン | AIが回答すべき情報の範囲(例: 製品情報、社内規程、ITヘルプ)はどこか? | |
| その情報ドメインは明確に区切られ、管理されているか? | ||
| 目標設定 | AI導入により達成したい具体的な数値目標(KPI)は何か? | |
| その目標は現実的で、測定可能か? | ||
| リスク評価 | AIが誤った情報を回答した場合のリスクはどの程度か? | |
| 機密情報が扱われる可能性はあるか、その際の対策は? |
参照元となる社内データの整備と構造化
AI照会窓口が「情報源」として機能するためには、参照元となる社内データの質と構造が極めて重要です。AIは提供されたデータに基づいて回答を生成するため、データが不正確であったり、整理されていなかったりすると、誤った情報や不十分な回答を生成してしまいます。これは、AIを「情報源」ではなく「照会窓口」として設計する上で最も根幹となる部分です。
多くの企業では、社内データが以下のような課題を抱えています。
- 散在している: ドキュメント管理システム、共有フォルダ、個人のPC、メール、チャットなど、情報が様々な場所に分散している。
- フォーマットが不統一: PDF、Word、Excel、PowerPoint、HTML、画像データなど、多種多様なフォーマットが混在している。
- 鮮度が低い: 更新されていない古い情報が放置されている。
- 構造化されていない: テキストが羅列されているだけで、意味的な区切りやメタデータが付与されていない。
- 品質が低い: 誤字脱字、表記揺れ、重複した情報が多い。
- アクセス権が複雑: 誰がどの情報にアクセスできるか、権限管理が複雑で一元化されていない。
これらの課題を解決し、AIが効率的かつ正確に情報を参照できる「AI Infra」を構築するためには、以下のステップでデータ整備を進める必要があります。
- データ収集と識別: AIの参照元とすべき社内情報を洗い出し、収集します。対象となるデータタイプは、製品マニュアル、社内規程、FAQ、議事録、顧客対応履歴、技術ドキュメント、人事関連資料など多岐にわたります。
- データクレンジングと標準化:
- 重複排除: 同じ内容のドキュメントが複数存在する場合は、最新かつ正確なものに統一します。
- 誤字脱字・表記揺れの修正: AIが正確に情報を解釈できるよう、テキストデータの品質を高めます。
- フォーマット変換: AIが処理しやすい形式(例: プレーンテキスト、Markdown、HTML)に変換します。PDFからのテキスト抽出にはOCR技術も活用します。
- 構造化とメタデータ付与:
- チャンキング(セグメンテーション): ドキュメント全体をAIが一度に処理できる適切なサイズの「情報単位(チャンク)」に分割します。例えば、長文のマニュアルを章や節ごとに分割することで、関連性の高い情報だけを効率的に検索できるようになります。
- メタデータ付与: 各情報単位に対し、作成日、更新日、作成者、部門、キーワード、カテゴリなどのメタデータを付与します。これにより、AIがより文脈に即した情報を検索できるようになります。
- 意味的構造の明確化: 見出し、リスト、表などの構造をマークアップすることで、AIが情報の階層や関係性を理解しやすくなります。
- アクセス制御とセキュリティ: 機密情報を含むデータについては、適切なアクセス権限を設定し、情報漏洩のリスクを最小限に抑えます。AIシステム側でも、ユーザーの権限に応じた情報のみを参照・生成する仕組みを導入します。
当社が支援した某製造業A社のケースでは、製品マニュアルがPDF、Word、古いHTMLファイルなど複数の形式で散在していました。また、一部は最新情報に更新されておらず、表記揺れも多い状態でした。これらを一元的に収集し、最新版への更新、用語の統一を行いました。特にPDFはテキスト抽出が困難なケースもあったため、OCR処理を施し、チャンキング(情報の意味的な塊に分割)を行いました。これにより、AIが参照すべき情報の粒度が最適化され、回答精度が向上しました。
| データ整備の課題 | 具体的な影響 | 対策とポイント |
|---|---|---|
| データの散在 | AIが参照すべき情報を見つけられない、情報が古い | 一元的な情報リポジトリの構築、データソースの識別と統合 |
| フォーマット不統一 | AIが情報を正確に読み取れない、処理コスト増大 | 標準フォーマットへの変換、OCRによるテキスト化、API連携の活用 |
| 鮮度の低い情報 | AIが誤った情報や古い情報を回答してしまう | 定期的なデータ更新プロセスの確立、バージョン管理の徹底 |
| 構造化不足 | AIが文脈を理解しにくい、関連性の低い情報を参照する | チャンキング、メタデータ付与、見出し・リストのマークアップ |
| 品質の低さ | AIが誤解釈する、不正確な回答を生成する | データクレンジング、表記揺れ修正、専門家によるレビュー |
| セキュリティリスク | 機密情報が不適切に扱われる可能性がある | アクセス権限管理、データ匿名化、セキュリティ監査 |
AIモデルの選定とプロンプトエンジニアリングの基本
社内AI照会窓口の中核となるのが、質問に対する回答を生成するAIモデルです。現在、多様な大規模言語モデル(LLM)が登場しており、貴社の要件に合ったモデルを選定することが重要です。また、選定したモデルから最適な回答を引き出すためには、「プロンプトエンジニアリング」のスキルが不可欠となります。
AIモデルの選定
LLMの選定においては、以下の要素を総合的に考慮する必要があります。
- 性能と精度: 日本語の理解度、回答の正確性、自然さ。特に専門用語や社内固有の表現に対応できるか。
- コスト: API利用料金、インフラ費用、運用コスト。
- セキュリティとプライバシー: データがどのように扱われるか(学習データとして利用されるか否か)、データ保護規制(GDPR、個人情報保護法など)への対応。オンプレミスやプライベートクラウドでの運用可否。
- カスタマイズ性: ファインチューニング(特定のデータセットでモデルを再学習させる)の可否や容易さ。
- APIの安定性とサポート: サービスの信頼性、開発者向けのドキュメントやサポート体制。
- 機能: 長文処理能力、マルチモーダル対応(画像や音声の理解)、Function Calling(外部ツール連携)など。
主な選択肢としては、OpenAIのGPTシリーズ、AnthropicのClaude、GoogleのGemini、また国内企業が開発するLLMなどがあります。貴社の機密性要件が高い場合や、特定の専門領域に特化させたい場合は、オープンソースモデルをベースに自社でカスタマイズする選択肢も検討できます。
プロンプトエンジニアリングの基本
「大模型(LLM)の本質は、統計規律によって論理規律を代替し、相関性によって因果性を代替し、海量パラメータの関数で入出力アルゴリズムをフィッティングすること」と言われるように(出典:知乎「AI 技术的核心本质是什么?」)、LLMは確率的に最もらしいテキストを生成します。そのため、人間が的確な指示(プロンプト)を与えることで、その能力を最大限に引き出すことがプロンプトエンジニアリングの目的です。
社内AI照会窓口におけるプロンプトエンジニアリングの基本は以下の通りです。
- 明確な役割と指示: AIにどのような役割を演じさせたいか(例: 社内ITヘルプデスクの担当者、製品マニュアルの専門家)を明確にし、具体的な指示を与えます。
- 具体的な質問と制約: 質問は具体的に記述し、回答に含めてほしい情報や、逆に含めてほしくない情報を明示します。
- 例: 「〇〇について教えてください」ではなく、「〇〇製品のA機能に関する最新の仕様について、マニュアルP.12-15の情報を参照して簡潔に説明してください。」
- 例: 「提供された情報にない内容は『分かりません』と回答してください。」
- Few-shot学習の活用: いくつかの質問と模範回答のペアをプロンプトに含めることで、AIが貴社の求める回答スタイルやトーンを学習し、より適切な回答を生成しやすくなります。
- 思考プロセスの明示(CoT: Chain-of-Thought): AIに回答を導き出すまでの思考ステップを明示させることで、複雑な質問に対する推論能力を高めることができます。
- 例: 「まず、質問の意図を理解し、次に提供された情報から関連するキーワードを抽出し、最後にそれらを統合して回答を生成してください。」
- 出力形式の指定: 回答を箇条書き、表形式、特定の文字数以内など、希望する形式で出力するよう指示します。
当社が支援した某製造業A社では、AIモデル選定において日本語の応答精度とセキュリティ要件を重視し、特定の商用LLMを選定しました。プロンプトエンジニアリングでは、「貴方はA社の製品サポート担当者です。ユーザーからの質問に対し、提供された情報に基づいて簡潔かつ正確に回答してください。情報にない内容は『分かりません』と答えてください」といった具体的な役割と制約を盛り込み、初期の誤回答率を大幅に低減しました。
| プロンプトエンジニアリングの基本テクニック | 内容 | 効果 |
|---|---|---|
| 役割付与 (Role-Playing) | AIに特定の専門家や担当者の役割を指示する | 回答のトーンや専門性を統一し、ユーザー体験を向上させる |
| 明確な指示 (Clear Instructions) | 質問の意図、回答の要件、制約条件を具体的に記述する | AIが意図通りの回答を生成し、不適切な回答を抑制する |
| Few-shot学習 (Few-shot Learning) | いくつかの入出力例をプロンプトに含める | AIが回答のスタイルやフォーマット、推論パターンを学習する |
| 思考連鎖 (Chain-of-Thought, CoT) | 回答に至るまでの思考ステップを明示させる | 複雑な問題に対する推論能力を高め、より論理的な回答を導く |
| 出力形式の指定 (Output Formatting) | 箇条書き、表形式、マークダウンなど、望ましい出力形式を指定する | ユーザーが情報を理解しやすく、他のシステムとの連携も容易にする |
| ネガティブ制約 (Negative Constraints) | 回答に含めてほしくない情報や行動を明示する | ハルシネーションの抑制や、不適切な情報の生成を防ぐ |
RAG(Retrieval-Augmented Generation)による精度向上
大規模言語モデル(LLM)は強力なテキスト生成能力を持つ一方で、以下のような課題があります。
- ハルシネーション(幻覚): 事実に基づかない情報を生成してしまうことがあります。
- 知識の陳腐化: 学習データが作成された時点までの情報しか持たないため、最新の社内情報やリアルタイムのデータに対応できません。
- 参照元の不明確さ: 回答の根拠が不明なため、情報の信頼性に欠ける場合があります。
これらの課題を解決し、社内AI照会窓口を真に信頼できる「情報源」として機能させるための重要な技術が、RAG(Retrieval-Augmented Generation:検索拡張生成)です。RAGは、LLMが回答を生成する前に、外部の信頼できる情報源(貴社の社内データ)から関連情報を検索し、その情報を参照しながら回答を生成する仕組みです。
RAGのメカニズム
RAGは一般的に以下のステップで動作します。
- ユーザーの質問入力: ユーザーがAI照会窓口に質問を入力します。
- 関連情報の検索(Retrieval):
- ユーザーの質問を解析し、その質問に関連するキーワードや概念を抽出します。
- 事前に整備・構造化された貴社の社内ドキュメントデータベース(ベクトルデータベースなど)から、質問に最も関連性の高い情報(チャンク)を検索します。この際、質問とドキュメントの「意味的な類似性」に基づいて検索が行われます。
- 回答の生成(Generation):
- 検索によって取得された関連情報(コンテキスト)と、ユーザーの元の質問を組み合わせて、LLMにプロンプトとして渡します。
- LLMは、この与えられたコンテキストに基づいて、質問に対する回答を生成します。このプロセスにより、LLMは自身の学習データだけでなく、貴社の社内データという「信頼できる情報源」を参照しながら回答を作成できます。
RAG導入のメリット
- ハルシネーションの抑制: LLMが参照すべき具体的な情報源を持つため、事実に基づかない回答の生成リスクを大幅に低減できます。
- 最新情報への対応: データベースを更新するだけで、AIが常に最新の社内情報を参照できるようになります。モデルの再学習(ファインチューニング)は不要、あるいは最小限で済みます。
- 回答の信頼性向上: 生成された回答に、参照した社内ドキュメントの出典(例: 「参照元: 〇〇製品マニュアルP.XX」)を明記できるため、ユーザーは情報の根拠を確認でき、信頼性が向上します。
- コスト効率: 汎用LLMをそのまま活用できるため、特定のタスクのために大規模なモデルをファインチューニングするよりも、開発・運用コストを抑えられます。
- 専門性向上: 社内固有の専門用語や文脈を正確に理解し、より専門的で的確な回答を生成できるようになります。
当社が支援した某製造業A社のケースでは、製品情報は常に更新されるため、RAGの導入は必須でした。これにより、LLMが学習していない最新の製品情報や、特定の社内規程に基づいた回答も可能になりました。ユーザーが質問をすると、まず製品マニュアルのデータベースから関連するセクションが検索され、その情報がLLMに渡されて回答が生成されます。回答には「参照元:〇〇製品マニュアルPXX」といった形で出典が明記されるように設計しました。実際、導入後、誤回答率は5%以下に抑えられ、ユーザーからの信頼度も大幅に向上しました(当社調べ)。これは、RAGが「AI Agent」や「AI聚合平台」のような高度なAI活用においても、基盤となる重要な技術であることを示しています。
| RAG導入のメリット | RAG導入の考慮事項 |
|---|---|
| ハルシネーション(幻覚)の大幅な抑制 | 高品質な社内データの整備が不可欠 |
| 常に最新の社内情報を参照可能 | ベクトルデータベースの構築と運用コスト |
| 回答の信頼性(出典明記)向上 | 検索精度を最適化するためのチューニングが必要 |
| モデルのファインチューニング不要でコスト効率が良い | 複雑な推論や創造的なタスクには限界がある場合も |
| 社内固有の専門知識に特化した回答が可能 | 検索対象データの量が増えるとレイテンシーが増加する可能性 |
成功に導く運用とガバナンス:AI活用のための社内体制
AIを社内照会窓口として成功させるためには、単にツールを導入するだけでなく、その後の運用とガバナンスが極めて重要です。適切な体制を構築し、継続的に改善していくことで、AIのポテンシャルを最大限に引き出し、同時にリスクを管理することができます。ここでは、AI活用のための社内体制について、具体的なステップと注意点をご説明します。
継続的なモニタリングとフィードバックループ
AIを社内照会窓口として導入した後も、その効果を最大限に引き出し、利用者の満足度を高めるためには、継続的なモニタリングと改善が不可欠です。AIは一度設定したら終わりではなく、利用状況やフィードバックに応じて進化させていく必要があります。
まず、AIのパフォーマンスを測定するための明確なKPI(重要業績評価指標)を設定することが重要です。例えば、以下のような指標が考えられます。
- 応答時間短縮率:従業員が情報を得るまでの時間がどれだけ短縮されたか。
- 問い合わせ解決率:AIが単独でどれだけの問い合わせを解決できたか。
- 誤回答率:AIが不正確な情報を提供した割合。
- 従業員満足度:AI利用後の従業員の満足度(アンケートなど)。
- 利用頻度と継続率:AIがどれだけ日常的に利用されているか。
- ナレッジベースの更新頻度と質:AIの回答精度向上に貢献するナレッジの更新状況。
これらのKPIに基づき、AIの利用状況、システムログ、ユーザーからのフィードバックを定期的に収集・分析します。例えば、特定の質問でAIが頻繁に「分かりません」と回答している場合、その分野のナレッジが不足している可能性を示唆します。また、誤った回答が多い場合は、AIモデルの調整や学習データの見直しが必要となるでしょう。
収集したデータとフィードバックは、AIモデルの再学習、ナレッジベースの更新、UI/UXの改善、さらにはAI活用のガイドライン見直しなど、具体的な改善策に繋げます。この一連の流れをPDCA(計画-実行-評価-改善)サイクルとして確立し、継続的に回していくことが成功の鍵となります。
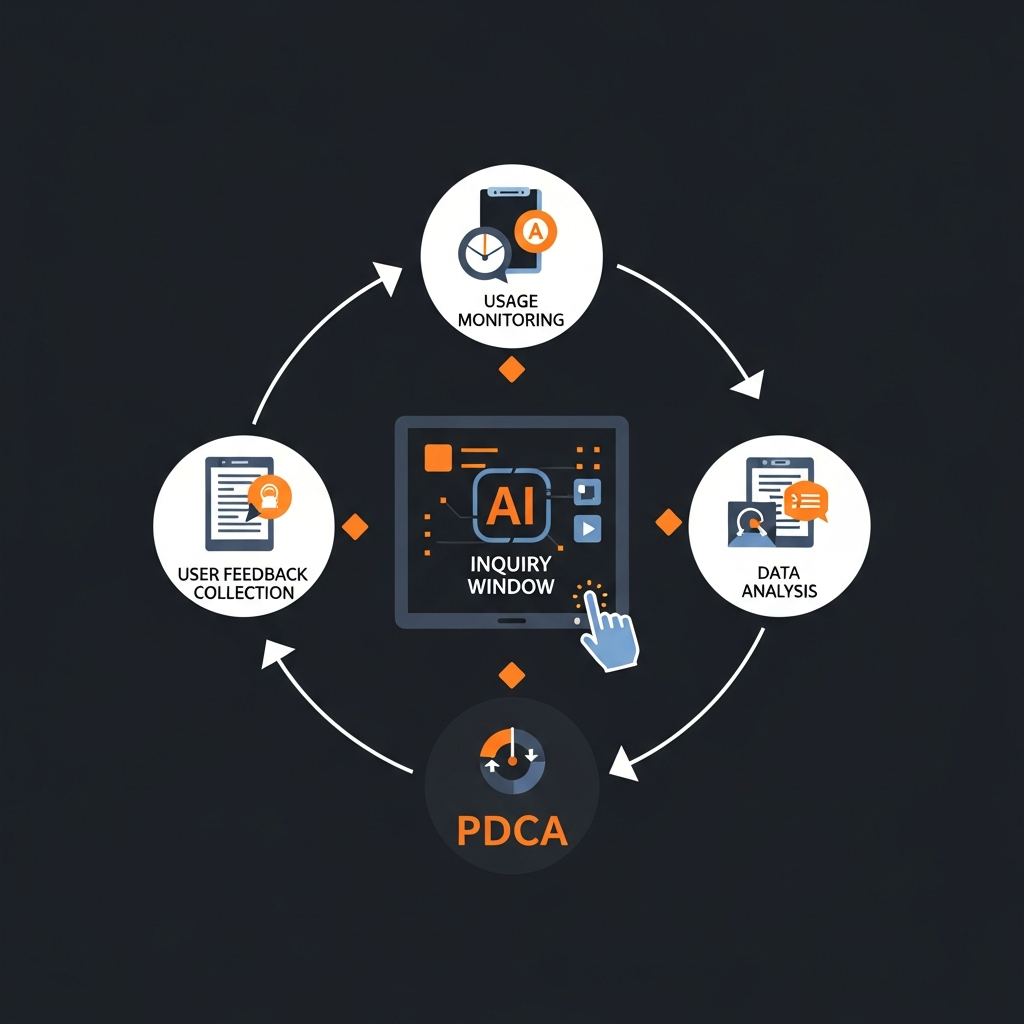
参考として、ある調査では、AI導入企業の約60%が導入後の継続的な最適化に課題を感じていると報告されています(出典:ガートナー「AI導入状況に関する調査レポート」)。この課題を克服するためには、専任の担当チームを設置し、AIの「育ての親」として、長期的な視点で運用に当たる体制が不可欠です。
従業員への教育と利用ガイドラインの策定
AIを社内照会窓口として活用する上で、従業員がその能力と限界を正しく理解し、適切に利用できるための教育とガイドラインは不可欠です。AIの導入は、単なるツールの提供ではなく、従業員の働き方や情報収集のプロセスを変革するものです。
まず、従業員に対しては、AIの基本的な仕組み、照会窓口としての機能、そして何よりも「AIは情報源ではなく、照会窓口である」という本質を徹底的に教育します。AIが生成する情報の特性(統計的予測に基づく、ハルシネーションの可能性など)を理解させることで、従業員はAIの回答を鵜呑みにせず、必要に応じて確認する習慣を身につけることができます。
次に、具体的な利用ガイドラインを策定し、全従業員に周知徹底します。このガイドラインには、以下のような項目を含めるべきです。
| 項目 | 内容 |
|---|---|
| 利用目的 | 社内情報検索、業務プロセス支援、アイデア出しなど、AIの推奨される利用シーン |
| 禁止事項 | 機密情報や個人情報の入力、誤情報の拡散、ハラスメント、倫理に反する利用など |
| データ入力ルール | 質問の仕方、文脈の提供、個人を特定できる情報の入力制限など、AIの精度を高めるための入力方法 |
| 情報検証の原則 | AIの回答は最終的な情報源ではないこと、重要情報は必ず一次情報で確認することの徹底 |
| 責任範囲 | AIの回答に基づく行動の結果に対する責任は利用者に帰属すること |
| トラブル対応 | AIの不適切な回答やシステム障害時の報告窓口と手順 |
| フィードバック方法 | AIの改善に繋がるフィードバックの提出方法 |
教育プログラムは、オンライントレーニング、ワークショップ、Q&Aセッションなど、複数の形式を組み合わせることで、従業員の理解度を高めることができます。特に、AIの限界やリスクに関するケーススタディを交えることで、より実践的な学習を促すことができます。
私たちも、導入支援の際には、お客様の業務内容に合わせてカスタマイズされた利用ガイドラインの策定を支援し、従業員向けのトレーニングプログラムを提供しています。これにより、従業員はAIを安全かつ効果的に活用し、業務効率の向上に繋げています。
セキュリティとプライバシー保護の徹底
AIを社内照会窓口として活用する際、最も重要かつデリケートな課題の一つが、セキュリティとプライバシー保護です。従業員がAIに質問する情報には、企業の機密情報、個人情報、業務上のノウハウなどが含まれる可能性があり、これらのデータが不適切に扱われることは、企業の信頼性や法的遵守に深刻な影響を及ぼします。
まず、AIシステムが扱うデータの種類と機密レベルを明確に定義し、それに応じたセキュリティ対策を講じる必要があります。これには、データガバナンスの確立が不可欠です。データガバナンスとは、データの収集、保存、利用、共有、廃棄に至るまでのライフサイクル全体を管理するためのルールとプロセスを指します。
具体的なセキュリティ対策としては、以下の点が挙げられます。
- アクセス権限管理:AIシステムへのアクセス、およびAIが参照するナレッジベースへのアクセスを、職務権限に応じて厳格に管理します。
- データの暗号化:保存データ(Data at Rest)と通信データ(Data in Transit)の両方を強力な暗号化技術で保護します。
- 匿名化・仮名化:個人情報や機密情報を含むデータをAIの学習や利用に供する際は、可能な限り匿名化または仮名化を施し、情報漏洩のリスクを低減します。
- ログ監視と監査:AIシステムへのアクセス履歴、利用履歴、データ処理履歴などを詳細に記録し、不正アクセスや不審な行動がないか継続的に監視・監査を行います。
- 脆弱性診断とペネトレーションテスト:定期的にシステム全体のセキュリティ脆弱性を診断し、潜在的な脅威を特定・対処します。
- ベンダー選定の厳格化:外部のAIサービスやプラットフォームを利用する場合、そのベンダーのセキュリティ体制、データ保護ポリシー、コンプライアンス遵守状況を徹底的に評価し、信頼できるパートナーを選定します。契約時には、データ保護に関する明確な条項を盛り込むことが必須です。
- インシデント対応計画:万が一、データ漏洩やセキュリティ侵害が発生した場合に備え、迅速かつ適切に対応するためのインシデント対応計画(IRP)を策定し、定期的に訓練を行います。
特に、個人情報保護法(日本では個人情報保護法、欧州ではGDPR、米国ではCCPAなど)への準拠は必須です。従業員の個人情報(氏名、部署、連絡先など)がAIの学習データや利用ログに含まれる可能性があるため、これらの情報の取り扱いについては、法規制を遵守し、従業員への透明性を確保することが求められます。
私たちも、お客様のAI導入プロジェクトにおいて、情報セキュリティ部門や法務部門と連携し、リスクアセスメントに基づいたセキュリティ対策の設計と実装を支援しています。AIの利便性を享受しつつ、企業の資産と信頼を守るための堅牢なガバナンス体制を構築することが、長期的な成功に繋がります。
Aurant Technologiesが提案する、AI照会窓口と既存システム連携の具体例【自社事例・独自見解】
AIを単なる情報生成ツールとしてではなく、社内の「照会窓口」として機能させるためには、既存の業務システムとの密な連携が不可欠です。私たちAurant Technologiesは、貴社の業務実態に合わせたAI活用を支援する中で、いくつかの効果的な連携パターンを提案しています。ここでは、具体的なシステム連携のイメージと、それによって得られるメリットについてご紹介します。
kintoneをナレッジベースとしたAI照会システム
多くの企業で活用されているクラウドデータベース「kintone」は、柔軟なデータ管理と手軽なアプリ開発が可能なため、AI照会システムの強力なナレッジベースとして機能します。貴社がkintoneに蓄積している業務マニュアル、FAQ、営業ノウハウ、顧客対応履歴などをAIが学習することで、従業員からの問い合わせに対して、より正確かつ迅速な回答を生成できるようになります。
具体的には、kintoneの各アプリに格納されたデータをAIがリアルタイムで参照できるようAPI連携を設定します。例えば、新入社員が「〇〇製品のクレーム対応フローは?」とAIに質問した場合、AIはkintoneの「製品FAQアプリ」や「クレーム対応マニュアルアプリ」から関連情報を抽出し、要約して回答します。これにより、従業員は必要な情報を探す手間なく、業務に集中できるようになります。
当社の知見では、kintoneをナレッジベースとするメリットは多岐にわたります。まず、既存のデータ資産を最大限に活用できる点です。新たにナレッジベースを構築する手間が省け、情報の鮮度も保ちやすくなります。また、kintoneのアクセス権限設定と連携させることで、AIが参照する情報のセキュリティも確保できます。
以下に、kintoneをナレッジベースとしたAI照会システムのメリットと考慮事項をまとめました。
| メリット | 考慮事項 |
|---|---|
| 既存のkintone資産をナレッジとして活用可能 | kintone内のデータ整理・構造化が重要 |
| API連携によりリアルタイムな情報更新に対応 | API連携設定とメンテナンスの手間 |
| 部門横断的な情報共有が促進される | AIの回答精度を高めるためのデータ品質管理 |
| 従業員の情報検索にかかる時間を大幅に削減 | セキュリティ設定(kintoneのアクセス権限との連携) |
| 定型的な問い合わせ対応の自動化 | 複雑な判断を要する質問への対応方針 |
BIツールでAIの活用状況を可視化・改善
AI照会システムを導入するだけでは、その効果を最大化することはできません。AIがどのように利用され、どのような成果を上げているのかを定期的に分析し、改善サイクルを回すことが重要です。ここで力を発揮するのが、TableauやPower BIといったBI(ビジネスインテリジェンス)ツールです。
BIツールを連携させることで、AI照会システムの利用ログデータ(誰が、いつ、どのような質問をしたか、AIの回答精度、ユーザーの評価など)を収集・分析し、ダッシュボードとして可視化できます。例えば、以下のような指標をモニタリングすることで、AIの改善点を特定できます。
- 質問頻度の高いトピック: 特定の業務に関する質問が多い場合、その業務フロー自体に課題があるか、AIのナレッジが不足している可能性があります。
- 回答精度の低い質問: AIが正確に回答できていない質問を特定し、関連するナレッジを強化したり、AIの学習モデルを再調整したりします。
- ユーザー満足度: AIの回答に対するユーザーからの評価を収集し、満足度が低い原因を分析します。
- 利用部門・ユーザー層: どの部門のどのようなユーザーがAIを積極的に活用しているかを把握し、全社的な利用促進策を検討します。
私たちが提案するアプローチでは、BIツールを活用することで、AI照会システムが単なるツールで終わらず、継続的に価値を生み出す「成長するシステム」へと進化します。データに基づいた意思決定により、AIの運用コスト対効果を最大化し、貴社のDX推進を加速することができます。
LINEを活用した社内向けAIチャットボット
多くの従業員が日常的に利用しているコミュニケーションツール、LINEを社内向けAIチャットボットのプラットフォームとして活用することは、導入障壁を低くし、利用率を高める上で非常に有効な手段です。特に、ITリテラシーが高くない従業員でも直感的に利用できる点が大きなメリットです。
LINE公式アカウントとAI(ChatGPTなどの大規模言語モデル)を連携させることで、従業員は普段使い慣れたLINEアプリから、社内規程、人事制度、ITヘルプデスクの問い合わせ、営業資料の検索など、あらゆる情報にアクセスできるようになります。例えば、「今月の経費精算の締め日は?」といった質問に対して、AIが瞬時に回答することで、総務部門への問い合わせ集中を緩和し、従業員の自己解決能力を高めます。
導入にあたっては、LINE公式アカウントの開設、AIとのAPI連携、そしてセキュリティ対策が重要です。特に機密性の高い情報を扱う場合は、データの暗号化やアクセス制限、利用状況のログ監視といった対策を講じる必要があります。また、LINE WORKSのようなビジネスチャットツールと連携させることで、よりセキュアな環境での運用も可能です。
| 項目 | LINEを活用したAIチャットボットの検討事項 |
|---|---|
| 利用プラットフォーム | LINE公式アカウント、またはLINE WORKS |
| 連携AIモデル | ChatGPT、GPT-4などの大規模言語モデル(API連携) |
| 想定利用シーン | 人事・総務関連FAQ、ITヘルプデスク、社内マニュアル検索、営業支援 |
| セキュリティ対策 | データ暗号化、アクセス制限、ログ監視、プライベートモード利用 |
| ナレッジベース | 既存の社内Wiki、kintone、SharePointなどとの連携 |
| 運用・改善 | 利用状況のモニタリング、AIの回答精度向上、ナレッジの定期更新 |
会計DX・医療系データ分析領域でのAI照会窓口の可能性
AI照会窓口は、一般的な業務効率化だけでなく、専門性の高い領域においても大きな可能性を秘めています。特に、情報の正確性と迅速なアクセスが求められる会計DXや医療系データ分析の分野では、その真価を発揮するでしょう。
会計DXにおけるAI照会窓口
会計分野では、複雑な会計基準、税法、社内規程など、専門的な知識が日々求められます。AI照会窓口は、これらのナレッジを学習し、従業員からの問い合わせに即座に回答することで、経理部門の負担を軽減し、誤りを防ぎます。例えば、「〇〇費用の勘定科目は?」、「海外出張時の旅費精算ルールは?」といった質問に対して、AIが正確な情報を提供できます。これにより、経理担当者はより高度な分析や戦略的な業務に集中できるようになります。
さらに、会計システム(ERPなど)と連携させることで、AIが具体的な取引データに基づいた分析結果を提示したり、承認フローに関する照会に応じたりすることも可能です。ただし、会計データは機密性が極めて高いため、厳重なセキュリティ対策と、AIが参照するデータの範囲を明確に定義することが不可欠です。
医療系データ分析領域でのAI照会窓口
医療分野では、膨大な症例データ、最新の研究論文、診療ガイドライン、薬剤情報などが常に更新されています。AI照会窓口は、これらの情報を統合的に学習し、医師や研究者からの専門的な問い合わせに対して、迅速かつ正確な情報を提供することが期待されます。例えば、「特定の疾患の最新治療プロトコルは?」、「ある薬剤の副作用に関する最新の論文は?」といった質問に、AIが関連情報を提示することで、診断支援や治療方針の決定をサポートできます。
医療データは個人のプライバシーに深く関わるため、匿名化処理の徹底、医療情報システムの厳格なセキュリティ基準への準拠、そしてAIの回答が最終的な医療判断を代替するものではないという明確な位置づけが重要です。私たちは、これらの専門領域におけるAI活用の潜在能力を最大限に引き出しつつ、倫理的・法的な側面にも細心の注意を払ったシステム設計を支援します。
まとめ:AIを賢く活用し、企業のDXを加速させるために
AIは「万能の情報源」ではなく「強力なアシスタント」
本記事を通じて、私たちは一貫して「AIを情報源として盲信せず、照会窓口として賢く設計する」ことの重要性を強調してきました。現代のAI、特に生成AIは、その進化のスピードと多機能性ゆえに、あたかも「何でも知っている万能な存在」と捉えられがちです。しかし、その本質は「確率に基づき最適な出力を生成するツール」であり、常に正しい情報を保証するものではありません。
貴社がAIを社内活用する上で最も重要なのは、このAIの特性を深く理解し、その役割を「情報収集・整理・要約・下書き作成」といった強力なアシスタントとして位置づけることです。AIは、膨大な社内データや公開情報を瞬時に検索し、関連性の高い情報を抽出し、要点をまとめて提示する能力に長けています。これにより、従業員は情報探索にかかる時間を大幅に削減し、より付加価値の高い業務、例えば戦略立案や顧客との対話、創造的な問題解決に集中できるようになります。
一方で、AIには「ハルシネーション(幻覚)」と呼ばれる誤情報の生成リスクや、最新の非公開情報へのアクセス制限、倫理的・道徳的判断の欠如といった限界も存在します。そのため、AIが提供した情報は必ず人間がファクトチェックを行い、最終的な判断や意思決定は人間の責任で行うという原則を確立することが不可欠です。AIを「情報源」としてではなく「信頼できる照会窓口」として設計し、その回答を「参考情報」と位置づけることで、これらのリスクを最小限に抑え、安全かつ効果的な運用が可能になります。
社内でのAI活用を成功させるためには、単にツールを導入するだけでなく、その「AIインフラ」を適切に構築し、従業員が複数のAIモデルを統合的に活用できる「AIエージェント」のようなプラットフォームを提供することも有効です(出典:知乎「AI Infraとは何か」)。これにより、貴社はAIの恩恵を最大限に享受しつつ、その潜在的なリスクを管理できるようになります。
以下の表は、AIを「アシスタント」として捉えた場合の得意分野と、情報源として注意すべき限界をまとめたものです。
| AIの得意なこと(強力なアシスタントとして) | AIの苦手なこと(情報源として注意すべき点) |
|---|---|
| 既存データの高速検索と要約 | リアルタイムな最新情報の収集(特に非公開情報) |
| 定型的な問い合わせへの即時回答 | 未知の状況や複雑な感情を伴う判断 |
| 多言語対応、翻訳 | 倫理的・道徳的な判断、法的解釈 |
| データに基づくパターン認識と予測 | ハルシネーション(誤情報の生成)の完全排除 |
| 報告書や資料の下書き作成、アイデア出し | 深い専門知識を要するクリティカルな意思決定 |
| 複数情報源からの情報整理と統合 | 未知の事象に対する創造的な問題解決やイノベーション |
| コード生成やデバッグ支援(出典:バイトダンス「AI IDE Trae」) | 100%正確なプログラミング(出典:知乎「マクスウェル預言」) |
Aurant Technologiesが伴走するDX推進
AIの社内活用は、単なるツール導入に留まらず、貴社の業務プロセス、組織文化、そして従業員の働き方そのものに変革をもたらすDX(デジタルトランスフォーメーション)の一環です。私たちAurant Technologiesは、BtoB企業のDX・業務効率化・マーケティング施策において、実務経験に基づいた具体的な助言と伴走型の支援を提供しています。
貴社がAIを照会窓口として社内活用するにあたり、以下のような課題に直面しているかもしれません。
- どのAIツールを選べば良いかわからない。
- 社内データを安全にAIに学習させる方法がわからない。
- ハルシネーションリスクを最小限に抑える運用ルールを策定したい。
- 従業員がAIを効果的に使いこなせるようなトレーニングが必要。
- 既存システムとの連携や、AIインフラの構築方法に課題がある。
- 複数のAIモデルを統合して利用できるプラットフォームを構築したい(出典:知乎「AI大模型聚合平台」)。
私たちAurant Technologiesは、これらの課題に対し、貴社のビジネスモデルや既存システム、組織体制を深く理解した上で、最適なAI活用戦略の策定から実行までを一貫してサポートします。
具体的な支援内容は多岐にわたります。例えば、
- 戦略策定とロードマップ作成: 貴社の目標と現状を分析し、AI活用の具体的な目的、導入フェーズ、期待効果を明確にします。
- システム選定・導入支援: 市場に存在する多数のAIツールやプラットフォームの中から、貴社に最適なものを比較検討し、導入をサポートします。
- データガバナンス構築: 社内データのプライバシー保護、セキュリティ対策、AI学習への活用方法に関するポリシー策定を支援します。
- 運用設計とルール策定: AIのハルシネーション対策、ファクトチェック体制、利用ガイドラインなど、安全かつ効果的な運用フローを構築します。
- 従業員トレーニングと定着支援: AIツールの使い方だけでなく、AIとの協業における考え方、プロンプトエンジニアリングの基礎などをレクチャーし、従業員のAIリテラシー向上を支援します。
- 効果測定と改善: 導入後の効果を定量的に測定し、継続的な改善サイクルを回すための仕組みを構築します。
AIは、正しく活用すれば貴社の生産性を飛躍的に向上させ、競争優位性を確立する強力な武器となります。しかし、その導入と運用には専門的な知識と経験が必要です。私たちAurant Technologiesは、貴社がAI活用のメリットを最大限に享受し、同時にリスクを適切に管理できるよう、実務経験に基づいた確かなノウハウで伴走いたします。
AIを活用したDX推進にご興味がございましたら、ぜひ一度私たちにご相談ください。貴社の具体的な課題や目標をお聞かせいただき、最適なソリューションをご提案させていただきます。