BigQuery 大規模データ分析基盤 構築ガイド 2026:5ステップ・FinOps最適化・課金モデル選定
BigQueryを活用した大規模データ分析基盤の構築手順、ビジネス価値、費用最適化の具体的なコツを解説。データドリブン経営への移行を支援します。
目次 クリックで開く
BigQueryで実現する大規模データ分析基盤:構築手順と費用最適化のプロ実践ガイド
ペタバイト級のデータをビジネスの武器へ。BigQueryを中心としたモダンデータスタックの構築から、AI連携、コストマネジメントまでを徹底解説します。
BigQueryがモダンデータ分析基盤の「核」となる理由
現代のエンタープライズにおいて、データは単なる記録ではなく、意思決定を支える「燃料」です。特にBtoBビジネスでは、複雑な顧客接点やSaaS由来の断片化したデータを統合する能力が、そのまま競争力に直結します。
Google CloudのBigQueryは、単なるストレージではありません。サーバーレス、スケーラビリティ、そして強力なSQLエンジンを兼ね備えた「分析プラットフォーム」です。インフラ管理から解放され、ビジネスインサイトの抽出にリソースを集中できる点が、従来のオンプレミス型DWHとの決定的な違いです。
フルマネージドが生む「運用ゼロ」の衝撃
BigQueryは計算リソースとストレージを完全に分離したアーキテクチャを採用しています。これにより、ペタバイト級のデータに対しても、事前のプロビジョニングなしで数秒のクエリレスポンスを実現します。また、AI/MLとの親和性も高く、SQLだけで機械学習モデルを構築できるBigQuery MLは、データサイエンスの民主化を加速させます。
💡 関連リソース: 高額なCDPを導入せずとも、BigQueryを中心に据えることで理想的なデータ基盤は構築可能です。
高額なCDPは不要?BigQuery・dbt・リバースETLで構築する「モダンデータスタック」解説
データ分析基盤構築の5ステップ:実務者向けワークフロー
1. データソースの特定とインジェスト設計
まずは、社内に点在するデータソース(CRM、ERP、広告、SaaSログなど)を特定します。BigQueryへのデータ取り込みには、用途に応じて「バッチ」と「ストリーミング」を使い分けます。
- バッチ処理: 日次・週次での一括連携(Cloud Storage経由など)
- ストリーミング: リアルタイム性が求められるイベントデータ(Pub/Sub経由など)
2. パフォーマンスを左右するスキーマ設計
BigQueryの課金と速度を最適化する鍵は、パーティショニングとクラスタリングにあります。
| 機能 | 概要 | メリット |
|---|---|---|
| パーティショニング | 日付等の特定の列でデータを物理的に分割 | スキャン範囲の限定によるコスト削減 |
| クラスタリング | 特定の列でデータをソートして保持 | フィルタリングや結合の高速化 |
3. ELTパイプラインの構築(dbtの活用)
生データをロードした後は、BigQuery内で変換を行うELT(Extract, Load, Transform)が主流です。ここでdbt (data build tool)を活用することで、SQLによるデータ変換のバージョン管理とドキュメント化が可能になり、信頼性の高いデータモデリングが実現します。
💡 関連リソース: データの変換・統合プロセスにおいて最適なツール選定は不可欠です。
【アーキテクチャ解説】ETL/ELTツール選定の実践。Fivetran、trocco、dbtの比較
4. AI/ML連携による「予測型」分析への昇華
BigQueryに蓄積されたデータは、そのままBigQuery MLを通じて予測モデルに投入できます。例えば、広告の自動最適化を目的とする場合、BigQueryでの分析結果をAPI経由で各プラットフォームへフィードバックする構成が極めて有効です。
💡 関連リソース: 分析結果を広告配信の最適化に直結させる高度な活用例はこちら。
広告×AIの真価を引き出す。CAPIとBigQueryで構築する「自動最適化」データアーキテクチャ
5. BIツールによる可視化と意思決定
最終的に、LookerやLooker StudioなどのBIツールと連携させ、経営層や現場が直感的に判断できるダッシュボードを構築します。BigQueryの高速なクエリ性能により、ドリルダウンもストレスなく行えます。
費用最適化(FinOps)のプロテクニック
「BigQueryは高い」という誤解は、多くの場合、不適切なクエリ設計から生じます。以下のベストプラクティスを遵守することで、コストを劇的に抑えることが可能です。
- SELECT * を避ける: 必要なカラムのみを指定し、スキャン量を削減する。
- クエリプレビューの活用: 実行前にスキャン予定量を確認する癖をつける。
- 長期保存割引の利用: 90日間更新のないテーブルは、ストレージ料金が自動的に約50%割引されます。
- スロット定額制の検討: クエリ実行量が多い企業は、従量課金から定額制(Editions)への切り替えでコストを安定化できます。
まとめ:データ基盤は「作って終わり」ではない
BigQueryを中心としたデータ分析基盤は、構築がゴールではありません。ビジネスの変化に合わせてデータモデルを洗練させ、現場のフィードバックを反映し続ける「継続的な改善」が、真のROIを生みます。
Aurant Technologiesでは、BigQueryの導入から、dbtを用いた高度なデータモデリング、そしてAIを活用したビジネスオートメーションまで、企業のデータ活用を全方位で支援しています。データ基盤の構築や見直しをご検討の際は、ぜひご相談ください。
実務導入前に抑えるべき「3つの技術的境界線」
BigQueryの構築において、エンジニアやプロジェクトマネージャーが初期段階で判断を誤りやすいポイントを整理します。特に「料金プランの選択」と「権限設計」は、後からの変更が運用コストに大きく響くエリアです。
1. 「Editions」選択の判断基準
2023年の料金改定以降、BigQueryは「Standard」「Enterprise」「Enterprise Plus」の3つのエディション制へ移行しました。従来の定額料金制(Flat-rate)は廃止され、現在はスロットのオートスケーリングが基本となっています。高度なセキュリティ(VPC Service Controls等)や、機械学習(BigQuery ML)の高度な機能が必要な場合は、Enterprise以上の選択が必須となります。
2. 権限管理(IAM)とデータガバナンス
「とりあえず管理者権限で運用する」のはB2B実務では禁物です。BigQueryでは、データセット単位だけでなく、列単位(カラムレベルのセキュリティ)や、条件に応じた行単位でのアクセス制御が可能です。個人情報や売上原価など、閲覧者を限定すべきデータに対しては、構築初期からポリシーを定義しておくべきです。
3. BigQuery Omniによるマルチクラウド戦略
AWSのS3やAzureのBlob Storageにデータが点在している場合、データをGoogle Cloudに移動(エクスポート)せずにクエリを実行できる「BigQuery Omni」という選択肢があります。データ転送コストと鮮度のトレードオフを解消する強力な手段です。
【比較表】ワークロード別・最適な課金モデルの選び方
現在のBigQueryは、予測不可能な分析には「オンデマンド」、安定した大規模処理には「Editions(スロット予約)」を使い分けるのが鉄則です。
| 項目 | オンデマンド(従量課金) | BigQuery Editions(予約/容量制) |
|---|---|---|
| 課金対象 | クエリでスキャンされたデータ量 | 使用した計算リソース(スロット時間) |
| 主な用途 | 不定期な分析、開発・検証環境 | 定常的なバッチ処理、大規模なBI利用 |
| コスト管理 | クエリごとに変動(予測が困難) | 上限設定が可能(予算管理が容易) |
| 公式ドキュメント | BigQuery の料金(Google Cloud 公式) | |
- 利用するリージョンは決定しているか(東京リージョン
asia-northeast1等、リージョンにより料金が異なる) - データセットに適切な「デフォルトのテーブル有効期限」を設定しているか(不要データの蓄積防止)
- 既存のSaaSデータとの連携に、追加のETLツール費用が発生しないか
💡 あわせて読みたい: データ基盤を構築した後の「攻め」の活用として、LINEなどのチャネルと連携したリアルタイムな施策実行が注目されています。
高額MAツールは不要。BigQueryとリバースETLで構築する「行動トリガー型LINE配信」の完全アーキテクチャ
BigQueryのポテンシャルを最大限に引き出すには、エンジニアリングの知識だけでなく、会計的なコスト感覚(FinOps)と、ビジネス現場のニーズを繋ぐアーキテクチャ設計が欠かせません。基盤の最適化についてご不明点があれば、各社の最新仕様をご確認の上、専門家への相談もご検討ください。
📚 関連資料
このトピックについて、より詳しく学びたい方は以下の無料資料をご参照ください:
データ分析・予実可視化とダッシュボード構築のご相談
散在するデータの集約から、予実管理やKPIをひと目で追えるダッシュボードの構築までを支援します。何をどの指標で見える化すべきかという設計段階から、貴社の状況に合わせてご一緒します。
BigQuery 費用最適化 5鉄則
- SELECT * 禁止:必要列のみ指定でスキャン量を10分の1へ
- パーティション/クラスタリング:日付・カテゴリで物理分割
- Materialized View:頻繁参照クエリを事前計算
- BI Engine:BIから接続するテーブルにキャッシュ層
- Reservation購入:常時ワークロードがあるならスロット購入
月額予算別 推奨利用パターン
| 月額予算 | 推奨設定 | 想定データ量 |
|---|---|---|
| 〜5,000円 | オンデマンド + Sheets連携 | 〜1GB / 月数百クエリ |
| 1〜3万円 | + BI Engine | 〜10GB / 日次BI更新 |
| 5〜15万円 | + Materialized View + dbt | 〜100GB / 全社展開 |
| 30万円〜 | スロット予約 + Streaming Insert | TB級・リアルタイム要件 |
FAQ
- Q1. 想定外のコスト爆発を防ぐには?
- A. 「Quota設定 + Cost Alerts + Cloud Monitoring」の3点を必ず設定。
- Q2. dbt は本当に必要?
- A. テーブル数20超 / モデル化必要なら必須。詳細は 顧客データ分析の最終稿。
関連記事
- 【BigQuery vs Snowflake】(ID 244)
- 【DWH構築実践ガイド】(ID 276)
- 【BigQuery×BI連携】(ID 243)
- 【BigQuery広告ROAS改善】(ID 242)
※ 2026年5月時点の市場動向を反映。
レガシーシステム刷新・モダナイゼーションの関連完全ガイド
本記事のテーマに関連する旧基幹/旧SaaSからのモダナイゼーション完全ガイド一覧です。移行戦略・選定軸の参考にどうぞ。
- 【完全ガイド】大塚商会 SMILE V 2nd Edition から他社ERPへの乗り換え:NetSuite・SAP・Dynamics 365・kintoneを比較
- 【完全ガイド】Microsoft Access から kintone への移行:データ移行・VBA資産の扱い・Power Apps との比較
- 【完全ガイド】AS/400 (IBM i) モダナイゼーション戦略 2026:4つの選択肢とクラウドERP移行先を徹底比較
- 【完全ガイド】富士通 GLOVIA から他社ERPへの移行:SAP S/4HANA・Oracle Fusion・Dynamics 365・NetSuite・Inforを徹底比較
- 【完全ガイド】弥生会計 デスクトップ版 から クラウド会計への移行:弥生会計オンライン・freee 会計・MFクラウド会計を徹底比較
- 【完全ガイド】Notes/Domino から Microsoft 365・kintone への移行戦略 2026:業務DB別の置き換えパターンとリプレース実務
- 【完全ガイド】SuperStream-NX から SuperStream-CLOUD・SAP S/4HANA・Workday・NetSuite への移行戦略
- 【完全ガイド】COMPANY から SmartHR・Workday・SAP SuccessFactors への移行戦略:大企業HR刷新の選定軸
- 【完全ガイド】eセールスマネージャー Remix から Salesforce・HubSpot・kintone・Zoho CRM への移行戦略
- 【完全ガイド】mcframe 7 から mcframe XA・SAP S/4HANA・Oracle Fusion・Infor CloudSuite への移行戦略
- 【完全ガイド】リコー文書管理システム から Box・Microsoft 365・kintone・Google Workspace への移行戦略
- 【完全ガイド】大塚商会 たよれーる契約の見直し:継続・部分内製化・完全切替の判断軸とコスト最適化
- 【完全ガイド】Oracle EBS / JD Edwards から Oracle Fusion Cloud Applications への移行戦略
- 【完全ガイド】Microsoft Dynamics 旧版(AX/GP/NAV/SL)から Dynamics 365 への移行戦略
- 【完全ガイド】desknet’s NEO・サイボウズ Office・Garoon オンプレ から クラウド型グループウェアへの移行戦略
- 【完全ガイド】NEC ACOS・富士通 GS21・日立 VOS3・IBM z/OS メインフレーム モダナイゼーション戦略
- 【完全ガイド】Pardot から Salesforce Marketing Cloud Account Engagement (MCAE) への移行:継続 vs HubSpot/Marketo 乗り換えの判断軸
- 【完全ガイド】Sansan の見直し:HubSpot・Salesforce・kintone+AI OCR・Microsoft 365 への乗り換え判断
- 【完全ガイド】旧世代CRM (SugarCRM・vTiger・Dynamics CRM旧版・Notes/Domino) からモダンCRMへの移行戦略
関連ピラー:【ピラー】データガバナンス完全ガイド:データカタログ・メタデータ管理・品質モニタリング・アクセス権限の統合設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】LINE × 業務システム統合 完全ガイド:LINE公式アカウント / LINE WORKS / LIFF / Messaging API の使い分けと CRM 連携設計
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】BigQuery/モダンデータスタック完全ガイド:dbt・Hightouch・Looker・BIエンジンの統合設計とコスト最適化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
関連ピラー:【ピラー】広告運用統合 完全ガイド:Google/Meta/LINE/TikTok の CAPI 設計と BigQuery 統合分析でROAS最大化
本記事のテーマを上位概念から体系的に学ぶには、こちらのピラーガイドをご覧ください。
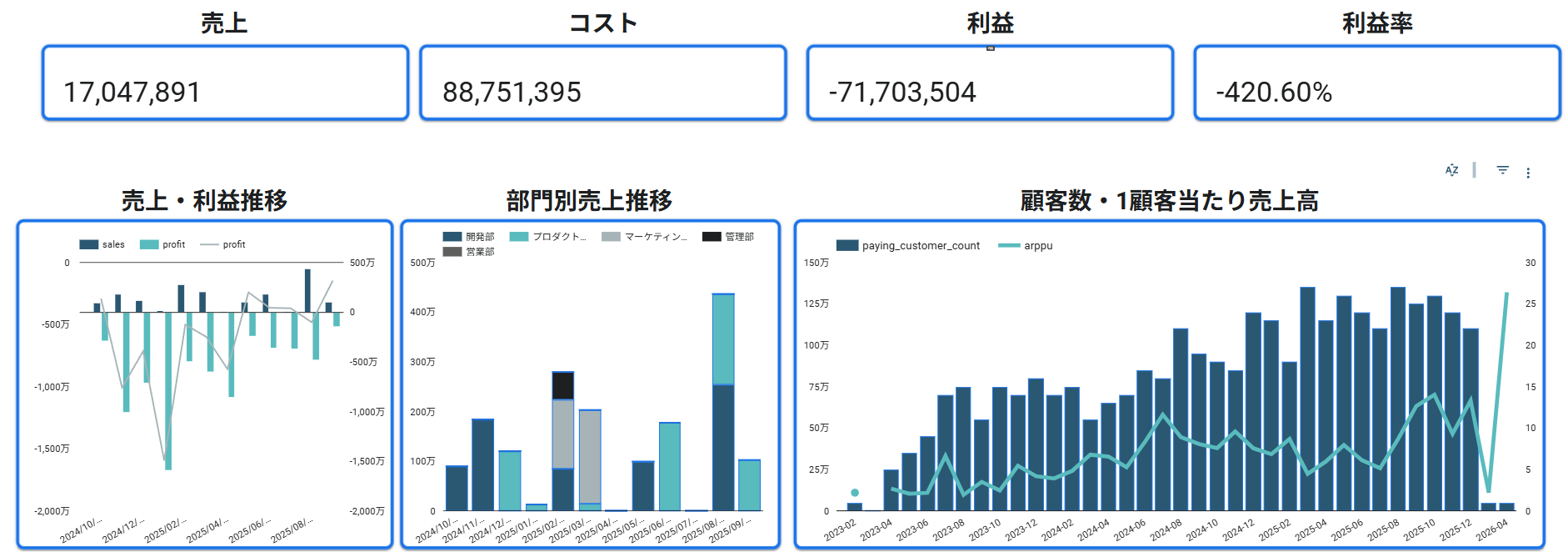
参考:Aurant Technologies 実プロジェクトのLooker Studio実装
本記事のテーマを実装段階まで進める際の参考として、Aurant Technologies が支援した複数の実案件で構築した Looker Studio ダッシュボードの一例をご紹介します。数値・社名・部門名はマスキングしていますが、実際に運用されている可視化です。
CRM・営業支援
Salesforce・HubSpot・kintoneの選定から導入・カスタマイズ・定着まで一貫対応。営業生産性を高め、商談化率を改善します。




